
1. Введение в службы каталогов OpenLDAP
Эта документация рассказывает о том, как собрать, настроить и эксплуатировать программное обеспечение OpenLDAP для организации службы каталогов. В ней детально описаны конфигурирование и запуск автономного демона
1.1. Что такое служба каталогов?
Каталог — это специализированная база данных, предназначенная для поиска и просмотра информации, а также поддерживающая наполнение данными и их обновление в качестве дополнительных функций.
Замечание: Некоторые называют каталог просто базой данных, оптимизированной для запросов на чтение. Это определение, в лучшем случае, чрезмерно упрощено.
Каталоги имеют тенденцию содержать описательную информацию, основанную на атрибутах, и поддерживать сложные способы фильтрации. Каталоги обычно не поддерживают механизмы транзакций и откатов (roll-back), применяемые в СУБД, ориентированных на комплексные обновления большого объема данных. Обновления в каталогах (если они вообще разрешены), обычно происходят по простой схеме: "изменить всё или ничего". Каталоги обычно оптимизируются на скорейшую выдачу результата при поиске среди больших объемов информации. Они также могут иметь возможность репликации информации, то есть создания удалённых копий каталога с целью повышения доступности информации, надёжности её хранения и снижения времени отклика. В процессе репликации, до полного её окончания, допустимо временное рассогласование информации между репликами.
Существует много методов организации службы каталогов. Различия могут касаться типов информации, хранимой в каталоге, выдвижения различных требований к обращению и обновлению этой информации, ссылкам на неё, организации системы разграничения доступа к информации, и т. д. Некоторые службы каталогов могут быть локальными, предоставляющими услуги в ограниченном контексте (например, для службы finger на отдельностоящей машине). Другие службы глобальны, предоставляют услуги в гораздо более широком контексте (например, всему Internet). Глобальные службы обычно являются распределенными. Это означает, что содержащаяся в них информация распределена между многими компьютерами, взаимодействующими друг с другом для предоставления услуг службы каталогов. Обычно глобальная служба каталогов определяет унифицированное пространство имён, чтобы пользователь получал одинаковый результат независимо от того, откуда он производит запрос и к какому серверу службы обращается.
Веб-каталог, такой как Open Directory Project <http://dmoz.org>, — хороший пример службы каталогов. Эта служба каталогизирует веб-страницы и специально разработана для просмотра и поиска.
Некоторые приводят
1.2. Что такое LDAP?
Данный подраздел дает некоторое представление о LDAP с точки зрения пользователя.
Какого рода информация может храниться в каталоге? Информационная модель LDAP основана на записях (entry). Запись — это коллекция атрибутов (attribute), обладающая
Как организовано размещение информации? Записи каталога LDAP выстраиваются в виде иерархической древовидной структуры. Традиционно, эта структура отражает географическое и/или организационное устройство хранимых данных. В вершине дерева располагаются записи, представляющие собой страны. Под ними располагаются записи, представляющие области стран и организации. Еще ниже располагаются записи, отражающие подразделения организаций, людей, принтеры, документы, или просто всё то, что Вы захотите включить в каталог. На рисунке 1.1 показан пример дерева каталога LDAP, использующего традиционное именование записей.
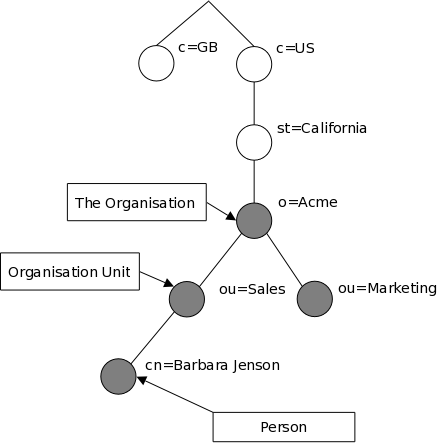
Рисунок 1.1: Дерево каталога LDAP (традиционное именование записей)
Построение дерева может быть также основано на доменных именах Internet. Этот подход к именованию записей становится всё более популярным, поскольку позволяет обращаться к службам каталогов по аналогии с доменами DNS. На рисунке 1.2 показан пример дерева каталога LDAP, использующего именование записей на основе доменов.
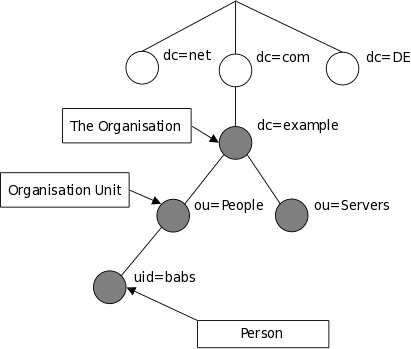
Рисунок 1.2: Дерево каталога LDAP (Internet-именование записей)
Кроме того, LDAP, посредством специального атрибута objectClass, позволяет контролировать, какие атрибуты обязательны и какие допустимы в той или иной записи. Значения атрибута objectClass определяются правилами схемы (schema), которым должны подчиняться записи.
Как можно обратиться к информации? К записи обращаются по ее уникальному имени, которое состоит из собственно имени записи (так называемое относительное уникальное имя (
Какие манипуляции можно произвести с информацией? В LDAP определены операции для опроса и обновления каталога. К числу последних относятся операции добавления и удаления записи из каталога, изменения существующей записи и изменения названия записи. Однако, большую часть времени LDAP используется для поиска информации в каталоге. Операции поиска LDAP позволяют производить поиск записей в определённой части каталога по различным критериям, заданным поисковыми фильтрами. У каждой записи, найденной в соответствии с критериями, может быть запрошена информация, содержащаяся в её атрибутах.
К примеру, Вам захотелось найти записи о человеке по имени Barbara Jensen во всем подкаталоге, начиная с уровня dc=example,dc=com и ниже, и получить адрес электронной почты в каждой найденной записи. LDAP позволяет Вам легко это сделать. Или Вам хочется поискать непосредственно на уровне st=California,c=US записи организаций, названия которых содержат строку Acme и имеющих номер факса. Такой поиск LDAP тоже позволяет сделать. В следующем подразделе более подробно описано, что Вы можете сделать с LDAP и чем он может быть Вам полезен.
Как информация защищена от несанкционированного доступа? Некоторые службы каталогов не предоставляют никакой защиты, позволяя любому просматривать хранящуюся в них информацию. Однако LDAP предоставляет механизмы для аутентификации клиента, либо других способов доказательства его подлинности серверу каталогов, а также богатые возможности контроля доступа к информации, содержащейся на этом сервере. LDAP также обеспечивает защиту информации в каталоге (её целостность и конфиденциальность).
1.3. Для чего можно использовать LDAP?
Очень хороший вопрос. В общем случае, службу каталогов можно использовать, когда Вам требуется надёжное хранение информации с возможностью централизованного управления и доступа к ней, с использованием стандартизированных методов.
Вот ряд (но, конечно, не полный) самых распространённых примеров промышленного использования служб каталогов:
- Идентификация компьютеров
- Аутентификация пользователей
- Группировка пользователей (в том числе системные группы)
- Адресные книги
- Представление штатно-кадровой структуры организации
- Учет закрепления имущества организации за сотрудниками
- Телефонные справочники
- Управление пользовательскими ресурсами
- Справочники адресов электронной почты
- Хранение конфигурации приложений
- Хранение конфигурации АТС
- и т.д. ...
Для организации каталога под столь разные задачи существуют различные, основанные на стандартах файлы наборов схемы, распространяемые с дистрибутивом. Также Вы можете создать свою собственную спецификацию схемы для решения Вашей задачи.
Всегда найдутся новые способы использования каталогов и применения принципов LDAP для решения различных проблем, поэтому не существует простого ответа на вопрос этого подраздела.
Если есть сомнения, присоединяйтесь к общему форуму для некоммерческих обсуждений и информации, относящейся к LDAP по адресу: http://www.umich.edu/~dirsvcs/ldap/mailinglist.html и спрашивайте.
1.4. Для чего LDAP лучше не использовать?
Если Вы чувствуете, что нужно исхитриться, чтобы заставить каталог делать то, что Вам требуется, то, возможно, стоит поискать альтернативные способы решения задачи. Или, возможно, найдутся более подходящие средства, если Вам всего-лишь нужно приложение для манипуляций и использования собственной информации (о противопоставлении LDAP и реляционных СУБД можно почитать в подразделе Непростые взаимоотношения LDAP и реляционных СУБД).
Чаще всего очевидно, в каких случаях LDAP — верный способ решения Вашей задачи.
1.5. Как работает LDAP?
LDAP использует клиент-серверную модель. Один или несколько серверов LDAP содержат информацию, образующую информационное дерево каталога (directory information tree,
1.6. Как насчёт X.500?
Технически,
Хотя LDAP по-прежнему используется для доступа к службе каталогов X.500 через шлюзы, сейчас он чаще непосредственно встраивается в программное обеспечение серверов X.500.
Автономный демон LDAP, или slapd(8), можно рассматривать как легковесный сервер службы каталогов X.500. Он не реализует X.500 DAP и не поддерживает полные информационные модели X.500.
Если Вы уже используете службу X.500 и DAP и планируете продолжать, Вам, скорее всего, можно не читать это руководство дальше, поскольку оно целиком посвящено работе LDAP с использованием slapd(8), без запуска X.500 DAP. Если Вы не используете X.500 DAP, собираетесь прекратить его использовать, либо думаете, стоит ли запускать X.500 DAP, читайте дальше.
Существует возможность переноса данных из службы каталогов LDAP в X.500 DAP
1.7. В чём отличие между LDAPv2 и LDAPv3?
LDAPv3 был разработан в конце 90-х годов для замены LDAPv2. LDAPv3 добавил в LDAP следующие возможности:
- Строгая аутентификация и сервисы безопасности данных с помощью
SASL - Аутентификация с использованием сертификатов и сервисы безопасности данных с помощью
TLS (SSL) - Интернационализация посредством использования Unicode
- Поддержка ссылок и продолжений
- Развёртывание в соответствии со схемой данных
- Расширяемость (средствами контроля, дополнительными операциями, и другими возможностями)
Сейчас LDAPv2 является историческим (RFC3494). Поскольку большинство так называемых реализаций LDAPv2 (в том числе slapd(8)) не соответствуют техническим спецификациям LDAPv2, совместимость между такими реализациями, декларирующими поддержку LDAPv2, ограничена. Так как LDAPv2 существенно отличается от LDAPv3, поддержка работоспособности одновременно и LDAPv2 и LDAPv3 весьма проблематична. Следует избегать использования LDAPv2, по умолчанию он отключен.
1.8. Непростые взаимоотношения LDAP и реляционных СУБД
Этот вопрос поднимался много раз в различных формах. Однако, чаще всего в такой: Почему бы OpenLDAP не перейти к использованию полноценной реляционной системы управления базами данных (СУБД) вместо встроенного хранилища ключей/значений вроде LMDB? Такой переход мог бы сделать OpenLDAP быстрее или дать другие преимущества за счет используемых в СУБД коммерческого класса сложных алгоритмов, и, с другой стороны, дал бы возможность другим приложениям работать с теми же данными непосредственно из БД.
Если ответить коротко, использование встроенной базы данных и простой системы индексирования позволяет OpenLDAP обеспечивать высокую производительность и масштабируемость без потери надёжности. OpenLDAP использует многопользовательскую СУБД
Теперь попробуем ответить на вопрос более развёрнуто. Все мы постоянно сталкиваемся с выбором между реляционными СУБД и каталогами. Это нелёгкий выбор, и простого ответа тут не существует.
Кажется, что использование в качестве хранилища каталога реляционной СУБД решит все подобные проблемы. Но тут кроется подвох. Всё дело в том, что информационные модели каталога и реляционной БД очень разные. Попытка проецирования данных каталога в реляционную БД потребует разделения данных на несколько таблиц.
Возьмём, к примеру, объектный класс person. В нём определены обязательные типы атрибутов objectClass, sn и cn, а также необязательные типы атрибутов userPassword, telephoneNumber, seeAlso и description. Все эти атрибуты могут иметь несколько значений, таким образом нормализация потребует поместить каждый тип атрибута в отдельную таблицу.
Теперь нужно подумать о ключевых полях для этих таблиц. В качестве первичного ключа может быть использован DN, но в большинстве реализаций баз данных это будет весьма неэффективно.
Еще одной большой проблемой может стать обращение к различным областям жесткого диска при поиске данных, представляющих одну и ту же запись каталога. Для одних приложений это не вызовет затруднений, но для большинства из них это обернётся потерей производительности.
В главную таблицу, хранящую сведения о записях каталога, могут быть помещены только данные из обязательных для объектного класса типов атрибутов, которые могут иметь только одно значение. Кроме того, туда можно поместить данные из необязательных атрибутов с одним значением, и записывать в такие поля NULL (или ещё что-нибудь), если атрибут не задан.
Однако, у записи каталога может быть несколько объектных классов, и они могут иерархически наследоваться один от другого. Запись объектного класса organizationalPerson будет иметь атрибуты объектного класса person плюс ряд дополнительных, к тому же некоторые ранее необязательные атрибуты могут стать обязательными.
Что же делать? Нужно ли заводить разные таблицы под разные объектные классы? В таком случае запись, описывающая человека, будет иметь одну строку в таблице person, еще одну в organizationalPerson, и т.д. Или не стоит ничего помещать в таблицу person а всё записывать только во вторую таблицу?
А что нам делать с фильтрами типа (cn=*), где cn — тип атрибута, который может использоваться в очень многих объектных классах? Придётся пройтись по всем таблицам, где можно встретить такой атрибут? Не очень привлекательно.
Когда наши рассуждения достигли данной точки, на ум приходят три подхода. Первый из них заключается в полной нормализации, то есть в помещении каждого типа атрибута, вне зависимости от того, какие данные в нём хранятся, в отдельную таблицу. В простейшем случае в качестве первичного ключа можно использовать DN, но это крайне расточительно, поэтому напрашивается присвоение записи уникального числового идентификатора, который в главной таблице будет сопоставляться DN, а потом использоваться в качестве в качестве внешнего ключа в подчиненных таблицах. Такой подход в любом случае будет неэффективным, когда потребуются данные сразу из нескольких атрибутов для одной или ряда записей каталога. Тем не менее, с такой базой данных можно работать из SQL-приложений.
Второй подход заключается в том, чтобы помещать целиком все данные о записи в одном blob-поле таблицы, в которой будут храниться все записи каталога, независимо от их объектных классов, и иметь дополнительные таблицы, содержащие индексы для первой. И это будут не индексы базы данных, а величины, применяемые для оптимизации поиска в конкретной реализации LDAP-сервера. Однако, подобные базы данных становятся непригодными для SQL-запросов. Таким образом, использование полноценной реляционной СУБД не обеспечивает практически никаких преимуществ, и потому бесполезно. Гораздо лучше использовать что-то более легковесное и быстрое, вроде
Наконец, совершенно отличный подход заключается в отказе от реализации полноценной модели данных каталога. В этом случае LDAP используется в качестве протокола доступа к данным, которые можно назвать каталогом лишь с ограничениями. К примеру, это может быть каталог в режиме "только для чтения", либо, если разрешены операции обновления, накладываются различные ограничения, такие как присвоение только одного значения атрибутам, которые в полноценной реализации могли бы иметь несколько значений. Либо отсутствие возможности добавить новый объектный класс к существующей записи, или убрать один из тех, которые у неё уже имеются. Диапазон ограничений может варьироваться от вполне безобидных (вроде тех, что налагаются в результате контроля доступа), до прямого нарушения модели данных, но за счет этого можно попытаться организовать LDAP-доступ к уже существующим данным, которые используются другими приложениями. И всё же надо понимать, что такую систему "каталогом" можно назвать с большой натяжкой.
В существующих коммерческих реализациях LDAP-серверов, использующих реляционные базы данных, применяется либо первый, либо третий подход. Всё же хотелось бы отметить, что ни в одной из них применение реляционной СУБД не позволило сделать работу эффективнее, чем при использовании BDB.
Для тех, кто заинтересовался "третьим путём" (представление СУЩЕСТВУЮЩИХ данных, хранящихся в реляционной СУБД, в виде LDAP-дерева, имеющее, с одной стороны, некоторые ограничения по сравнению с классической LDAP-моделью, а с другой стороны позволяющее организовать взаимодействие между LDAP и SQL-приложениями), есть хорошая новость. OpenLDAP включает в себя back-sql — механизм манипуляции данными, который делает это возможным. Он использует ODBC + дополнительную метаинформацию о трансляции LDAP-запросов в SQL-запросы в схему данных Вашей СУБД, организует различные уровни доступа от "только для чтения" до полного доступа, в зависимости от СУБД, которую Вы используете, и Вашей схемы данных.
За дополнительной информацией о принципах работы и ограничениях обращайтесь к man-странице slapd-sql(5) или к разделу Механизмы манипуляции данными. Есть также несколько примеров для разных СУБД в поддиректориях back-sql/rdbms_depend/* .
1.9. Что такое slapd и на что он способен?
slapd(8) — это сервер службы каталогов, работающий на очень многих платформах. Вы можете использовать его для организации службы каталогов и настройки её индивидуально под себя. Ваш каталог может хранить информацию практически обо всём, что Вам заблагорассудится. Вы можете подключить его к глобальной службе каталогов, или использовать только в своих интересах. Вот некоторые наиболее интересные возможности и особенности slapd:
LDAPv3: slapd реализует версию 3 протокола
Контроль доступа на основе сетевой топологии: slapd может быть настроен на запрещение доступа на уровне подключений на основе информации о топологии сети. Данная возможность основана на применении TCP wrappers.
Контроль доступа: slapd предоставляет богатые и мощные средства контроля доступа к информации в Ваших базах данных. Вы можете контролировать доступ к записям по аутентификационной информации LDAP,
Интернационализация: slapd поддерживает Unicode и языковые теги.
Выбор механизма манипуляции данными: slapd поставляется с набором различных механизмов манипуляции на Ваш выбор. Вот некоторые из них:
Применение нескольких хранилищ данных одновременно: slapd может быть настроен для работы с несколькими базами данных одновременно. Это означает, что один сервер slapd может обслуживать запросы к нескольким логически различным частям дерева LDAP, с использованием одинаковых или различных механизмов манипуляции данными.
Разнообразные API-модули: Если Вам требуется еще большая гибкость настроек, slapd позволяет Вам без труда написать собственные модули. slapd состоит из 2-х отдельных частей: интерфейс приёма запросов, обслуживающая общение с клиентами посредством протокола LDAP, и модули, выполняющие специфические задачи, такие как операции с базами данных. Поскольку эти 2 части взаимодействуют друг с другом через чётко определённый
Потоки: slapd поддерживает разделение на потоки для повышения производительности. Один многопоточный процесс slapd обслуживает все входящие запросы с использованием пула потоков. Это позволяет уменьшить нагрузку на систему, увеличивая тем самым производительность.
Репликация: slapd может быть сконфигурирован для выполнения фонового копирования данных каталога. Подобная схема репликации "один главный/несколько подчиненных серверов" имеет жизненно важное значение в больших высоко-загруженных системах, где один сервер slapd просто не в состоянии обеспечить необходимую доступность и надежность. В экстремально сложных системах с повышенными требованиями к безотказности возможно также использование схемы репликации "несколько главных серверов". В slapd включена поддержка LDAP Sync-репликации.
Прокси-кэширование: slapd может быть сконфигурирован в качестве кэширующего прокси-сервера LDAP.
Настраиваемость: slapd может быть очень гибко и разнообразно настраиваться посредством одного единственного конфигурационного файла, который позволяет Вам изменить всё, что Вам только захочется изменить. Опции конфигурации имеют разумные значения по умолчанию, чтобы максимально облегчить Ваш труд. Конфигурация также может быть произведена динамически посредством самого LDAP, что значительно повышает управляемость.


