 |
Перекомпиляция пакета с icq клиентом в Ubuntu/Debian и Fedora/RHEL/CentOS Linux |
[комментарии]
|
| | Рассмотрим внесение патча c исправлением на примере пакета licq в Ubuntu Linux.
Убедимся, что в /etc/apt/sources.list присутствует строчка:
deb-src http://archive.ubuntu.com/ubuntu/ intrepid main universe restricted multiverse
Обновляем список пакетов:
apt-get update
Загружаем файлы, необходимые для сборки пакета licq:
apt-get source licq
Устанавливаем окружение, необходимое для сборки пакетов:
apt-get install devscripts
apt-get install build-essential
apt-get install fakeroot
Сохраняем наш патч в licq-rus-login.patch
(ссылки на патчи с исправление проблемы коннекта icq можно найти здесь -
http://www.opennet.dev/opennews/art.shtml?num=19883)
Накладываем наш патч:
cd ./licq-1.3.6/src
cat ../../licq-rus-login.patch| patch -p0
cd ../..
Загружаем дополнительные пакеты с библиотеками и программами от которых зависит licq:
apt-get build-dep licq
Собираем пакет:
fakeroot apt-get -b source licq
Устанавливаем пакет:
dpkg -i licq_*.deb licq-plugin-gt*.deb
PS. Для Pingin собирать нужно libpurple0
----------------
Для Fedora Linux процесс пересборки будет выглядеть так:
Загружаем SRC-пакет licq:
wget http://mirror.yandex.ru/fedora/linux/releases/10/Everything/source/SRPMS/licq-1.3.5-4.fc10.src.rpm
Устанавливаем его:
rpm -ivh licq-1.3.5-4.fc10.src.rpm
Переходим в директорию /usr/src/redhat/SOURCES и копируем туда свой патч licq-rus-login.patch
Переходим в директорию /usr/src/redhat/SPECS/ и в файле licq.spec добавляем две строки:
...
Patch3: licq-rus-login.patch
...
%patch3 -p1 -b .licq-rus-login
Собираем пакет:
rpmbuild -ba licq.spec
Устанавливаем собранные пакеты:
cd /usr/src/redhat/RPMS/i386
rpm -Uvh --force licq-*
|
| |
 |
|
|
Атомарные обновления в OSTree (доп. ссылка 1) |
Автор: Stan
[комментарии]
|
| | Введение
Если вы администрируете больше одного сервера, вы наверняка встречали
классическую драму: "обновили пакеты - и стало иначе".
Вроде бы обновление - рутинная операция, но на практике это часто лотерея из
мелких изменений: уехали зависимости, поменялись версии библиотек, подтянулись
новые настройки по умолчанию в файлах конфигурации, где-то пересобралось ядро,
а вишенкой сверху стало то, что два "одинаковых" узла после одинаковых команд
через пару недель оказываются уже не совсем одинаковыми.
Главная проблема не в том, что пакетные менеджеры плохие. Проблема в том, что
модель "обновление = набор независимых изменений" плохо сочетается с
требованиями инфраструктуры: предсказуемостью, быстрым восстановлением и
возможностью чётко ответить на вопрос: какая именно версия системы сейчас работает.
OSTree предлагает другой вариант: система поставляется как версия (коммит) и
переключается целиком. Не "вот вам 200 пакетов, удачи", а "вот вам собранное
состояние базовой системы, которое можно развернуть, загрузить и при
необходимости откатить".
Эта часть статьи - обзорная: без глубокой внутренней анатомии, но с теми
понятиями, которые реально нужны, чтобы решить, стоит ли вам это встраивать в
процесс. Практика на примере НАЙС.ОС будет во 2-3 части.
Что такое OSTree и в чём "атомарность"
OSTree - это механизм хранения и доставки "снимков" файловой системы (точнее,
базовой части системы) в виде коммитов. Коммит - это зафиксированное состояние
дерева файлов, которое можно получить из репозитория и развернуть на узле.
В OSTree есть несколько базовых сущностей, и их полезно выучить один раз:
Коммит - это версия системы, Ref - это "ветка/канал", которая указывает на
коммит. Например, ref может обозначать "НАЙС.ОС 5.2 minimal для x86_64". Remote
- это источник, откуда узел получает refs и коммиты (сервер/репозиторий,
опубликованный по сети). Администратор обычно работает не с "хешами коммитов",
а с ref. Ref - это человеческий контракт: стабильный идентификатор канала поставки.
Суть атомарности проявляется в терминах "deploy" и "rollback".
Deploy - это развёртывание выбранного коммита в sysroot так, чтобы система
могла загрузиться в этой версии. При deploy новая версия раскладывается как
отдельная, не разрушая текущую рабочую версию "в процессе".
Rollback - это откат на предыдущий deploy. Важно, что откат здесь - не
"откатываем 17 пакетов и надеемся", а переключаемся на ранее развёрнутую версию
системы. Поэтому rollback может быть быстрым и предсказуемым.
Отсюда и типичная фраза "две версии рядом": текущая рабочая и новая
подготовленная. Это нормальная и полезная конструкция: она позволяет
обновляться без превращения узла в полу-состояние "половина старого / половина нового".
В OSTree-модели существует sysroot - место, где живут:
* данные OSTree (репозиторий, метаданные),
* развёрнутые деплои,
* элементы, необходимые для загрузки.
На практике администратору достаточно понимать "где искать правду", когда что-то пошло не так:
* в sysroot живёт структура OSTree;
* в /boot/loader обычно находятся записи загрузки (entries), которые соответствуют деплоям.
Это не руководство по ремонту загрузчика - это ориентиры, чтобы не искать проблему "в воздухе".
OSTree отвечает за "версионирование и доставку состояния".
Но откуда берутся эти состояния (коммиты)?
Если базовый мир у вас RPM, то роль сборщика выполняет "rpm-ostree". Он берёт
декларацию состава системы (treefile, обычно JSON), тянет пакеты из указанных
репозиториев, собирает файловое дерево и коммитит результат в OSTree-репозиторий.
Treefile - это ключ к дисциплине: вы не обновляете систему "как получится", вы
выпускаете версию по описанию "как должно быть".
Чем OSTree отличается от "обычных обновлений"
Классическая модель: много пакетов, много зависимостей, много вариантов результата.
Обычный пакетный апдейт - это операция над множеством объектов. Даже если
команда одна, фактически вы получаете:
* разные комбинации зависимостей в зависимости от времени,
* разные обновления в разных репозиториях,
* разные настройки по умолчанию в конфигурации,
* и самое неприятное - разные результаты на узлах, где "состояние до
обновления" уже слегка различалось.
Из-за этого "обновление" перестаёт быть полностью повторяемой операцией.
В OSTree-модели вы говорите: "узел должен быть на ref X".
Ref X указывает на конкретный коммит. Коммит - это конкретное состояние.
Два узла, которые взяли один и тот же ref/коммит, получают одинаковую базу.
Это не означает, что у них будут одинаковые данные и конфиги приложения. Но
означает, что "скелет" ОС и системные компоненты соответствуют выпуску.
Подобный подход снижает "случайные поломки" так как обновление перестаёт быть
постепенным разрушением текущей установки.
Новая версия готовится отдельно, а переключение происходит на границе (обычно
на перезагрузке/переключении деплоя).
И главное: версия проверяется как единое целое на стороне сборки. Если у вас
нормальный процесс - вы тестируете выпуск (коммит) до того, как он пошёл в production.
OSTree - это не "поставил и забыл". Это другой стиль:
* Плюс: одинаковость и управляемость.
* Минус: вы не поощряете "а давай на этом сервере руками доустановим ещё 15
пакетов" как основной процесс.
Если вам нужен мир, где каждый сервер - снежинка, OSTree будет мешать.
Если вам нужен мир, где серверы - клоны с контролируемой базой, OSTree отлично ложится.
Кому OSTree подходит, а кому - нет
Подходит:
1. Много одинаковых серверов/ВМ
Когда вы хотите, чтобы "узлы одной роли" реально были одинаковыми, а не "примерно похожими".
2. Edge и удалённые площадки
Где откат должен быть быстрым и не требовать "разбора пакетов по косточкам".
3. Регламентированные контуры и аудит
Где нужно уметь показать, что конкретный узел работает на конкретной версии
системы, с подтверждаемым составом.
4. Инфраструктурные роли
NAT, VPN, IDS/сенсоры, логирование, базовые сервисы наблюдаемости - где важна
стабильная база и меньше сюрпризов от апдейтов.
Не подходит или требует аккуратности:
1. Постоянная уникальная ручная донастройка базовой системы на каждом узле
Если вы регулярно меняете именно "базу" руками (не конфиги, а состав системы),
вы будете воевать с моделью.
2. Ожидание "пакетного конструктора" без выпуска образа/коммита
OSTree раскрывается, когда есть выпуск (коммит) и канал (ref). Без дисциплины
выпусков вы теряете смысл.
3. Нет готовности вести refs и релизный процесс
Нужно определить, что такое stable/testing, как именуются refs, кто публикует, как тестируется.
4. Смешивание BIOS/UEFI и разных виртуальных контроллеров без профилей
OSTree не отменяет реальность загрузки: root-устройство, fstab, режим BIOS/UEFI
- всё это нужно учитывать. Если вы хотите "один образ на все случаи", придётся
делать профили сборки и правила.
Атомарные обновления в OSTree: какой подход лучше?
В НАЙС.ОС практический процесс обычно делится на две независимые роли:
1. Сервер OSTree - это машина, где:
* из RPM-репозиториев собирают дерево ОС по treefile (JSON),
* результат коммитят в OSTree-репозиторий,
* обновляют summary,
* публикуют каталог OSTree-репозитория по HTTP(S) для клиентов.
2. Клиент - это узел (или процесс сборки образа), который:
* добавляет remote на этот сервер,
* делает pull нужного ref,
* делает deploy,
* дальше загружается в выбранный deploy.
Для НАЙС.ОС у вас уже есть две "точки автоматизации", которые отлично ложатся на этот поток:
* mkostreerepo - поднимает/обновляет OSTree-репозиторий на сервере (rpm-ostree
compose tree + summary).
* mk-ostree-host.sh - готовит дисковый образ и выполняет deploy нужного ref (это будет в 3 части).
Эта часть статьи - про сервер: как создать репозиторий, как проверить, что он
корректный, и что именно публиковать клиентам.
Серверная часть: создание OSTree-репозитория в НАЙС.ОС
Требования и предпосылки
Серверу нужны:
* rpm-ostree и ostree (если rpm-ostree отсутствует, mkostreerepo пытается
поставить его через tdnf);
* доступ к RPM-репозиториям (откуда rpm-ostree будет собирать дерево);
* место на диске: репозиторий растёт, плюс есть кэш compose.
mkostreerepo организует рабочий каталог так:
* REPOPATH/repо - данные OSTree (это то, что публикуем);
* REPOPATH/cache - кэш сборки (это внутреннее, клиентам не нужно).
Три сценария использования mkostreerepo:
1. Быстрый старт "с нуля" (без своего JSON)
Если вы не указали JSON, скрипт проверит наличие REPOPATH/niceos-base.json.
Если файла нет - он сгенерирует минимальный treefile (niceos-base.json) и продолжит.
Пример:
sudo /usr/bin/rpm-ostree-server/mkostreerepo -r=/srv/ostree/niceos
Что произойдёт:
* создастся каталог /srv/ostree/niceos (если его нет);
* создадутся подкаталоги repo и cache;
* при необходимости будет создан niceos-base.json;
* будут сгенерированы дефолтные *.repo (если их нет и не включён custom режим);
* выполнится rpm-ostree compose tree, появится коммит и ref;
* обновится summary.
2. Управляемый вариант "своё дерево" (с treefile JSON)
Это нормальный путь для продакшена: вы фиксируете состав системы как декларацию.
Пример:
sudo /usr/bin/rpm-ostree-server/mkostreerepo \
-r=/srv/ostree/niceos \
-p=/srv/ostree/niceos/treefiles/niceos-minimal.json
Поведение скрипта:
* проверит, что JSON существует,
* скопирует его в REPOPATH (и будет использовать уже копию внутри каталога репо),
* продолжит сборку.
3. "Custom repo files" (-c) - осторожно, там интерактив
Флаг -c/--customrepo говорит "репофайлы будут кастомные, дефолтные не генерировать".
Но дальше в скрипте есть интерактивный вопрос (Y/N), который может повесить CI/автоматизацию.
Практический смысл:
* если вы хотите полностью контролировать *.repo и не допускать автогенерации - используйте -c,
* но учтите, что для неинтерактивной сборки нужно либо патчить этот участок,
либо заранее обеспечить все нужные *.repo и выбрать режим без вопросов.
Пример (который может уйти в интерактив):
sudo /usr/bin/rpm-ostree-server/mkostreerepo \
-c \
-r=/srv/ostree/niceos \
-p=/srv/ostree/niceos/niceos-base.json
В treefile (JSON) на уровне процесса важны три вещи:
1. ref - имя канала поставки. Это "публичная API-точка" для клиентов.
2. repos - какие RPM-репозитории используются для сборки.
3. packages/units - состав системы и важные сервисы.
Минимальный фрагмент логики (по смыслу):
{
"osname": "niceos",
"releasever": "5.2",
"ref": "niceos/5.2/x86_64/minimal",
"repos": ["niceos", "niceos-updates", "niceos-extras"],
"packages": ["systemd","openssh","rpm-ostree"],
"units": ["sshd.service"]
}
Замечание по дисциплине:
ref лучше держать стандартизированным: версия -> архитектура -> профиль.
Это упрощает каналы stable/testing и жизнь тем, кто будет обслуживать систему через год.
Публикация repo по HTTP(S) и контроль (refs/summary)
Клиентам нужен только каталог OSTree-репозитория: REPOPATH/repo.
Каталог cache публиковать не нужно (и не стоит): это внутренний кэш сборки.
Summary критичен так как mkostreerepo после compose делает:
* ostree summary --repo=... --update
* ostree summary -v --repo=...
Summary - это метаданные, которые помогают клиентам быстро обнаруживать refs и
корректно работать с репозиторием.
Если summary не обновлён, вы получаете странные симптомы на клиентах: "ref не
виден", "pull ведёт себя не так", "не сходится список refs".
Базовые проверки на сервере
1. Посмотреть refs:
ostree refs --repo=/srv/ostree/niceos/repo
2. Посмотреть историю по ref (пример):
ostree log --repo=/srv/ostree/niceos/repo niceos/5.2/$(uname -m)/minimal | head -n 80
3. Проверить summary:
ostree summary -v --repo=/srv/ostree/niceos/repo
4. Проверить структуру каталога:
ls -la /srv/ostree/niceos
ls -la /srv/ostree/niceos/repo | head -n 50
ls -la /srv/ostree/niceos/cache | head -n 50
Идея публикации по HTTP(S): веб-сервер должен отдавать /srv/ostree/niceos/repo по URL вида:
http://OSTREE_SERVER/ostree/repo/
Дальше клиент на своей стороне добавляет remote и делает pull/deploy (это будет в 3 части).
Проверка доступности с клиента (просто "жив ли HTTP"):
curl -I "http://OSTREE_SERVER/ostree/repo/" || true
Мини-чеклист "сервер готов"
1. REPOPATH существует, внутри есть repo/ и cache/.
2. ostree refs показывает нужные refs (и они соответствуют вашей схеме именования).
3. ostree summary -v отрабатывает без ошибок.
4. repo/ доступен по HTTP(S) из сети клиентов.
5. В release-процессе есть правило: после каждого compose summary обновляется
(и это реально выполняется).
Нюансы и типовые грабли на сервере
Репозитории RPM и ключи
В дефолтных *.repo, которые mkostreerepo может сгенерировать, включён:
* gpgcheck=1
* gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-NICEOS
Это правильно по смыслу, но означает простую вещь:
на сервере сборки должны быть ключи и доверие, иначе compose упадёт не "из-за
OSTree", а из-за проверки подписей RPM.
Customrepo в CI
Флаг -c может вызвать интерактив (Y/N). Для CI это неприятно:
пайплайн повиснет, пока кто-то не придёт "нажать кнопку".
Если вы хотите автоматизацию, обычно лучше:
* не использовать интерактивный режим,
* либо заранее подготовить *.repo и доработать скрипт под non-interactive.
Разделение прав доступа
Репозиторий - это точка поставки системы.
Нормальная практика:
* запись в repo/ только у сборочного пользователя/процесса,
* веб-сервер имеет только чтение,
* доступ снаружи ограничен (HTTPS или закрытый контур).
Клиентская часть: развёртывание системы/образа в НАЙС.ОС
На клиентской стороне OSTree даёт приятную вещь: вы перестаёте "устанавливать
систему пакетами" как набор мелких действий.
Вы либо:
1. разворачиваете систему прямо в sysroot (условная "установка" через pull/deploy),
либо
2. готовите дисковый образ, в котором уже есть нужный deploy и настроен загрузчик.
Для практики (особенно под виртуализацию) второй вариант удобнее: один раз
собрали образ - дальше тиражируете как шаблон.
В НАЙС.ОС под это уже есть скрипт: mk-ostree-host.sh, который делает образ
диска и разворачивает в него выбранный ref.
Пример "как развернуть" через mk-ostree-host.sh (RAW-образ)
Скрипт выполняет полный цикл подготовки загрузочного дискового образа:
1. Создаёт sparse-файл *.raw заданного размера (будущий диск).
2. Подключает его как loop-устройство.
3. Размечает GPT под BIOS-режим:
* p1: BIOS boot (для GRUB2),
* p2: /boot,
* p3: / (корень).
4. Создаёт device-mapper устройства для разделов (kpartx).
5. Форматирует p2 и p3 в ext4.
6. Монтирует p3 как sysroot, p2 как /boot.
7. Инициализирует OSTree sysroot, добавляет remote, делает pull нужного ref и deploy.
8. Подмонтирует внутрь деплоя служебные FS (/dev, /proc, /sys, /run, /boot).
9. Устанавливает GRUB2 в образ, генерирует конфиги, выставляет kernel args.
10. Подменяет root= так, чтобы система загрузилась на целевой машине.
11. Прописывает /etc/fstab и задаёт временный пароль root.
12. Аккуратно размонтирует всё и снимает loop/devicemapper (даже при ошибках).
Скрипт принимает:
* FILE_SIZE - размер образа в ГБ.
* IMG_NAME - имя (получится IMG_NAME.raw).
* IP_ADDR - адрес OSTree-сервера (remote будет вида http://IP_ADDR).
* REPO_REF - ref, который нужно развернуть (например niceos/5.2/x86_64/minimal).
* MOUNT_POINT - временная точка монтирования sysroot при сборке.
* root-dev - важный параметр: какой диск "увидит" ОС при старте (обычно /dev/sda3 или /dev/vda3).
Во время сборки образа корень выглядит как что-то вроде:
/dev/mapper/loop0p3
Но при запуске VM/на железе это устройство не существует.
Там корневой раздел будет, например:
* /dev/sda3 (классический SATA/SCSI контроллер),
* /dev/vda3 (virtio в KVM/QEMU),
* либо другие варианты в зависимости от платформы.
Поэтому скрипт делает важный трюк:
сначала настраивает root= на "текущее" устройство сборки, а затем заменяет его
на целевое root-dev, чтобы загрузчик в реальной машине искал корень там, где он
действительно будет.
Если root-dev выбран неверно - типичная ошибка: система падает на старте с "cannot mount root".
Пример запуска (BIOS + SATA: /dev/sda3)
sudo ./mk-ostree-host.sh \
-s 20 \
-n niceos-5.2-minimal \
-i 10.0.0.10 \
-r niceos/5.2/x86_64/minimal \
-m /mnt/niceos-root \
--root-dev /dev/sda3
Пример запуска (BIOS + virtio: /dev/vda3)
sudo ./mk-ostree-host.sh \
-s 20 \
-n niceos-5.2-virtio \
-i 10.0.0.10 \
-r niceos/5.2/x86_64/minimal \
-m /mnt/niceos-root \
--root-dev /dev/vda3
Скрипт пишет лог в /var/log/mk-ostree-host.sh-YYYY-MM-DD.log
Проверка:
sudo tail -n 200 "/var/log/mk-ostree-host.sh-$(date +%Y-%m-%d).log"
Проверка результата на первом запуске и базовая эксплуатация
Когда VM загрузилась, задача администратора - убедиться, что активен нужный
deploy и базовые точки монтирования корректны.
Первые обязательные действия
1. Сменить временный пароль root (скрипт ставит root:changeme):
passwd
2. Посмотреть состояние OSTree:
ostree admin status
Смысл вывода:
* вы увидите, какие deploy существуют,
* какой активен сейчас,
* какой будет активен после перезагрузки (если применимо).
3. Проверить монтирование / и /boot:
mount | egrep ' on / | on /boot '
4. Проверить fstab:
cat /etc/fstab
Ожидаемая логика (пример):
* /dev/sda3 -> /
* /dev/sda2 -> /boot
Если ваша VM использует virtio, там должно быть /dev/vda* (иначе вы заложили
неверный root-dev и fstab).
5. Проверить записи загрузки:
ls -la /boot/loader/entries/
Это быстрый способ убедиться, что deploy действительно подготовил загрузочные entry.
Идея отката (rollback) без длинных портянок
OSTree хорош тем, что откат - это не "удалить 30 пакетов и вернуть 30 пакетов",
а переключение между deploy.
Модель простая:
* у вас есть "текущая версия" (deploy A),
* вы обновились/развернули новую (deploy B),
* если после перехода на B что-то не так - вы возвращаетесь на A.
На практике, прежде чем идти в сложную диагностику, в эксплуатационном контуре часто логичнее:
1. вернуть рабочее состояние откатом,
2. затем спокойно разбирать, почему новый deploy оказался проблемным.
В системах, где важен SLA, это прямое попадание в реальность: "сервис должен
работать", а не "мы сейчас два часа разгадываем зависимость".
Типовые ошибки и диагностика на клиенте
VM не загружается: неверный root-dev
Симптом:
kernel panic / cannot mount root / ожидание root device.
Причина: в загрузчике root= указывает на /dev/sda3, а реально диск -
/dev/vda3 (или наоборот).
Решение:
* пересобрать образ с правильным --root-dev,
* либо (в аварийном режиме) править loader entries и fstab вручную - но это уже
"ремонт", а не нормальный процесс.
Клиент не тянет ref: сеть/summary/ref
Симптом:
pull падает, ref не виден, список refs пустой.
Причины:
* нет доступа до HTTP(S) репозитория,
* сервер не публикует repo/,
* summary не обновлён,
* ref указан неправильно.
Быстрые проверки:
* curl -I до URL репозитория,
* ostree remote refs на клиенте,
* ostree summary -v на сервере.
Платформа UEFI, а образ BIOS
Симптом: VM не видит загрузчик, "No bootable device".
Причина: текущий mk-ostree-host.sh размечает BIOS-only (bios_grub), без EFI System Partition.
Решение:
* держать отдельный профиль сборки UEFI (ESP + grub2-efi),
* не пытаться "одним образом" закрыть все режимы загрузки без профилей.
Устройство загрузки поменялось, fstab не совпадает
Симптом: загрузка проходит частично, /boot не монтируется или корень монтируется не туда.
Причина: fstab жёстко привязан к /dev/sdX или /dev/vdX, а среда другая.
Решение:
* заранее стандартизировать профили (virtio/sata),
* либо перейти на UUID/labels в fstab как правило эксплуатации (это отдельное улучшение процесса).
Мини-чеклист "клиент готов"
1. Узел загрузился в нужный профиль (BIOS/virtio или BIOS/sata - как планировали).
2. Пароль root сменён (root:changeme не должен жить дальше первого входа).
3. ostree admin status показывает ожидаемый deploy/ref.
4. / и /boot смонтированы корректно, /etc/fstab соответствует реальной схеме диска.
5. /boot/loader/entries содержит записи, соответствующие deploy.
6. У вас есть регламент: как обновляем (ref stable/testing), и как откатываем при проблемах.
На этом "скелет" процесса закрыт: сервер публикует репозиторий и ref, клиент
разворачивает deploy в образ/узел и получает предсказуемые обновления и откаты.
|
| |
|
|
|
Создание загрузочного атомарно обновляемого образа Oracle Linux при помощи OSTree (доп. ссылка 1) |
[комментарии]
|
| | Использование инструментария OSTree для сборки из Oracle Linux загрузочных
образов, обновляемых атомарно без разделения на отдельные пакеты.
Устанавливаем ostree и rpm-ostree
dnf install -y ostree rpm-ostree
Создаём рабочий каталог ~/ostree-test и инициализируем ostree-репозиторий:
mkdir $HOME/ostree-test
cd $HOME/ostree-test
ostree --repo=$(pwd) init
Формируем в каталоге ~/ostree-test начинку репозитория
sudo dnf install --installroot=$(pwd) --releasever=9 oraclelinux-release rpm-ostree bash coreutils kernel-uek-core grub2-efi-x64 -y
Добавляем созданную начинку в репозиторий ostree:
ostree --repo=$(pwd) commit -b my_ostree_test --tree=dir=$(pwd) --subject="My first ostree OL9 commit"
Перегенерируем сводный файл с метаданными:
ostree --repo=$(pwd) summary --update
Извлекаем корневую ФС из внешнего репозитория ostree-test, используя
промежуточный локальный репозиторий ostree-test-remote:
cd $HOME
mkdir ostree-test-remote
cd ostree-test-remote
sudo ostree --repo=$(pwd) init
sudo ostree --repo=$(pwd) remote add ol-local file:///$HOME/ostree-test --no-gpg-verify
sudo ostree --repo=$(pwd) remote refs ol-local # выдаст ветку ol-local:my_ostree_test
Извлекаем файлы для проверки содержимого корневой ФС
sudo ostree --repo=$(pwd) pull ol-local my_ostree_test
sudo ostree --repo=$(pwd) checkout my_ostree_test newroot
ls newroot
afs config extensions lib64 objects refs sbin sys var
bin dev home media opt root srv tmp
boot etc lib mnt proc run state usr
Активируем загрузочную файловую систему и перезагружаемся в неё:
sudo rpm-ostree rebase ol-local:my_ostree_test
sudo systemctl reboot
Для установки дополнительных rpm-пакетов поверх созданного окружения можно
использовать команду "rpm-ostree install имя_пакета".
|
| |
|
|
|
Сборка deb-пакета для решения проблем с плагином nvim-cmp для neovim в Debian 13 |
Автор: Archer73
[комментарии]
|
| | После обновления на Debian 13 и обновления плагинов для neovim столкнулся с
неприятной ошибкой в популярном плагине для автокомплита nvim-cmp. Ошибка
происходила при вводе любых данных в режиме вставки. Трассировка выдавала
что-то на подобии:
Обнаружена ошибка при обработке TextChangedI Автокоманды для "*":
Error executing lua callback: /usr/local/share/nvim/runtime/lua/vim/lspclient.lua:643: bufnr: expected number, got function
stack traceback:
[C]: in function 'error'
vim/shared.lua: in function 'validate'
/usr/local/share/nvim/runtime/lua/vim/lsp/client.lua:643: in function 'resolve_bufnr'
...
Решение
В Debian 13 находится neovim версии 0.10.4. Дополнение nvim-cmp по какой-то
причине требует для работы более новую версию neovim. В частности, проблема
исчезла с версией 0.11.3.
Установка более свежей версии neovim
Существует много способов установки более свежих пакетов в Debian, включая
подключение репозитория backports и использование самодостаточных пакетов типа
appimage или flatpack. Ниже будет описан более сложный, но универсальный и
контролируемый способ - сборка необходимого deb пакета вручную. Руководство по
сборке и установки рассчитано на пользователей которые никогда раньше этим не занимались.
1. Клонирование нужной версии из официального репозитория:
git clone --depth=1 --recurse-submodules --branch=v0.11.3 https://github.com/neovim/neovim.git
--depth=1 позволяет не скачивать всю историю изменений ветки
--recurse-submodules заставляет скачать все необходимые для сборки модули из
других репозиториев github
--branch=v0.11.3 указывает необходимую для скачивания ветку, в частности
используем ветку помеченую через tag v0.11.3
2. Компиляция программы
Переходим в директорию neovim и начинаем сборку:
cd neovim
make CMAKE_INSTALL_PREFIX=/usr/local/ -j14
prefix позволяет задать директорию для дальнейшей установки пакета отличной от
директории по умолчанию. Пакеты собранные вручную лучше располfгать по пути /usr/local/
Флаг -j14 определяет количество потоков, которые будут использоваться для
параллельной сборки. Рекомендуется использовать не более чем количество
логических ядер процессора + 1.
3. Установка программы в локальную директорию
После окончания сборки создадим временную директорию nvim-v0.11.3 и установим в
неё скомпилированный neovim:
mkdir nvim-v0.11.3
make DESTDIR=$(pwd)/nvim-v0.11.3 install
DESTDIR указывает директорию, которая будет использована вместо корня файловой
системы. $(pwd) дописывает абсолютный путь к текущей директории. После этого
шага директория nvim-v0.11.3 должна содержать папку usr содержимым, которое
пакетный менеджер должен добавить в текущую систему.
На данном этапе программа уже может работать и не вызывать ошибок. Проверить это выполнив команду:
nvim-v0.11.3/usr/local/bin/nvim
4. Подготовка информации для превращения созданной директории в deb пакет
Для формирования пакета в директории nvim-v0.11.3 необходимо создать еще одну
папку DEBIAN и добавить в ней два файла.
Файл с описанием пакета nvim-v0.11.3/DEBIAN/control со следующим содержимым:
Package: neovim
Version: 0.11.3
Architecture: amd64
Section: editors, devel
Priority: standard
Maintainer: Ваше Имя {your@mail.ru>
Description: Code editor
Можно изменить сведения в поле Maintainer и отредактировать поле Architecture в
соответствии с архитектурой вашего процессора (актуально для всяких SBC на ARM
и RISC-V)
Устанавливаемые программы могут использовать разделяемые библиотеки (shared
object). Данные библиотеки содержат общий для разных программ код в виде
скомпилированных функций. Для того, чтобы эти библиотеки были доступны из места
их установки часто необходимо указать системе о необходимости обновить
соответствующую информацию. Сделать это можно в специальном скрипте,
выполняемом после установки. Содержимое файла nvim-v0.11.3/DEBIAN/postinst
должно выглядеть так:
#!/usr/bin/env bash
ldconfig && echo "Кэш разделяемых библиотек обновлен"
Данный скрипт необходимо сделать исполняемым. Сделать это можно консольной командой:
chmod +x nvim-v0.11.3/DEBIAN/postinst
5. Сборка deb пакета
Теперь полученную директорию можно превратить в deb пакет. Для этого необходимо выполнить команду:
dpkg-deb --build --root-owner-group nvim-v0.11.3
После успешного выполнения команды в текущей директории должен появиться файл
nvim-v0.11.3.deb. Пакет можно скопировать на флешку либо распростронять любым
другим способом, чтобы не собирать его снова на других компьютерах.
6. Установка deb пакета
Установить пакет можно с помощью менеджера apt:
sudo apt install ./nvim-v0.11.3.deb
При помощи apt пакет можно будет удалить. При необходимости установить более
свежую версию nvim apt автоматически удалит предыдущую.
После установки nvim должен запускаться и нормально работать с указанным плагином.
|
| |
|
|
|
Linux окружение noroot в Android-смартфоне собственными руками. (доп. ссылка 1) |
Автор: Павел Оредиез
[комментарии]
|
| | В этой заметке я расскажу как собрать своё Linux-окружение на Android-смартфоне
без прав root (рутовать телефон не надо). Можно конечно взять готовые решения в
Google Play Store, но можно и пройти этот путь самостоятельно.
Если вы решите повторить мой опыт, то вы получите Xfce4-окружение с псевдо
пользователем root на своём мобильном телефоне с Android. Работает это почти
без отличий от реального пользователя root, только конечно модифицировать сам
телефон это возможности не даёт. Итак приступим.
Termux
Установим в Android приложение Termux (требуется Android версии 7 или выше).
Это наше базовое Linux окружение и отправная точка. Запуская его мы попадаем в
шелл с домашним каталогом, который будем называть TERMUX_HOME.
Итак в TERMUX_HOME установим требуемые нам начальные пакеты:
pkg install root-repo
pkg install proot
pkg install debootstrap
pkg install nano
pkg install wget
pkg install man
Debootstrap
Теперь можно устанавливать Linux окружение.
Проверим нашу архитектуру.
uname -ar
Linux localhost 4.9.193-perf-gc285628 #1 SMP PREEMT Fri Aug 6 02:12:50 CST 2021 aarch64 Android
Моя архитектура 64-битная, значит --arch=arm64. Если у вас архитектура
32-битная, то ваш вариант --arch=armhf
В TERMUX_HOME:
mkdir ./chroot
debootstrap --arch=arm64 bullseye ./chroot http://mirror.yandex.ru/debian
mkdir ./chroot/system
mkdir ./chroot/apex
mkdir ./chroot/home/user
Вот мы получили базовое окружение. Правда dpkg configure отработает наверное с
некоторыми ошибками, но войти в окружение уже можно. Ошибки мы разберём позже.
Вход в Linux окружение
Вход под псевдо рутом нам позволяет команда proot, которую мы установили ранее.
В TEMUX_HOME создадим скрипт входа start.sh:
#!/data/data/com.termux/files/usr/bin/sh
unset LD_PRELOAD
proot \
-0 \
--link2symlink \
-w /root \
-r ./chroot \
-b /sys/ \
-b /system \
-b /apex \
-b /proc/ \
-b /dev/ \
-b /dev/pts/ \
/usr/bin/env \
-i \
HOME=/root \
LD_LIBRARY_PATH=/system/lib64:/system/apex/com.android.runtime.release/lib64 \
XDG_RUNTIME_DIR=/tmp \
DISPLAY=127.0.0.1:0 \
PULSE_SERVER=tcp:127.0.0.1:4713 \
TERM="xterm-256color" \
PATH=/bin:/usr/bin:/sbin:/usr/sbin \
/bin/bash --login
Для входа не под root (опционально) создайте скрипт входа ustart.sh:
#!/data/data/com.termux/files/usr/bin/sh
unset LD_PRELOAD
proot \
--link2symlink \
-w /root \
-r ./chroot \
-b /sys/ \
-b /system \
-b /apex \
-b /proc/ \
-b /dev/ \
-b /dev/pts/ \
/usr/bin/env \
-i \
HOME=/home/user \
LD_LIBRARY_PATH=/system/lib64:/system/apex/com.android.runtime.release/lib64 \
XDG_RUNTIME_DIR=/tmp \
DISPLAY=127.0.0.1:0 \
PULSE_SERVER=tcp:127.0.0.1:4713 \
TERM="xterm-256color" \
PATH=/bin:/usr/bin:/sbin:/usr/sbin \
/bin/bash --login
Для 32-битного окружение поправьте LD_LIBRARY_PATH
Сделаем скрипты исполняемыми:
chmod a+x start.sh
chmod a+x ustart.sh
Теперь можно войти в окружение:
./start.sh
root@localhost:~#
Вот мы и псевдо root :).
Назовём это ENV_HOME.
Ошибки dpkg
Ошибки dpkg в основном у меня были связаны с неправильной работой
утилиты adduser при добавлении системных пользователей. Поэтому чтобы избежать
их сразу дополним файлы (в ENV_HOME)
/etc/passwd:
systemd-timesync:x:100:102:systemd Time Synchronization,,,:/run/systemd:/usr/sbin/nologin
systemd-network:x:101:103:systemd Network Management,,,:/run/systemd:/usr/sbin/nologin
systemd-resolve:x:102:104:systemd Resolver,,,:/run/systemd:/usr/sbin/nologin
_apt:x:103:65534::/nonexistent:/usr/sbin/nologin
messagebus:x:104:110::/nonexistent:/usr/sbin/nologin
statd:x:106:65534::/var/lib/nfs:/usr/sbin/nologin
avahi:x:108:113:Avahi mDNS daemon,,,:/var/run/avahi-daemon:/usr/sbin/nologin
systemd-coredump:x:996:996:systemd Core Dumper:/:/usr/sbin/nologin
user:x:10264:10264:User:/home/user:/bin.bash
/etc/group:
systemd-journal:x:101:
systemd-timesync:x:102:
systemd-network:x:103:
systemd-resolve:x:104:
netdev:x:109:pi
messagebus:x:110:
avahi:x:113:
systemd-coredump:x:996:
user:x:10264:
Здесь id 10264 это id моего пользователь в TERMUX_HOME. У вас может быть другое число.
Второй хук для неисправных пакетов заключается в убирании скриптов конфигурирования (в ENV_HOME):
mv /var/lib/dpkg/info/<package>* /tmp/
Установка остальных пакетов
В ENV_HOME выполним
apt install xfce4 dbus-x11
Мы готовы запустить графическую оболочку, для этого нам нужен X сервер.
X сервер
В Android установите приложение XServer XSDL. Этот сервер имеет также
звуковую pulseaudio подсистему. Ранее в скриптах входа в окружение в команде
proot мы передали переменные DISPLAY и PULSE_SERVER, так что у нас все готово
для запуска (в ENV_HOME):
xfce4-session
Должна запуститься графическая оболочка, звук тоже должен работать (звуковой
вход не поддерживается только воспроизведение).
Xserver XSDL может показаться сначала не очень красивым, но он хорошо
функционален и красоты можно добиться. Мои параметры:
ориентация портретная, разрешение нативное, дурацкие кнопки alt-shift-чего-то
скрыты (они у меня всё равно не работают или я не понял как), мышь в режиме
телефон-тачпад. Можно еще попробовать поиграться с xrandr если поддерживается
для использования виртуального пространства X сервера, я не пробовал.
Библиотеки Android
В аргументах команды proot мы пробросили в окружение Android каталоги /system и /apex.
Так что нам доступны Android библитеки /system/lib /system/lib64.
Например мне нужно было чтобы правильно отрабатывала команда
ldd /system/lib64/libOpenSLES.so
(не должно быть "not found").
Если ldd отрабатывает неправильно, то обратите внимание, библиотеки в
/system/lib* могут быть симлинками на другие места. Возможно надо подбиндить
другие каталоги Android и(или) поправить LD_LIBRARY_PATH.
Благодарности
Выражаю свою благодарность Sergii Pylypenko (pelya) за его труд - автору проектов
XServer XSDL, pulseaudio-android, xserver-xsdl, Debian noroot. У
него я подсмотрел многое.
|
| |
|
|
|
Получаем патчи безопасности для Ubuntu 16.04 (доп. ссылка 1) |
Автор: Владимир
[комментарии]
|
| | У операционной системы Ubuntu 16.04 закончилась основная поддержка https://wiki.ubuntu.com/Releases
Пользователи Ubuntu 16.04 могут продолжить получать патчи безопасности для
своей системы до 2024 года, но для этого требуется подключение к программе
Ubuntu Advantage. На один аккаунт можно добавить 3 машины (бесплатно для
персонального использования), получив ключ по ссылке https://ubuntu.com/advantage
Free for personal use
Anyone can use UA Infrastructure Essential for free on up to 3
machines (limitations apply). All you need is an Ubuntu One account.
В последнем обновлении поставляется утилита ua с помощью которой происходит подключение к сервису
user@ubuntu:~$ sudo ua attach Ca1**********
[sudo] пароль для user:
Enabling default service esm-infra
Updating package lists
UA Infra: ESM enabled
Enabling default service livepatch
Installing snapd
Updating package lists
Installing canonical-livepatch snap
Canonical livepatch enabled.
This machine is now attached to '*****@gmail.com'
SERVICE ENTITLED STATUS DESCRIPTION
esm-infra yes enabled UA Infra: Extended Security Maintenance (ESM)
fips yes disabled NIST-certified FIPS modules
fips-updates yes disabled Uncertified security updates to FIPS modules
livepatch yes enabled Canonical Livepatch service
Также для систем которые ещё актуальны (ubuntu 18.04, 20.04) существует
сервис livepatch, поставляющий патчи для ядра Linux, устанавливаемые без
перезагрузки. Данный сервис также бесплатен для 3 машин на аккаунт.
|
| |
|
|
|
Просмотр зависимостей пакета и принадлежности файла пакету в Linux |
[комментарии]
|
| | Для просмотра от каких пакетов зависит пакет gnome-calculator:
Debian/Ubuntu:
apt depends gnome-calculator
Fedora/CentOS/RHEL:
dnf deplist gnome-calculator
SUSE:
zypper se --requires gnome-calculator
Для просмотра какие другие пакеты зависят от пакета gnome-calculator:
Debian/Ubuntu:
apt rdepends gnome-calculator
Fedora/CentOS/RHEL:
rpm -q --whatrequires gnome-calculator
dnf repoquery --whatrequires gnome-calculator
Для просмотра какому пакету принадлежит файл /usr/bin/gnote
Debian/Ubuntu:
dpkg -S /usr/bin/gnote
apt-file /usr/bin/gnote
Fedora/CentOS/RHEL:
rpm -qf /usr/bin/gnote
dnf provides /usr/bin/gnote
SUSE:
zypper wp /usr/bin/gnote
|
| |
|
|
|
Улучшение безопасности sources.list в дистрибутивах, использующих APT (доп. ссылка 1) |
Автор: KOLANICH
[комментарии]
|
| | Опция "signed-by" привязывает доверенный публичный ключ к репозиторию, что
блокирует установку ПО в случае, если InRelease подписан другим ключом. Опция
может быть установлена как в fingerprint ключа, так и в форме пути к файлу.
Это позволяет защититься от некоторых атак в следующей модели угроз:
1. допустим, что есть репозиторий, доступный по скомпрометированному каналу,
чей приватный ключ не может быть скомпрометирован;
2. допустим, что есть репозиторий, доступный по безопасному каналу, чей
приватный ключ был скомпромитирован;
3. оба репозитория прописаны в sources.list и оба ключа добавлены в доверенные.
Тогда, если нет привязки, злоумышленник может использовать скомпрометированный
ключ второго репозитория для подписи поддельного InRelease для первого
репозитория, получая RCE.
Поэтому в https://wiki.debian.org/DebianRepository/UseThirdParty рекомендуется
прописывать всем сторонним репозиториям "signed-by", при этом указано
использовать путь к ключу вместо fingerprint-а.
По моему мнению, имеет смысл прописывать signed-by вообще всем репозиториям.
В дистрибутивах, использующих APT, почему-то по умолчанию не используется опция
signed-by. В инструкциях по подключению других репозиториев тоже почти никогда
не встречаются указания её использовать.
Так как ручная идентификация ключей для каждого репозитория - дело трудоёмкое,
был подготовлен скрипт, разбирающий sources.list, автоматически
идентифицирующий fingerprint-ы и файлы ключей для каждого репозитория и
выдающий модифицированный sources.list для сравнения с оригинальным.
В скрипте используется собственная библиотека для парсинга и сериализации
sources.list на основе грамматики для parglare.
|
| |
|
|
|
Обновление версии Fedora из командной строки (доп. ссылка 1) (доп. ссылка 2) |
[комментарии]
|
| | При выходе новой версии Fedora приложение GNOME Software автоматически
предлагает перейти на новый релиз, не покидая графический интерфейс.
Для тех кому необходимо выполнить обновление из командной строки, можно
использовать следующую последовательность команд.
Обновляем текущее окружение до самого свежего состояния:
sudo dnf upgrade --refresh
Устанавливаем плагин к DNF для обновления выпусков дистрибутива:
sudo dnf install dnf-plugin-system-upgrade
Запускаем загрузку пакетов для обновления до релиза Fedora 29:
sudo dnf system-upgrade download --releasever=29
В случае проблем с нарушением зависимостей, устаревшими и необновляемыми
пакетами можно использовать опцию "--allowerasing" для удаления проблемных пакетов.
После окончания загрузки новых пакетов инициируем применение обновлений после перезагрузки системы:
sudo dnf system-upgrade reboot
После завершения обновления система ещё раз перезагрузится.
Если в новой системе выводится сообщение о повреждении БД RPM, можно
перегенерировать индекс пакетов:
sudo rpm --rebuilddb
Если после обновления часть пакетов осталась необновлена или наблюдаются
проблемы с зависимостями, можно попробовать вручную запустить distro-sync:
sudo dnf distro-sync
или с удалением проблемных пакетов
sudo dnf distro-sync --allowerasing
В случае предупреждений о недопустимости выполнения операций из-за ограничений
SELinux можно перегенерировать метки SELinux:
sudo fixfiles onboot
|
| |
|
|
|
Как очистить ранее установленные старые ядра Linux в Ubuntu, RHEL и Fedora (доп. ссылка 1) |
[комментарии]
|
| | В Ubuntu после установки очередного обновления ядра Linux, ранее использованное
ядро сохраняется. Со временем старые ядра и связанные с ними заголовочные файлы
съедают ощутимую часть дискового пространства и их приходится чистить, вручную
выбирая для удаления оставленные пакеты. Начиная с Ubuntu 16.04 в репозиторий
добавлен пакет byobu, в котором имеется скрипт purge-old-kernels,
предназначенный для очистки старых ядер.
Устанавливаем пакет:
sudo apt install byobu
(в более ранних выпусках утилита находилась в пакете bikeshed)
или загружаем скрипт отдельно:
wget https://raw.githubusercontent.com/dustinkirkland/byobu/master/usr/bin/purge-old-kernels
Проводим чистку старых ядер:
sudo purge-old-kernels
По умолчанию после выполнения этой команды в системе будет оставлено два самых
свежим пакета с ядром. При желании число оставленных пакетов можно изменить при
помощи опции "--keep", например:
sudo purge-old-kernels --keep 3
Скрипт достаточно прост:
KEEP=2
APT_OPTS=
CANDIDATES=$(ls -tr /boot/vmlinuz-* | head -n -${KEEP} | grep -v "$(uname -r)$" | cut -d- -f2- | awk '{print "linux-image-" $0 " linux-headers-" $0}' )
for c in $CANDIDATES; do
dpkg-query -s "$c" >/dev/null 2>&1 && PURGE="$PURGE $c"
done
if [ -z "$PURGE" ]; then
echo "No kernels are eligible for removal"
exit 0
fi
apt $APT_OPTS remove --purge $PURGE
В Red Hat Enterprise Linux и CentOS для чистки старый ядер можно использовать
утилиту package-cleanup, которая входит в состав пакета yum-utils. Например,
чтобы оставить только два последних ядра можно выполнить:
package-cleanup --oldkernels --count=2
В Fedora для решения аналогичной задачи можно воспользоваться штатным DNF:
dnf remove $(dnf repoquery --installonly --latest-limit -2 -q)
|
| |
|
|
|
Автоматическая установка Debian с помощью preseed (доп. ссылка 1) |
Автор: l8saerexhn1
[комментарии]
|
| | Требовалось установить Debian с флешки или CD в полностью автоматическом
режиме. Без доступа к Интернету. Софт- минимальный набор (Debian Jessie
netinstall ISO). Архитектура - i686. После инсталляции необходимо установить
дополнительные пакеты, произвести определенные настройки установленной ОС. Тоже
в автоматическом режиме.
Установку Debian'a можно полностью автоматизировать путем создания файла со
сценарием ответов на все вопросы инсталлятора. Интегрировав данный сценарий в
инсталляционный образ получим полностью самоустанавливаемый Debian. Способ
автоматической установки называется Debian Preseed. Созданный файл-сценарий
ответов (preseed.cfg) пакуется его в initrd инсталляционного ISO-образа Debian.
На выходе получаем обычный ISO-образ, готовый к автоматической установке.
Для создания собственного инсталляционного ISO-образа необходимо произвести ряд действий. А именно:
смонтировать оригинальный ISO;
"выудить" из него initrd, распаковать его;
скопировать в "корень" initrd созданный файл preseed.cfg и все необходимое
для настройки устанавливаемой системы по завершении установки (см. ниже);
собрать обратно ISO образ.
Для автоматизации сборки образа сделаем скрипт makeiso.sh. Выполнять его
необходимо с правами рута. Для работы скрипта нужны установленные пакеты rsync,
syslinux, genisoimage, md5sum.
В директорию, где находится скрипт, необходимо скопировать оригинальный Debian
ISO и файл-сценарий preseed.cfg. Также необходимо создать директорию extra - в
ней будут находиться пост-инсталляционный скрипт и все необходимое, для его работы.
cat makeiso.sh
#!/bin/bash
mkdir mnt
mkdir irmod
mkdir cd
INISO=debian-8.3.0-i386-netinst.iso
OUTISO=debian-preseed.iso
mount -o loop $INISO mnt
rsync -a -H --exclude=TRANS.TBL mnt/ cd
umount mnt
rmdir mnt
# Pack custom initrd
cd irmod
gzip -d < ../cd/install.386/initrd.gz | cpio --extract --verbose --make-directories --no-absolute-filenames
cp -f ../preseed.cfg preseed.cfg
find . | cpio -H newc --create --verbose | gzip -9 > ../cd/install.386/initrd.gz
cd ../
rm -fr irmod/
# Fix md5 sum
cd cd
md5sum `find -follow -type f` > md5sum.txt
cd ..
# Copy custom postinst script to new ISO
cp -Rf extra cd/
# Create new ISO
rm test.iso
genisoimage -o $OUTISO -r -J -no-emul-boot -boot-load-size 4 -boot-info-table -b isolinux/isolinux.bin -c isolinux/boot.cat ./cd
rm -rf cd
isohybrid -o $OUTISO
При успешной отработке скрипта получим образ debian-preseed.iso (в формате
hybrid iso), готовый для записи как на USB-носитель, так и на CD.
Записать образ на флешку можно, например, вот так:
cat debian-preseed.iso /dev/sdX
где sdХ - флешка
Теперь, собственно, сам preseed-сценарий.
cat preseed.cfg
d-i debian-installer/locale string ru_RU.UTF8
d-i console-keymaps-at/keymap select ru
### Network configuration
d-i netcfg/enable boolean false
d-i netcfg/get_hostname string host_name
d-i netcfg/get_domain string domain.name
### Mirror settings
d-i mirror/country string enter information manually
d-i mirror/http/hostname string http.us.debian.org
d-i mirror/http/directory string /debian
d-i mirror/http/proxy string
### Partitioning
d-i partman-auto/method string regular
d-i partman-auto/disk string /dev/sda
d-i partman-auto/expert_recipe string \
boot-root:: \
1000 10000 1000000 ext4 \
$primary{ } $bootable{ } \
method{ format } format{ } \
use_filesystem{ } filesystem{ ext4 } \
mountpoint{ / } \
label{root} \
\
500 10000 1000000000 ext4 \
$primary{ } \
method{ format } format{ } \
use_filesystem{ } filesystem{ ext4 } \
mountpoint{ /var } \
\
128 2048 150% linux-swap \
$primary{ } method{ swap } format{ } \
d-i partman/confirm_write_new_label boolean true
d-i partman/choose_partition select Finish partitioning and write changes to disk
d-i partman/confirm boolean true
d-i clock-setup/utc boolean true
d-i time/zone string Europe/Moscow
### Apt setup
d-i apt-setup/non-free boolean true
d-i apt-setup/contrib boolean true
d-i apt-setup/use_mirror boolean false
# Additional repositories, local[0-9] available
d-i apt-setup/local0/repository string deb http://mirror.yandex.ru /debian jessie main
d-i apt-setup/local0/source boolean true
d-i apt-setup/local0/source string http://mirror.yandex.ru/debian jessie main
d-i debian-installer/allow_unauthenticated string true
### Account setup
d-i passwd/root-login boolean true
d-i passwd/root-password-crypted password MD5_password_hash
d-i passwd/make-user boolean true
d-i passwd/user-fullname string user
d-i passwd/username string user
d-i passwd/user-password-crypted password MD5_password_hash
### Base system installation
d-i base-installer/kernel/linux/initramfs-generators string yaird
### Boot loader installation
d-i grub-installer/skip boolean false
d-i lilo-installer/skip boolean true
d-i grub-installer/bootdev string default
d-i grub-installer/only_debian boolean true
d-i grub-installer/with_other_os boolean true
### Package selection
tasksel tasksel/first multiselect standard, ssh-server
popularity-contest popularity-contest/participate boolean false
### Finishing up the first stage install
d-i finish-install/reboot_in_progress note
d-i preseed/late_command string cp -R /cdrom/extra/ /target/root/; \
cd /target; \
chmod +x /target/root/extra/postinst.sh; \
in-target /bin/bash /root/extra/postinst.sh;
Пароль рута и пользователя задан в виде хеша. Хеш получаем командой:
mkpasswd -m md5
Диск разбивается на 3 раздела: /, /var, и swap. ФС - ext4, Размер swap - не
менее 128Мб, примерно 150% от объема установленной памяти. Остальные разделы -
примерно пополам от объема диска.
После окончания установки в свежеустановленную (т.н. "target") систему
копируется директория extra и в chroot-окружении запускается
постинсталляционный скрипт postinst.sh. Что ему делать - решать вам. Например,
доустановить дополнительный софт, произвести донастройку системы и т.п.
Все.
Литература
* How to modify an existing CD image to preseed d-i
* Автоматическая установка с помощью списка ответов
* Example preseed
* Bug #712907
* HOWTO automate Debian installs with preseed
|
| |
|
|
|
Обновление Debian Wheezy до Debian Jessie, не дожидаясь официального релиза (доп. ссылка 1) |
[комментарии]
|
| | До релиза Debian 8.0 (Jessie) остаются считанные недели, и за исключением
некоторых блокирующих релиз ошибок, дистрибутив уже вполне пригоден для
использовании на рабочей станции. Несмотря на то, что в Wheezy внесены
кардинальные системные изменения, связанные с переходом на systemd, обновление
с Wheezy проходит без заметных проблем.
1. Делаем резервную копию текущей системы.
2. Доводим Debian Wheezy до актуального состояния.
# apt-get update
# apt-get upgrade
3. Изучаем список не полностью установленных пакетов с состоянием Half-Installed или Failed-Config.
# dpkg --audit
4. Изучаем список отложенных пакетов.
# dpkg --get-selections | grep 'hold$'
5. Решаем выявленные на двух прошлых этапах проблемы, после чего удостоверимся,
что в общем списке все пакеты имеют статус 'ii' в первой колонке.
# dpkg -l| grep -v 'ii'| less
6. Удаляем забытые пакеты:
# apt-get autoremove
Подготовительная фаза завершена, приступаем к обновлению до Debian Jessie.
7. Изменяем список репозиториев в /etc/apt/sources.list. Вместо "wheezy" и
"stable" указываем "jessie".
# vi /etc/apt/sources.list
deb http://ftp.ru.debian.org/debian/ jessie main
deb http://security.debian.org/ jessie/updates main
deb http://ftp.ru.debian.org/debian/ jessie-updates main
deb http://ftp.ru.debian.org/debian/ jessie-backports main
8. Обновляем список доступных в Debian Jessie пакетов
# apt-get update
9. Обновление производится в две стадии. На первой выполняется замена только
пакетов, не приводящих к удалению или установке других пакетов.
На второй выполняется полное обновление всех версий с учётом зависимостей.
# apt-get upgrade
# apt-get dist-upgrade
В процессе выполнения dist-upgrade на экран будут выводиться запросы для
принятия тех или иных решений о ходе обновления. Как правило, предлагаемый по
умолчанию вариант оптимален.
10. Удаляем старые пакеты Wheezy.
# apt-get autoremove
|
| |
|
|
|
Запуск BitTorrent Sync в виде сервиса Systemd (доп. ссылка 1) |
[комментарии]
|
| | Создаём конфигурацию BitTorrent Sync:
btsync --dump-sample-config
и вносим необходимые изменения в /home/логин/.config/btsync/btsync.json
Создаём unit-файл с описанием параметров сервиса для Systemd - /usr/lib/systemd/system/btsync.service
[Unit]
Description=BTSync
After=network.target
[Service]
User=имя пользователя под которым будет запускаться BitTorrent Sync
ExecStart=/usr/bin/btsync --config /home/логин/.config/btsync/btsync.json --nodaemon
[Install]
WantedBy=multi-user.target
Активируем и запускаем сервис:
systemctl enable btsync
systemctl start btsync
|
| |
|
|
|
Полуавтоматическое разворачивание рабочих станций CentOS в домене MS Active Directory |
Автор: Дмитрий Казаров
[комментарии]
|
| | В заметке рассказывается о решении задачи по автоматизации установки новых
Linux систем и организации управления ими с помощью Active Directory.
Исходные данные:
Домен AD Domain.ru.
Дистрибутив CentOS, легально скачанный с сайта CentOS.org (у руководства
сейчас пунктик о 100% легальности софта).
Очень странный софт спец назначения - 64-битный софт с 32-битным установщиком.
Процесс организации установки Linux по сети
1. Готовим сервер установки.
1.1 На сервере виртуалок создаём сервер загрузок из того же CentOS-a с
отдельным VLAN-ом и IP адресом 172.17.17.254/24 - основная сетка целиком на MS,
лучше её не тревожить... Пока.
Сразу ставим туда демоны dhcpd, tftp, nfs, ntpd. Машины заливать будем по NFS - так привычнее.
1.2 Настраиваем на виртуальном сервере DHCP под сетевую загрузку Linux.
Правим /etc/dhcp/dhcpd.conf до примерно такого вида:
option domain-name "centos";
option domain-name-servers 172.17.17.254;
default-lease-time 600;
max-lease-time 7200;
authoritative;
log-facility local7;
subnet 172.17.17.0 netmask 255.255.255.0 {
range 172.17.17.100 172.17.17.199;
option routers 172.17.17.254;
filename "pxelinux.0";
next-server 172.17.17.254;
}
В общем - всё как обычно, кроме пары ключевых параметров: filename и
next-server. next-server задаёт IP-адрес tftp-сервера, а filename - файл в
папке загрузочных файлов (см следующий пункт).
включаем загрузку демона
chkconfig dhcpd on
и запускаем его
service dhcpd start
1.3 Настраиваем tftp
Правим файл /etc/xinetd.d/tftp. Точнее в строке disabled ставим значение "no" и
в строке server_args ставим те значения, что нам привычны, или оставляем
исходные, но запоминаем, куда они указывают. Мне, развлекающемуся с юнихами
года так с 1989, привычнее там видеть "-s -vv /tftpboot", что собственно там и
оказалось, после моих правок.
Создаём саму папку для загрузочных файлов (/tftpboot - из параметра server_args):
mkdir /tftpboot
Ставим пакет syslinux-а
yum install syslinux-4.02-7.el6.x86_64
И копируем PXE-шный загрузчкик в выбранное место:
cp /usr/share/syslinux/pxelinux.0 /tftpboot
И включаем демон:
chkconfig xinetd on
service xinetd restart
1.4 Настраиваем NFS
Создаём папку для дистрибутива
mkdir -p /pub/CentOS
Распаковываем туда дистрибутив
mkdir -p /mnt/cdrom
mount -o loop /путь-к-папке-с-изошником-CentOS/CentOS-6.3-x86_64-bin-DVD1.iso /mnt/cdrom
cd /pub/CentOS
cp -ra /mnt/cdrom/* .
umount /mnt/cdrom
mount -o loop /путь-к-папке-с-изошником-CentOS/CentOS-6.3-x86_64-bin-DVD2.iso /mnt/cdrom
cp -ra /mnt/cdrom/* .
umount /mnt/cdrom
Открываем к доступ к папке
echo '/pub *(ro,insecure,all_squash)' >> /etc/exports
chkconfig nfs on
service nfs restart
С общей подготовкой сервера - всё. Приступаем к специфичной части.
2. CentOS-овский загрузчик.
CentOS, разумеется, для загрузки с CD и DVD использует загрузчик isolinux
проекта Syslinux. А значит сделать файл конфигурации загрузки для pxelinux.0,
другой загрузчик этого же проекта - не просто, а очень просто.
Создаём папку /tftpboot/pxelinux.cfg и папку для дополнительных файлов загрузчика.
mkdir -p /tftpboot/pxelinux.cfg
Копируем туда под именем default файл конфигурации isolinux-а с дистрибутива CentOS...
cd /pub/CentOS/isolinux/
cp isolinux.cfg /tftpboot/pxelinux.cfg/default
[[/CODE]]
...и несколько файлов, используемых при загрузке.
cp boot.cat boot.msg grub.conf initrd.img splash.jpg TRANS.TBL vesamenu.c32 vmlinuz /tftpboot
Добавляем ссылку на файл автоматической инсталяции в параметры ядра.
В строки append initrd=initrd.img надо дописать ks=nfs:172.17.17.254:/pub/CentOS-conf/desktop.cfg,
где nfs - протокол, по которому надо брать файл конфигурации, 172.17.17.254 -
адрес сервера, /pub/CentOS-conf/desktop.cfg - полное имя файла.
Получается файл /tftpboot/pxelinux.cfg/default примерно такого вида:
default vesamenu.c32
#prompt 1
timeout 80
display boot.msg
menu background splash.jpg
menu title Welcome to CentOS 6.3!
menu color border 0 #ffffffff #00000000
menu color sel 7 #ffffffff #ff000000
menu color title 0 #ffffffff #00000000
menu color tabmsg 0 #ffffffff #00000000
menu color unsel 0 #ffffffff #00000000
menu color hotsel 0 #ff000000 #ffffffff
menu color hotkey 7 #ffffffff #ff000000
menu color scrollbar 0 #ffffffff #00000000
label linux
menu label ^Install or upgrade an existing system
menu default
kernel vmlinuz
append initrd=initrd.img ks=nfs:172.17.17.254:/pub/CentOS-conf/desktop.cfg
label vesa
menu label Install system with ^basic video driver
kernel vmlinuz
append initrd=initrd.img xdriver=vesa nomodeset ks=nfs:172.17.17.254:/pub/CentOS-conf/desktop.cfg
label rescue
menu label ^Rescue installed system
kernel vmlinuz
append initrd=initrd.img rescue
label local
menu label Boot from ^local drive
localboot 0xffff
label memtest86
menu label ^Memory test
kernel memtest
append -
3. Проблема совместимости 64-битной ОС с 32-битными приложениями.
При наличии 32-битных библиотек у 64-битной ОС ни каких проблем совместимости
нет. Но вот не задача: новый yum теперь 32-битные библиотеки ставить не будет.
Дело всё в параметре multilib_policy - в 5-ом CentOSе он имел значение all,
теперь - best. Как правильно побороть это на этапе установки - не знаю. В
Интернете нашёл, как побороть это по-быстрому (http://lists.centos.org/pipermail/centos/2011-July/114513.html).
Вытаскиваем из архива файл yuminstall.py во временную папку
mkdir /tmp/1
cd /tmp/1
rpm2cpio /pub/CentOS/Packages/anaconda-13.21.176-1.el6.centos.x86_64.rpm | cpio -id ./usr/lib/anaconda/yuminstall.py
Добавляем строку multilib_policy=all после строки [main], где-то 1252 строка
файла. Можно применить такой патчик:
cd usr/lib/anaconda/
cat <<EOP > patch
--- yuminstall.py.orig 2012-12-25 13:49:06.979604951 +0400
+++ yuminstall.py 2012-12-25 13:51:15.433740741 +0400
@@ -1250,6 +1250,7 @@
buf = """
[main]
+multilib_policy=all
installroot=%s
cachedir=/var/cache/yum
keepcache=0
EOP
patch < patch
Кладём подправленный файл в папку, откуда его точно заглотит инсталлятор:
mkdir /pub/CentOS/RHupdates/
cp yuminstall.py /pub/CentOS/RHupdates/
4. Создание конфигурации Kickstart.
Теперь надо создать конфигурационный файл инсталлятора. Сделать это проще всего
в графическом конфигураторе system-config-kickstart
yum install system-config-kickstart
system-config-kickstart
Запускается простой Х-овый интерфейс выбора параметров. Заполняем его по
своему усмотрению, ключевыми являются закладки "Метод установки" и "Сценарий
после установки".
Т.к. я изначально решил устанавливать по NFS в методе установки указываем
"Выполнить новую установку", "Установочный носитель" - NFS, "Сервер NFS" -
172.17.17.254 и "Каталог NFS" - /pub/CentOS. Содержимое закладки "Сценарий
после установки" можно скопировать из примера конфигурационного файла,
приведённого ниже, между полями %post и %end.
Пакеты выбираем по собственному вкусу, но для интеграции с Active Directory необходимы
samba-winbind
krb5-workstation
openldap-clients
их можно выбрать в "Выбор пакетов" -> "Базовая система" -> "Клиент каталогов".
На всякий случай, мало ли на какой каталог придётся переползать, я ставлю
вообще все пакеты этого подраздела.
Сохраняем файл конфигурации /pub/CentOS-conf/desktop.cfg - именно на него
ссылаются параметры ks из п.2.
У меня файл /pub/CentOS-conf/desktop.cfg получился таким (он содержит
комментарии на русском, их лучше удалить перед использованием - не хватало ещё
глюков из-за кириллицы):
#platform=x86, AMD64, or Intel EM64T
#version=DEVEL
# Firewall configuration - Внутри локалки firewall по большей части мешает.
firewall --disabled
# Install OS instead of upgrade
install
# Use NFS installation media
nfs --server=172.17.17.254 --dir=/pub/CentOS
# Root password
rootpw --iscrypted <зашифрованный пароль>
# System authorization information
auth --useshadow --passalgo=md5 --enablecache
# Use text mode install
text
# Run the Setup Agent on first boot
firstboot --disable
# System keyboard
keyboard ru
# System language
lang ru_RU
# SELinux configuration
selinux --disabled
# Installation logging level
logging --level=info
## Turnoff power after installation
# Удобно при большом кол-ве одновременно заливаемых компов - готовые выключены,
# и хорошо заметно, который можно уносить. Кикстарт не понимает всей прелести такого
# и этот параметр приходится дописывать руками.
poweroff
# System timezone
timezone Europe/Moscow
# Network information
network --bootproto=dhcp --device=eth0 --onboot=on
# System bootloader configuration
bootloader --location=mbr
# Clear the Master Boot Record
zerombr
# Partition clearing information
clearpart --all --initlabel
# Disk partitioning information.
# диски на компьютерах сейчас просто огромные, место жалеть не приходится
part /boot --fstype="ext4" --size=1024
part swap --fstype="swap" --recommended
part / --fstype="ext4" --size=131072
part /home --fstype="ext4" --grow --size=1
#
# А вот тут - самое основное
# Скрипт выполняется после всех основных действий по установки, в том числе
# после заливки софта, но chroot-нутым в подготовленную машину.
#
%post
# Скрипт создаётся в папке /tmp настраиваемого компьютера. Незачем ему там храниться.
rm -f $0
# Говорим yum-у и впредь ставить 32-битные модули вместе с 64-битными.
sed -i '/main/a multilib_policy=all' /etc/yum.conf
# Делаем группу wheels истинно админской, чтобы даже пароль не спрашивала при sudo
[ -d /etc/sudoers.d ] || mkdir /etc/sudoers.d
echo '%root ALL=(ALL) NOPASSWD: ALL' >> /etc/sudoers.d/rootgrp
chmod 0440 /etc/sudoers.d/rootgrp
assureFileFolder() {
local d=`dirname $1`;
[ -d "$d" ] && return
mkdir -p "$d"
}
# Конфигурация переключения раскладок клавиатуры в KDE
kxkbrcFile=/etc/skel/.kde/share/config/kxkbrc
assureFileFolder ${kxkbrcFile}
cat <<EOKXKBRC > ${kxkbrcFile}
[Layout]
DisplayNames=us,ru
LayoutList=us,ru
LayoutLoopCount=-1
Model=pc101
Options=grp_led:scroll,grp:caps_toggle,grp:alt_shift_toggle,grp:shifts_toggle
ResetOldOptions=true
ShowFlag=true
ShowLabel=true
ShowLayoutIndicator=true
ShowSingle=true
SwitchMode=Window
Use=true
EOKXKBRC
# Конфигурация локали KDE
kdeglobFile=/etc/skel/.kde/share/config/kdeglobals
assureFileFolder ${kdeglobFile}
cat <<EOKGL > ${kdeglobFile}
[Locale]
Country=ru
DateFormat=%A %d %B %Y
Language=ru
EOKGL
# Конфигурация правописания KDE.
kdespellCfg=/etc/skel/.kde/share/config/sonnetrc
assureFileFolder ${kdespellCfg}
cat <<EOKSPL > ${kdespellCfg}
[Spelling]
backgroundCheckerEnabled=true
checkUppercase=true
defaultClient=
defaultLanguage=ru
ignore_ru=
skipRunTogether=true
EOKSPL
# Конфигурация переключения раскладок клавиатуры в GNOME.
# Индикатор раскладок автоматически запускается только с GNOME 2.30,
# а текущий гном в дистрибутиве Центоса - 2.28...
# Так, что надо либо добавить сюда запуск индикатора, либо настраивать это руками...
# Но оба этих упражнения - в другой раз.
gnomekbdbase='/etc/skel/.gconf'
gnomekbdfile='desktop/gnome/peripherals/keyboard/kbd/%gconf.xml'
gkd=`dirname "${gnomekbdfile}"`
mkdir -p "${gnomekbdbase}/${gkd}"
d="${gkd}"; while [ "x${d}" != "x." ]; do touch ${gnomekbdbase}/$d/'%gconf.xml'; d=`dirname $d`; done
sed 's/ /\\t/g' <<EOGCONFKBD > ${gnomekbdbase}/${gnomekbdfile}
<?xml version="1.0"?>
<gconf>
<entry name="options" mtime="1357150396" type="list" ltype="string">
<!-- li type="string">
<stringvalue>terminate terminate:ctrl_alt_bksp</stringvalue>
</li -->
<li type="string">
<stringvalue>grp_led grp_led:scroll</stringvalue>
</li>
<li type="string">
<stringvalue>grp grp:caps_toggle</stringvalue>
</li>
<li type="string">
<stringvalue>grp grp:alt_shift_toggle</stringvalue>
</li>
<li type="string">
<stringvalue>grp grp:shifts_toggle</stringvalue>
</li>
</entry>
</gconf>
EOGCONFKBD
chmod 0644 ${kxkbrcFile} ${kdeglobFile} ${kdespellCfg} ${gnomekbdbase}/${gnomekbdfile}
# Создаём учётные записи для великих гуру - пусть имеют возможность зайти на любой компьютер
# Creation of admins
for u in guru0 guru1; do
useradd -m -p '*' -g wheel -G root $u
mkdir /home/$u/.ssh
touch /home/$u/.ssh/authorized_keys
chown -R $u:wheel /home/$u/.ssh
chmod -R go-rwx /home/$u/.ssh
done
# А сюда вставляем их публичные ключи SSH.
cat <<EOAK0 >> /home/guru0/.ssh/authorized_keys
EOAK0
cat <<EOAK1 >> /home/guru1/.ssh/authorized_keys
EOAK1
#
# У меня установка будет в текстовом режиме, а при этом система получает 3 уровень запуска - исправляем на 5-й.
sed -i 's/id:[3-5]:initdefault:/id:5:initdefault:/g' /etc/inittab
# Монтируем раздел с дистрибутивом
mkdir /tmp/pubDnld
mount -o ro 172.17.17.254:/pub /tmp/pubDnld
# Ставим дополнительные пакеты.
rpm -ivh /tmp/pubDnld/Adobe/adobe-release-x86_64-1.0-1.noarch.rpm
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-adobe-linux
rpm -i /tmp/pubDnld/Adobe/flash-plugin-11.2.202.258-release.x86_64.rpm
# Удаляем ненужные мне глобальные серверы времени и включаем себя как резервный сервер.
# Список серверов времени будем получать по DHCP.
sed -i.instbak '/^server /s/^/#/;/server[[:space:]]*127/s/^#//;/fudge[[:space:]]*127/s/^#//' /etc/ntp.conf
echo 'NTPSERVERARGS=iburst' >> /etc/sysconfig/network
# !!! А вот ради этого всё и затевается - ставим скрипт присоединения к домену
cp /tmp/pubDnld/CentOS-conf/adsjoin /etc/init.d/
chmod a+x /etc/init.d/adsjoin
# Включаем нужные сервисы и выключаем не нужные.
chkconfig kdump off
chkconfig ntpd on
chkconfig adsjoin on
%end
# Мой список устанавлеваемых пакетов. Создан system-config-kickstart-ом.
#
%packages
@additional-devel
@backup-client
@base
@basic-desktop
@cifs-file-server
@client-mgmt-tools
@console-internet
@core
@debugging
@desktop-debugging
@desktop-platform
@desktop-platform-devel
@development
@directory-client
@directory-server
@eclipse
@fonts
@general-desktop
@graphical-admin-tools
@graphics
@hardware-monitoring
@input-methods
@internet-applications
@internet-browser
@java-platform
@kde-desktop
@large-systems
@legacy-unix
@mysql
@mysql-client
@network-file-system-client
@nfs-file-server
@office-suite
@performance
@perl-runtime
@php
@print-client
@remote-desktop-clients
@ruby-runtime
@russian-support
@scientific
@server-platform-devel
@system-admin-tools
@technical-writing
@x11
ImageMagick
SDL-devel
cachefilesd
cmake
crypto-utils
dcraw
desktop-file-utils
docbook-utils-pdf
dump
evolution-exchange
expect
expect
gcc-java
glade3
glibc-utils
gnome-common
gnome-devel-docs
gnutls-devel
gtk2-devel-docs
hesinfo
hplip
hplip-gui
i2c-tools
icedtea-web
inkscape
kdebase-devel
kdebase-workspace-devel
kdegraphics-devel
kdelibs-apidocs
kdelibs-devel
kdemultimedia-devel
kdenetwork-devel
kdepim-devel
kdepimlibs-devel
kdesdk
kdesdk-devel
krb5-appl-clients
krb5-pkinit-openssl
krb5-workstation
ldapjdk
libXau-devel
libXaw-devel
libXinerama-devel
libXmu-devel
libXpm-devel
libXrandr-devel
libbonobo-devel
libreoffice-base
libreoffice-emailmerge
libreoffice-headless
libreoffice-javafilter
libreoffice-ogltrans
libreoffice-presentation-minimizer
libreoffice-report-builder
libreoffice-wiki-publisher
libudev-devel
libusb-devel
libuuid-devel
libxslt-devel
lm_sensors
mc
memtest86+
net-snmp-devel
netpbm-progs
nscd
nss-pam-ldapd
openldap-clients
pam_krb5
pam_ldap
perl-Test-Pod
perl-Test-Pod-Coverage
perl-suidperl
pexpect
php-mysql
planner
qt-doc
rpmdevtools
rpmlint
ruby-irb
samba
samba-winbind
screen
sox
startup-notification-devel
systemtap-grapher
taskjuggler
texinfo
tftp
thunderbird
xchat
xfig
xmlto-tex
xmltoman
xorg-x11-proto-devel
xrestop
xz-devel
%end
5. Скрипт интеграции в Active Directory.
Собственно, это то, ради чего писалась вся статья. Скрипт достаточно прост,
предназначен для использования теми, кто знает, что такое Active Directory и
имеет соответствующее звание - Ад-мин. Проверки входных данных есть, но очень слабые.
Скрипт выполняет ряд важных действий:
Выполняет синхронизацию времени компьютера с доменом. Адреса NTP
сервера(-ов) берутся из DHCP. Если синхронизация по чему либо не срабатывает -
скрипт запрашивает адрес NTP сервера.
Запрашивает имя компьютера и домена.
Прописывает эти значения в файлах конфигурации Самбы, Цербера и Лдапа.
Запрашивает имя админа и авторизуется им в Цербере.
Присоединяет комп к Active Directory.
Выполняет ряд дополнительных настроек компьютера.
Скрипт /pub/CentOS-conf/adsjoin
#!/bin/bash
# c#hkconfig: 345 98 1
### BEGIN INIT INFO
# Provides: adsjoin
# Default-Start: 3 4 5
# Default-Stop: 0 1 2 6
# Required-Start:
# Should-Start: $network
# Short-Description: Requests ADS data and joins domain
# Description: Asks user to enter ADS domain name, admin account and password.
# Configures system to use ADS and joins it.
### END INIT INFO
# Source function library.
. /etc/init.d/functions
FILENAME=/etc/sysconfig/adsjoin
[ -z "$HOME" ] && export HOME=/
usage() {
echo $"Usage: $0 {start|stop}"
}
prepareConfig() {
# Fix system hostname
fhn="${HOSTNAME,,}.${DOMAINNAME_FULL,,}"
sed -i.adsjoinbak '/^HOSTNAME=/s/=.*/='$fhn'/' /etc/sysconfig/network
hostname ${fhn}
# add this name to work
echo 127.0.0.1 ${fhn} ${fhn/.*} >> /etc/hosts
cat <<EOSMB >> /etc/samba/smb.conf
[global]
winbind refresh tickets = true
kerberos method = secrets and keytab
EOSMB
cat <<EOPWB >> /etc/security/pam_winbind.conf
krb5_auth = yes
cached_login = yes
krb5_ccache_type = FILE
EOPWB
# --winbindtemplateprimarygroup=users \\
basedn=$(echo ${DOMAINNAME_FULL,,} | sed 's/^\\.*/dc=/;s/\\.*$//;s/\\.\\.*/,dc=/g')
authconfig --update \\
--enablelocauthorize --enablecache \\
--enablekrb5realmdns --enablekrb5kdcdns \\
--ldapserver=ldap://${DOMAINNAME_FULL,,}/ --ldapbasedn=${basedn} \\
--enablemkhomedir --winbindtemplatehomedir=/home/%U --winbindtemplateshell=/bin/bash \\
--enablewinbindusedefaultdomain --enablewinbindauth --enablewinbind --enablewinbindoffline \\
--smbsecurity=ads --smbrealm=${DOMAINNAME_FULL}
--smbworkgroup=${DOMAINNAME_SHORT} --smbservers='*'
cat <<EOKRB > /etc/krb5.conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = ${DOMAINNAME_FULL}
dns_lookup_realm = true
dns_lookup_kdc = true
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
[domain_realm]
.${DOMAINNAME_FULL,,} = ${DOMAINNAME_FULL}
${DOMAINNAME_FULL,,} = ${DOMAINNAME_FULL}
EOKRB
}
askHostDom() {
local hn dn
while :; do
read -p 'Enter HOSTNAME without domain: ' hn
[ 0 -eq "$?" -a 4 -le ${#hn} -a ${#hn} -le 15 -a -z "$(expr "$hn" :
'[a-zA-Z0-9-]*\\(.*\\)')" ] &&
break;
echo "Wrong value ${hn}"
echo "You have to specify HOSTNAME 4 to 15 chars long."
echo "Only numbers, latin letter and '-' are allowed."
done
while :; do
read -p 'Enter DOMAINNAME: ' dn
[ 0 -eq "$?" -a 6 -le ${#dn} -a -z "$(expr "$dn" : '[.a-zA-Z0-9-]*\\(.*\\)')" ] &&
break;
echo "Wrong value ${dn}"
echo "You have to specify DOMAINNAME at least 6 chars long."
echo "Only latin letter, numbers, '.' and '-' are allowed."
done
HOSTNAME="$hn"
DOMAINNAME_FULL="${dn^^}"
DOMAINNAME_SHORT=${DOMAINNAME_FULL/.*}
}
askOrgDir() {
local od
echo 'Enter Organizational directory where to create computer'\\''s account.
Defaut is "Computers".'
echo 'Example: Site/Unit/Computers'
read -p 'Org. dir.: ' od
ORG_DIRECTORY="$od"
}
askAdmAccount() {
local un
while :; do
read -p "Enter Admin account of scpecified domain: " un
[ 0 -eq "$?" -a 1 -lt ${#un} ] && break;
echo "Wrong value ${un}"
echo "You have to specify admin account at least 1 char long."
done
ADMINACCOUNT="$un"
}
case "$1" in
start)
if [ `/usr/bin/id -u` -ne 0 ]; then
echo $"ERROR: Only root can run $0"
exit 4
fi
if [ ! -f /usr/bin/net ]; then
echo $"ERROR: samba is not installed"
exit 5
fi
args=""
if [ -f $FILENAME ] && [ ! -z "$(grep 'RUN_ADSJOIN=NO' $FILENAME)" ]; then
exit 0
fi
. /etc/profile.d/lang.sh
/usr/bin/plymouth --hide-splash
echo
echo '========================================================'
echo '============ Joining ADS'
echo '========================================================'
echo
NTPSRVSRC='DHCP'
NTPSRVS=$(sed -n 's/^server[[:space:]]*\\([^[:space:]]*\\).*/\\1/p'
/etc/ntp.conf| grep -v '^127' | sort -u)
while :; do
if [ -n "$NTPSRVS" ] ; then
if ntpdate -u -b $NTPSRVS
then
echo "Ok"
break;
else
echo "Can not synchronize to $NTPSRVS"
fi
fi
echo -e "WARNING!!!\\nNO working time servers specified by ${NTPSRVSRC}!"
read -p 'Enter NTP server(s) of domain: ' NTPSRVS
NTPSRVSRC=user
done
askHostDom
echo
prepareConfig
echo
service rsyslog restart
/sbin/chkconfig winbind on
RETVAL=255
HOME=/root
LOGNAME=root
USER=root
export HOME LOGNAME USER
cntr=3
while [ 0 -lt "$cntr" ]; do
askAdmAccount
if /usr/bin/kinit "${ADMINACCOUNT}"; then
RETVAL=0;
break;
fi
RETVAL=$?
echo "Error loging in domain ${DOMAINNAME_FULL}"
cntr=$(( $cntr - 1 ))
done
if [ "$RETVAL" -eq 0 ]; then
cntr=3
while [ 0 -lt "$cntr" ]; do
askOrgDir
if [ -n "${ORG_DIRECTORY}" ]; then
ADS_ORG="createcomputer='${ORG_DIRECTORY}'"
else
ADS_ORG=""
fi
( eval "set -x; /usr/bin/net ads join -d 1 -k ${ADS_ORG}" ) 2>&1 | tee /tmp/net-ads-join-$$-$cntr
# /usr/bin/net ads join -d 2 -k
RETVAL=$?
if [ "$RETVAL" -ne 0 ]; then
echo "WARNING!!! Join failed"
read -p 'Press Enter'
else
{
/usr/bin/net -d 1 ads keytab create
/sbin/service winbind restart
/usr/bin/net -d 1 ads dns register
} > /tmp/adsjoin-$$ 2>&1
break;
fi
cntr=$(( $cntr - 1 ))
done
fi
/usr/bin/plymouth --show-splash
# If adsjoin succeeded, chkconfig it off so we don't see the message
# every time about starting up adsjoin.
if [ "$RETVAL" -eq 0 ]; then
action "" /bin/true
else
action "" /bin/false
fi
/sbin/chkconfig adsjoin off
exit $RETVAL
;;
stop)
exit 0
;;
status)
/sbin/chkconfig --list adsjoin | grep on >/dev/null
RETVAL=$?
if [ "$RETVAL" -eq 0 ]; then
if [ ! -f $FILENAME ] || [ -z "$(grep 'RUN_ADSJOIN=NO' $FILENAME)" ]; then
echo $"adsjoin is scheduled to run"
else
echo $"adsjoin is not scheduled to run"
fi
else
echo $"adsjoin is not scheduled to run"
fi
exit 0
;;
restart | reload | force-reload | condrestart | try-restart)
usage
exit 3
;;
*)
usage
exit 2
;;
esac
Примечание:
Параметры "kerberos method" файла /etc/samba/smb.conf и "krb5_ccache_type"
файла /etc/security/pam_winbind.conf должны соответствовать друг другу, иначе
пользователь не сможет войти в систему.
Как ни странно, синхронизация времени часто сбивается в первые секунды после
получения адреса по dhcp - приходится вводить адреса серверов времени по
нескольку раз.
Скрипт перезапускает самбу и при его корректном завершении компьютер готов для
работы без перезагрузки.
6. Запускаем компьютеры
Подключаем к установочному VLAN-у коммутатор.
Запасаемся веером патч-кордов, кабелей питания и пр.
Подключаем сразу несколько компьютеров.
Запускаем на каждом новом компьютере загрузку по сети, по протоколу PXE.
У моих компьютеров сетевая загрузка была отключена, приходилось к каждому
подключать монитор и клавиатуру и немного донастраивать BIOS. Но в итоге,
параллельная подготовка компьютеров, включившая распаковку, заливку, введение в
домен и упаковку для отправки в дальний офис занимала менее часа на десяток
компьютеров, при том, что отдельный компьютер подготавливается около 15 минут.
Что не добавлено
1. Если какие-либо системные утилиты, работающие под уч. записью root и
понимающие, что такое Цербер, лезут к компьютерам домена, можно добавить в крон
ежечасный вызов
/usr/bin/net ads kerberos kinit -P
- инициализация Церберного билета уч. записи компьютера.
2. Можно добавить клиенту DHCP скрипт само-регистрации в DNS:
/etc/dhcp/dhclient.d/dnsreg.sh
#!/bin/sh
dnsreg_config() {
if [ -x /usr/bin/net ] ; then
/usr/bin/net ads dns register -P 2>&1 | logger -p daemon.info -t dhclient
fi
true
}
3. Не настроен сервер обновлений. У нас CentOS ставился для пробы перед
покупкой RedHat-а, обновлять его как-то не планировалось.
Благодарности
Руководству - за поставленную задачу и время, выделенное на её решение.
VMWare - за незначительное количество "особенностей" в эмуляторе, в целом
просто невероятным образом сократившего время отладки.
Microsoft - за незабываемое время проведённое в борьбе с Active Directory.
Wireshark.org - за отличный инструмент борьбы со всем этим счастьем.
|
| |
|
|
|
Установка Open Build Service и организация сборки пакетов для разных дистрибутивов Linux (доп. ссылка 1) |
Автор: Александр Молчанов
[комментарии]
|
| | В заметке рассказано, как при помощи открытой платформы Open Build Service
(OBS) упростить поддержку собственных репозиториев и организовать сборку
бинарных пакетов для популярных дистрибутивов Linux. При водится пример
установки в openSUSE 12.1 серверной части OBS и настройки клиентского окружения
для сборки пакетов в Ubuntu.
Установка сервера OBS
Прежде всего, нужно убедиться, что подключен репозиторий oss (это основной
репозиторий openSUSE, где находится только программное обеспечение с открытым
кодом). Он необходим для установки таких пакетов как Apache2, MySQL-server и т.д.
Добавим репозиторий для установки Open Build Server.
zypper addrepo download.opensuse.org/distribution/12.1/repo/oss/ openSUSE-12.1-Oss
sudo zypper addrepo zypper addrepo download.opensuse.org/repositories/openSUSE:/Tools:/Unstable/openSUSE_12.1/openSUSE:Tools:Unstable.repo
sudo zypper refresh
Теперь можно начать установку.
sudo zypper in obs-server obs-api
Установка потянет за собой пачку необходимых пакетов, таких как apache,
mysql-server, rubygems и т.д. Всего примерно на 90Мб.
Внесём пару изменений в файл конфигурации. Для этого открываем
/etc/sysconfig/obs-server, находим и приводим их к следующему виду строки:
OBS_SRC_SERVER="localhost:5352"
OBS_REPO_SERVERS="localhost:5252"
Теперь можно запускать сервисы:
rcobsrepserver start
rcobssrcserver start
rcobsscheduler start
rcobsdispatcher start
rcobspublisher start
Переходим к созданию баз данных и их наполнению:
mysql> create database api_production;
mysql> create database webui_production;
mysql> create user 'obs'@'%' identified by 'obspassword';
mysql> create user 'obs'@'localhost' identified by 'obspassword';
mysql> GRANT all privileges ON api_production.* TO 'obs'@'%', 'obs'@'localhost';
mysql> GRANT all privileges ON webui_production.* TO 'obs'@'%', 'obs'@'localhost';
mysql> FLUSH PRIVILEGES;
Настроим подключение к mysql API и WebUI. Для этого в любом удобном редакторе
открываем файлы /srv/www/obs/api/config/database.yml и
/srv/www/obs/webui/config/database.yml, находим и редактируем следующий блок:
production:
adapter: mysql2
database: api_production
username: obs
password: obspassword
Наполним базы и установим необходимые права на папки tmp и log
cd /srv/www/obs/api/
sudo RAILS_ENV="production" rake db:setup
sudo chown -R wwwrun.www log tmp
cd /srv/www/obs/webui/
sudo RAILS_ENV="production" rake db:setup
sudo chown -R wwwrun.www log tmp
Настроим Apache. Установим модуль apache2-mod_xforward. Для этого подключим ещё один репозиторий.
zypper addrepo download.opensuse.org/repositories/openSUSE:/Tools/SLE_11/ Tools-SLE
zypper refresh
zypper in apache2-mod_xforward
Подключим необходимые модули в /etc/sysconfig/apache2.
APACHE_MODULES="... passenger rewrite proxy proxy_http xforward headers"
Включим поддержку SSL и сгенерируем сертификаты:
APACHE_SERVER_FLAGS="-DSSL"
mkdir /srv/obs/certs
openssl genrsa -out /srv/obs/certs/server.key 1024
openssl req -new -key /srv/obs/certs/server.key -out /srv/obs/certs/server.csr
openssl x509 -req -days 365 -in /srv/obs/certs/server.csr -signkey /srv/obs/certs/server.key -out /srv/obs/certs/server.crt
cat /srv/obs/certs/server.key /srv/obs/certs/server.crt > /srv/obs/certs/server.pem
Установим use_xforward:true в /srv/www/obs/webui/config/options.yml и /srv/www/obs/api/config/options.yml
Теперь один очень важный нюанс. Открываем файл
/srv/www/obs/webui/config/environments/production.rb, ищем строчку
CONFIG['frontend_host'] = "localhost" и вместо localhost пишем имя сервера,
которое мы указали при генерации сертификата.
Если этого не сделать, то при попытке открыть WebUI или API, будете получать
ошибку "hostname does not match the server certificate".
Перезапускаем Apache и OBS для применения изменений:
rcapache2 restart
rcobsapidelayed restart
Проверяем работоспособность.
После перезапуска Apache API должен быть доступен по адресу servername:444.
WebUI будет доступен по адресу servername.
Логин и пароль по умолчанию Admin/opensuse.
Подробно останавливаться на использовании WebUI не буду. Интерфейс интуитивно понятный и удобный.
Использование клиента для сборки в OBS - OSC (openSUSE Build Service Commander)
Данный пакет доступен практически для всех дистрибутивов Linux. С его помощью
мы сможем создавать проекты, пакеты, загружать исходные файлы.
Для установки в Ubuntu выполним:
apt-get install osc
Следующим шагом нужно создать файл конфигурации, который необходим для работы с
нашим сервером. Создать его можно в автоматическом режиме, используя любую
команду osc, к примеру, osc ls. Но проще создать в корне домашней директории
файл .oscrc следующего содержания:
[general]
apiurl = https://servername:444
use_keyring = 0
[https://servername:444]
user = Admin
pass = opensuse
keyring = 0
Вместо servername пишем имя своего сервера. Имя опять же должно совпадать с
указанным во время создания сертификата, иначе получите ошибку "Certificate
Verification Error: Peer certificate commonName does not match host"
Проверяем подключение, выполнив команду osc ls (вывести листинг проектов).
Принимаем сертификат.
The server certificate failed verification
Would you like to
0 - quit (default)
1 - continue anyways
2 - trust the server certificate permanently
9 - review the server certificate
Enter choice [0129]: 2
Попробуем создать новый проект (MyProject - название вашего проекта):
osc meta prj -e MyProject
После этого откроется xml-файл конфигурации нового проекта, где вам нужно
будет, как минимум, указать Title и Description. Здесь же можно
раскомментировать строки, в которых указано под какую систему будут собираться
пакеты в данном проекте.
<project name="MyProject">
<title>MyProject</title>
<description>MyTestProject</description>
<person role="maintainer" userid="Admin" />
<person role="bugowner" userid="Admin" />
<publish>
<disable />
</publish>
<build>
<enable />
</build>
<debuginfo>
<disable />
</debuginfo>
<repository name="openSUSE_Factory">
<path project="openSUSE:Factory" repository="standard" />
<arch>x86_64</arch>
<arch>i586</arch>
</repository>
<repository name="openSUSE_11.2">
<path project="openSUSE:11.2" repository="standard"/>
<arch>x86_64</arch>
<arch>i586</arch>
</repository>
<repository name="openSUSE_11.1">
<path project="openSUSE:11.1" repository="standard"/>
<arch>x86_64</arch>
<arch>i586</arch>
</repository>
<repository name="Fedora_12">
<path project="Fedora:12" repository="standard" />
<arch>x86_64</arch>
<arch>i586</arch>
</repository>
<repository name="SLE_11">
<path project="SUSE:SLE-11" repository="standard" />
<arch>x86_64</arch>
<arch>i586</arch>
</repository>
</project>
Создание пакета происходит по такой же схеме (MyProject - название вашего
проекта, MyPackage - ваш новый пакет)
osc meta pkg -e MyProject MyPackage
Теперь, когда проект и пакет созданы, нам нужно отправить на сервер файлы
исходников, из которых будут собираться бинарные пакеты.
Сначала создадим локальную копию проекта у себя на рабочей машине.
osc co MyProject
После этого должна появиться иерархия каталогов MyProject/MyPackage. Помещаем
свои файлы исходников в каталог MyPackage, после чего добавляем их в контроль
версий командой:
osc add MyProject/MyPackage /MyFiles
и закачиваем на сервер
osc ci MyProject/MyPackage -m "Your comment" --skip-validation
Результат сборки смотрим командой
osc results MyProject/MyPackage
Теперь приведу отдельно краткий перечень команд для работы с проектами и пакетами из консоли.
Вывести список проектов:
osc ls
Создать проект:
osc meta prj -e ProjectName
Создать пакет:
osc meta pkg -e ProjectName PackageName
Удалить проект или пакет:
osc rdelete ProjectName/PackageName
Сделать локальную копию проекта:
osc co ProjectName
Добавить новые файлы в контроль версий:
osc add ProjectName/PackageName/YourFiles
Удалить исходные файлы:
osc rremove ProjectName PackageName SourceName
osc update ProjectName
Подтвердить изменения в проекте:
osc ci ProjectName -m "Your comment" --skip-validation
Подтвердить изменения в пакете:
osc ci Project Name/Package Name -m "Your comment"
Показать результат сборки:
osc results Project Name/Package Name
Показать лог сборки (выполнять в каталоге пакета):
osc buildlog Platform Arch (osc buildlog xUbuntu_12.04 i586)
|
| |
|
|
|
Получение списка внешних .deb зависимостей для исполняемого файла |
Автор: Карбофос
[комментарии]
|
| | Если программисту необходимо создать установочный пакет для Debian-подобных
систем, необходимо указывать список внешних зависимостей (дополнительных
пакетов необходимых для полноценного запуска бинарного файла).
Команда для определения списка зависимостей с выдачей информации о версиях внешних deb пакетов:
dpkg -l $( dpkg -S $( ldd YourBinaryOrLib | awk '{print $3}' ) | awk '{{sub(":"," ")} print $1}' )
где YourBinaryOrLib - имя собранного бинарного файла
|
| |
|
|
|
Проверка Linux-системы на наличие следов взлома (доп. ссылка 1) (доп. ссылка 2) |
[комментарии]
|
| | В процессе разбора истории со взломом kernel.org было выявлено, что
атаковавшим удалось установить вредоносное ПО на Linux-машины некоторых
разработчиков, используя которое были перехвачены ключи доступа. В списке
рассылки разработчиков ядра Linux опубликована краткая инструкция по
проверке целостности системы и выявлению следов активности злоумышленников.
Суть опубликованных рекомендаций изложена ниже.
Одним из очевидных способов гарантировать чистоту системы от активности
злоумышленников является переустановка системы с нуля. Но прежде чем прибегнуть
к переустановке, следует убедиться, что система действительно поражена. Чтобы
обеспечить выявление скрывающих свое присутствие руткитов проверку желательно
выполнять загрузившись с LiveCD.
1. Установка и запуск специализированных инструментов для выявления руткитов, например,
chkrootkit, ossec-rootcheck и rkhunter.
При запуске утилиты rkhunter возможно ложное срабатывание на некоторых системах
с Debian. Вызывающие ложные срабатывания факторы описаны в файле /usr/share/doc/rkhunter/README.Debian.gz
2. Проверка корректности сигнатур для всех установленных в системе пакетов.
Для дистрибутивов на базе RPM:
rpm --verify --all
Для дистрибутивов с dpkg следует использовать скрипт:
dpkg -l \*|while read s n rest; do if [ "$s" == "ii" ]; then echo $n;
fi; done > ~/tmp.txt
for f in `cat ~/tmp.txt`; do debsums -s -a $f; done
Утилиту debsums следует установить отдельно:
sudo apt-get install debsums
Вывод измененных файлов:
debsums -ca
Вывод измененных файлов конфигурации:
debsums -ce
Посмотреть пакеты без контрольных сумм:
debsums -l
Другой вариант контрольных сумм для файлов в Debian:
cd /var/lib/dpkg/info
cat *.md5sums | sort > ~/all.md5
cd /
md5sum -c ~/all.md5 > ~/check.txt 2>&1
3. Проверка на то, что установленные пакеты действительно подписаны
действующими цифровыми подписями дистрибутива.
Для систем на базе пакетного менеджера RPM:
for package in `rpm -qa`; do
sig=`rpm -q --qf '%{SIGPGP:pgpsig}\n' $package`
if [ -z "$sig" ] ; then
# check if there is a GPG key, not a PGP one
sig=`rpm -q --qf '%{SIGGPG:pgpsig}\n' $package`
if [ -z "$sig" ] ; then
echo "$package does not have a signature!!!"
fi
fi
done
4. При выявлении подозрительных пакетов их желательно удалить и установить заново.
Например, для переустановки ssh в дистрибутивах на базе RPM следует выполнить:
/etc/init.d/sshd stop
rpm -e openssh
zypper install openssh # для openSUSE
yum install openssh # для Fedora
Рекомендуется проделать эти операции, загрузившись с LiveCD и используя опцию 'rpm --root'.
5. Проверка целостности системных скриптов в /etc/rc*.d и выявление
подозрительного содержимого в /usr/share. Эффективность выполнения проверок
можно гарантировать только при загрузке с LiveCD.
Для выявления директорий в /usr/share, которые не принадлежат каким-либо
пакетам в дистрибутивах на базе RPM можно использовать следующий скрипт:
for file in `find /usr/share/`; do
package=`rpm -qf -- ${file} | grep "is not owned"`
if [ -n "$package" ] ; then
echo "weird file ${file}, please check this out"
fi
done
В Debian для определения какому пакету принадлежит файл следует использовать "dpkg-query -S":
for file in `find /usr/share/GeoIP`; do
package=`dpkg-query -S ${file} 2>&1 | grep "not found"`
if [ -n "$package" ] ; then
echo "weird file ${file}, please check this out"
fi
done
Аудит suid root программ:
find / -user root -perm -4000 -ls
6. Проверка логов на предмет наличия нетипичных сообщений:
* Проверить записи в wtmp и /var/log/secure*, обратив особое внимание на
соединения с внешних хостов.
* Проверить упоминание обращения к /dev/mem;
* В /var/log/secure* посмотреть нет ли связанных с работой ssh строк с не
текстовой информацией в поле версии, которые могут свидетельствовать о попытках взлома.
* Проверка удаления файлов с логами, например, может не хватать одного файла с ротацией логов.
* Выявление подозрительных соединений с локальной машины во вне, например,
отправка email или попытки соединения по ssh во время вашего отсутствия.
* Анализ логов пакетного фильтра с целью выявления подозрительных исходящих
соединений. Например, даже скрытый руткитом бэкдор может проявить себя в логах
через резолвинг DNS. Общая рекомендация сводится к контролю на промежуточном
шлюзе соединений во вне для только принимающих внешние соединения машин и
соединений из вне для только отправляющих запросы клиентских машин.
7. Если в процессе проверки обнаружен факт проникновения злоумышленника следует
сделать копию дисковых разделов на отдельный носитель при помощи команды "dd" с
целью более подробного анализа методов проникновения. Только после этого можно
полностью переустановить всю систему с нуля. Одновременно нужно поменять все
пароли и ключи доступа, уведомив об инциденте администраторов серверов, на
которых осуществлялась удаленная работа.
|
| |
|
|
|
Конвертация СentOS 6 в Scientific Linux 6 (доп. ссылка 1) (доп. ссылка 2) |
Автор: StormBP
[комментарии]
|
| | Миграция с СentOS на Scientific Linux может быть целесообразна в свете
доступности Scientific Linux 6.1, в то время как выпуск СentOS 6.1 лишь в планах.
Перед началом миграции выполняем полное резервное копирование.
1. Устанавливаем репозитории Scientific Linux:
rpm -ivh --force http://ftp.scientificlinux.org/linux/scientific/6x/x86_64/os/Packages/sl-release-6.1-2.x86_64.rpm
2. Чистим yum:
yum clean all
3. Обновляем сам yum и rpm:
yum update yum* rpm*
4. Обновляем систему:
yum update
5. Удаляем лишнее:
rpm -e centos-release
rpm -e yum-plugin-fastestmirror
6. Синхронизируем пакеты из репозиториев:
yum distro-sync
7. Переустанавливаем пакеты вендора CentOS:
Выводим список пакетов:
rpm -qa --qf "%{NAME} %{VENDOR}\n"|grep CentOS
Для каждого пакета из списка выполняем:
yum reinstall пакет
8. Перезагружаем систему:
reboot
|
| |
|
|
|
Удаленная установка CentOS или Fedora (доп. ссылка 1) |
Автор: Andrew Okhmat
[комментарии]
|
| | Хочу поделиться способом удаленной установки CentOS
или Fedora. Используя возможности инсталлятора anaconda, можно упростить
процедуру инсталляции или обновления операционной системы на удаленном сервере.
Цитата из русскоязычной страницы проекта раскрывает некоторые возможности
anaconda, которые мы будем использовать:
"Anaconda является достаточно современным установщиком. Он позволяет выполнять
установку с локальных или удаленных источников, таких как CD и DVD, образы
размещенных на жестких дисках, NFS, HTTP и FTP. Может быть создан сценарий
установки с помощью kickstart для обеспечения полностью автоматической
установки, позволяющей дублировать систему на ряд компьютеров. Установка может
быть запущена через VNC на компьютерах без монитора."
Все описанное ниже подходит для любого дистрибутива Linux, использующего для
загрузки grub. Примеры из статьи тестировались на grub 0.97, но после небольших
изменений можно использовать и с grub2. Более того, этот способ использовался
мной для замены FreeBSD на Linux, после установки grub в качестве загрузчика
вместо стандартного Boot Manager.
Подготовка состоит из 4-х шагов:
Определение сетевых настроек сервера;
Загрузка образов для выбранной OS;
Подготовка конфигурации и добавление ее в grub.conf;
Перезагрузка сервера и подключение к нему через VNC.
Определение сетевых настроек сервера
Нам понадобится IP адреса сервера, шлюза и DNS. Также понадобится MAC адрес
основной сетевой карты. Его важно указывать в параметрах, если на сервере 2
сетевых карты, иначе есть вероятность, что инсталлятор выберет вовсе не ту,
которая нам нужна. Для определения сетевых настроек можно воспользоваться
следующими командами:
ifconfig
ip route show
cat /etc/sysconfig/network-scripts/ifcfg-eth0
cat /etc/sysconfig/network
cat /etc/resolv.conf
в нашем примере это:
Ip 172.17.17.232
Gateway 172.17.17.1
DNS 172.17.17.1
MAC 52:54:00:4a:25:b5
Загрузка образов
CentOS и Fedora используют разные образы для старта инсталлятора. Надо выбрать
соответствующие образы, в зависимости от того какой дистрибутив мы собираемся
установить. Кроме того, если вы хотите установить 32х битную версию, то в url
вам нужно заменить x86_64 на i386.
Образы для centos 5.6 (x86_64):
wget -O /boot/vmlinuz_remote http://mirrors.supportex.net/centos/5.6/os/x86_64/isolinux/vmlinuz
wget -O /boot/initrd_remote.img http://mirrors.supportex.net/centos/5.6/os/x86_64/isolinux/initrd.img
Образы для fedora 15 (x86_64):
wget -O /boot/vmlinuz_remote http://download.fedora.redhat.com/pub/fedora/linux/releases/15/Fedora/x86_64/os/isolinux/vmlinuz
wget -O /boot/initrd_remote.img http://download.fedora.redhat.com/pub/fedora/linux/releases/15/Fedora/x86_64/os/isolinux/initrd.img
Подготовка конфигурации и добавление ее в grub.conf
Укажем ранее сохраненные ip адреса сервера, шлюза и днс, а также url, откуда
инсталлятор будет скачивать rpm пакеты. Дополнительные параметры, например,
отсутствие монитора, выбор определенной сетевой карты и пароль для VNC.
Если /boot раздел на диске не первый, то поправьте строчку root(hd0,0), она
должна соответствовать номеру раздела.
Добавляем эти строки в grub.conf для Centos 5.6:
title Remote Install
root (hd0,0)
kernel /vmlinuz_remote lang=en_US keymap=us \
method=http://mirrors.supportex.net/centos/5.6/os/x86_64/ \
vnc vncpassword=SuperSecret ip=172.17.17.232 netmask=255.255.255.0 gateway=172.17.17.1 \
dns=172.17.17.1 noselinux ksdevice=52:54:00:4a:25:b5 headless xfs panic=120
initrd /initrd_remote.img
Или для fedora 15:
title Remote Install
root (hd0,0)
kernel /vmlinuz_remote lang=en_US keymap=us \
method=http://download.fedora.redhat.com/pub/fedora/linux/releases/15/Fedora/x86_64/os/ \
vnc vncpassword=SuperSecret ip=172.17.17.232 netmask=255.255.255.0 gateway=172.17.17.1 \
dns=172.17.17.1 noselinux ksdevice=52:54:00:4a:25:b5 headless xfs panic=120
initrd /initrd_remote.img
Предполагается, что наша конфигурация идет вторым пунктом меню. Мы указали grub
попробовать загрузить ее один раз. Если что-то пойдет не так, вернемся к ранее
установленному дистрибутиву после перезагрузки, через 120 секунд.
# echo 'savedefault --default=1 --once' | grub --batch
Более подробно о всех загрузочных параметрах анаконды вы можете прочитать на
этой страничке: http://fedoraproject.org/wiki/Anaconda/Options
Перезагрузка сервера и подключение к нему по VNC
Перезагружаем сервер и ждем, когда он начнет отвечать на ping. Потребуется
некоторое время, пока загружаются дополнительные пакеты и можно будет
присоединиться через vnc. Если канал не очень быстрый, это может занять до
20-30 минут.
Подключаемся к серверу и делаем все как на локальной консоли:
vncviewer 172.17.17.232:1
Если вы работаете из Windows, то можете воспользоваться TightVNC.
Советы
VNC-сервер запускается без keep-a-live, поэтому если вы подключаетесь через
nat, то при долгой неактивности есть шанс потерять сессию и больше не
восстановить ее. Лучше отключаться от vnc, а потом подключаться повторно, если
VNC консоль долго не используется.
Не стоит форматировать бутовый раздел как ext4, хотя это предлагают по
умолчанию как Fedora, так и Centos. В некоторых случаях установленная
операционная система отказывается загружаться с этого раздела. И хотя это
бывает крайне редко, но лучше не рисковать.
При установке Fedora в минимальной конфигурации сервис network оказывается не
активированным. Это можно починить, добавив в параметры
anacond-ы sshd и sshpw=password, указав свой пароль для ssh. После окончания
интерактивной установки, перед самой перезагрузкой инсталлятора, зайти по ssh
на удаленный сервер и активировать сервис network:
# chroot /mnt/sysimage
# chkconfig network on
# exit
Ссылки
How to use Kickstart (Anaconda's remote control)
Anaconda
Anaconda Boot Options
Install Fedora 14 Linux without a monitor (headless), keyboard and CD/DVD
Installing Fedora Using PXE Images
|
| |
|
|
|
Подготовка патчей для пакетов Debian GNU/Linux (доп. ссылка 1) |
[комментарии]
|
| | При возникновении желания отправить исправление мейнтейнеру пакета Debian
возникает вопрос, как правильно изменить код пакета и как отправить патч.
1. Получаем последнюю версию пакета с исходным кодом и устанавливаем
необходимые для его сборки зависимости.
Одним из методов является использование утилиты dget, входящей в состав пакета
devscripts, которая позволяет напрямую загрузить пакет с исходным кодом по URL,
который можно найти в dsc-файле, который можно загрузить из сисетмы трекинга пакетов.
Если попытаться использовать apt-get, временами может быть выведено
предупреждение, что пакет обслуживается в системе управления версиями:
$ apt-get source wordpress
[...]
NOTICE: 'wordpress' packaging is maintained in the 'Git' version control system at:
git://git.debian.org/git/collab-maint/wordpress.git
[...]
В этом случае следует использовать утилиту debcheckout для загрузки кода
напрямую из репозитория системы управления версиями:
$ debcheckout wordpress
declared git repository at git://git.debian.org/git/collab-maint/wordpress.git
git clone git://git.debian.org/git/collab-maint/wordpress.git wordpress ...
Cloning into wordpress...
Дополнительно рекомендуется установить мета-пакет packaging-dev, установка
которого повлечет за собой установку наборов инструментов, полезных для
разработчиков пакетов.
2. Внесение изменений.
Для фиксации факта начала работы над внесением изменения в пакет пользователем,
не являющимся мейнтейнером, выполним команду (NMU = Non Maintainer Upload):
$ dch --nmu
Этот шаг также позволит гарантировать, что после сборки пакета мы не перетрем
загруженный ранее оригинальный пакет с исходными текстами.
2.1. Изменяем служебные файлы пакета.
Заходим в поддиректорию debian и правим при необходимости нужные файлы.
Внесенные изменения отражаем путем выполнения команды dch (если изменений
несколько утилиту нужно запустить несколько раз).
2.2. Изменяем файлы оригинальной программы, поставляемой в пакете.
При изменении файлов upstream-проекта имеет значение какой из форматов
задействован в используемом пакете с исходными текстами ("1.0, "3.0 (quilt)"
или "3.0 (native)", разница сводится к формированию одного большого патча или
размещении каждого патча в отдельном файле), а также тип системы патчей (можно
посмотреть запустив what-patch). В данной заметке рассматривается ситуация
использования рекомендованного формата "3.0 (quilt)" (рекомендации будут
работать и для формата "1.0", но для этого нужно настроить ~/.quiltrc в
соответствии с инструкцией /usr/share/doc/quilt/README.source)
Применяем в коду оригинального проекта все патчи, выполнив:
$ quilt push -a
Если патчей в пакете ещё нет, создаем вручную поддиректорию debian/patches:
$ mkdir debian/patches
2.2.1. Импортируем существующий патч.
Если изменения уже оформлены в upstream-проекте в виде патча, то импортировать
данный патч можно следующим образом:
$ quilt import -P fix-foobar.patch /tmp/patch
Importing patch /tmp/patch (stored as fix-foobar.patch)
$ quilt push
Applying patch fix-foobar.patch
[...]
Now at patch fix-foobar.patch
Опция "-P" позволяет выбрать на свое усмотрение имя для сохранения патча в
директории debian/patches/. После выполнения указанных действий патч будет
добавлен в директорию debian/patches/series, но пока не будет по умолчанию
применен к коду.
2.2.1. Создаем новый патч.
Если изменения еще не оформлены в виде патча, нужно указать quilt о
необходимости создать новый патч:
$ quilt new fix-foobar.patch
Patch fix-foobar.patch is now on top
Далее указываем все файлы, которые будут изменены в результате нашей
деятельности. Для каждого изменяемого файла запускаем "quilt add", после чего
quilt создаст для каждого из этих файлов резервную копию, на основе оценки
изменений с которой в последствии будет сгенерирован патч. Теперь правим любым
удобным способом нужные файлы. Если файлы планируется отредактировать вручную,
вместо "quilt add" можно запустить "quilt edit".
$ quilt edit foobar.c
File foobar.c added to patch fix-foobar.patch
После того как все изменения внесены, генерируем патч:
$ quilt refresh
Refreshed patch fix-foobar.patch
3. Тестируем внесенные изменения
Собираем измененный пакет:
$ debuild -us -uc
проверяем его работоспособность, установив в систему через dpkg или debi.
4. Генерируем патч для отправки мейнтейнеру.
После выполнения всех ранее указанных шагов в директории должно находиться два
.dsc-файла, изначальный и новый, например:
$ cd ..
$ ls wordpress_*.dsc
../wordpress_3.0.5+dfsg-1.1.dsc
../wordpress_3.0.5+dfsg-1.dsc
Сгенерировать патч для отправки мейнтейнеру можно командой debdiff:
$ debdiff wordpress_3.0.5+dfsg-1.dsc wordpress_3.0.5+dfsg-1.1.dsc >/tmp/wp-debdiff
Для отправки патча /tmp/wp-debdiff мейнтейнеру можно использовать утилиту
bugreport, указав в роли тега "patch". Для автоматизации отправки можно
использовать утилиту nmudiff.
Если работа осуществлялась с копией из системы управления исходными текстами
(выполняли debcheckout), то вместо debdiff можно сгенерировать diff-файл
встроенными средствами используемой системы контроля версий (git diff, svn diff
и т.п). В случае использования распределенной системы контроля версий (git,
bzr, mercurial) возможно следует оформить все модификации в виде отдельного
набора изменений. Вместо отправки одного патча, возможно потребуется отправить
серию патчей или отправить URL на изменений в публичном репозитории.
|
| |
|
|
|
Компиляция Linux-ядра под заданный процессор в Debian/Ubuntu (доп. ссылка 1) |
Автор: andrewlap
[комментарии]
|
| | Пример компиляции ядра в таких дистрибутивах как Debian и Ubuntu с целью
задействования всех возможных оптимизаций для текущего процессора (core-duo).
Все произведённые действия подойдут для ubuntu 9.10 - 10.10
Для начала загрузим исходные тексты ядра и заголовочные файлы:
sudo aptitude install linux-source-2.6 linux-headers
Установим утилиты для компиляции ядра
sudo aptitude install build-essential kernel-package libncurses-dev
Полученное ядро нужно распаковать:
cd /usr/src/
sudo tar -xjf linux-source-*
Все операции с ядром производятся в корне директории с исходными текстами ядра,
поэтому недолго думая переходим туда:
cd /usr/src/linux-source-*
Создадим файл конфигурации текущего ядра командой
sudo make oldconfig
Эта команда создаст файл .config, где будут указаны опции ядра, используемого в
данной системе. Эти настройки будут основой для наших настроек. Приступим к
конфигурации ядра:
sudo make menuconfig
С помощью этой утилиты указываем необходимые нам опции.
Обращаю ваше внимание на следующую опцию:
Processor type and features ---> Processor family
Здесь выбираем свой процессор. Остальные опции, которые мы взяли из ядра
идущего с дистрибутивом вполне работоспособны для большинства применений,
поэтому изменяйте их по своему усмотрению, или оставляйте как есть.
Далее, выполним команду, которая удалит файлы (если они имеются), оставшиеся от
предыдущей компиляции:
sudo make-kpkg clean
Далее компилируем ядро командой:
sudo nice -n 19 make-kpkg --initrd --append-to-version=-mykernel kernel_image kernel_headers
"nice -n 19" понизит приоритет компиляции на 19 пунктов
Ключ "-append-to-version" используется, чтобы добавить к имени файла образа
ядра, который мы получим после компиляции, строку "-mykernel", чтобы было проще
идентифицировать свое ядро.
И, через несколько минут/часов или может у кого то и дней, мы получим
оптимизированное для нашей архитектуры ядро. На Celeron 3.06GHz это заняло два
с половиной часа.
Если всё пройдёт удачно, в итоге в /usr/src/ получим два deb-пакета
linux-headers-*.deb и linux-image-*.deb, которые следует установить в систему:
sudo dpkg -i linux-headers-*.deb linux-image-*.deb
Установщик также обновит конфигурацию grub и поставит новое ядро во главе
списка. Теперь можно перезагрузить в систему с новым ядром!
Дополнение от pavlinux:
При необходимости можно внести изменения в используемые опции компиляции для
gcc c оптимизацией под нужный процессор. Опции задаются через переменные
окружения HOSTCFLAGS и KBUILD_CFLAGS, например:
export HOSTCFLAGS="-O99 -mtune=native -funroll-all-loops"
export KBUILD_CFLAGS="-O99 -mtune=native -funroll-all-loops"
или могут быть заданы в основном Makefile через переменные "HOSTCFLAGS" и
"HOSTCXXFLAGS". В этих настройках нельзя указывать флаги оптимизации под
конкретный процессор, можно использовать отлько общие параметры оптимизации,
такие как -06/-O99, -frecord-gcc-switches, -g0 -funroll-all-loops,
-ftree-vectorize, -fno-inline-functions-called-once, -fmerge-all-constants и
так далее.
Для тонкой оптимизации под конкретный процессор нужно менять параметры в
arch/x86/Makefile (под 32 бита в arch/x86/Makefile_32.cpu)
там следует найти свой процессор, после строки "export BITS" есть тройка ifeq-else-endif
Дописывать можно к последнему KBUILD_CFLAGS. Тут можно всё, кроме
FPU/SSE/MMX/3DNOW, "-mcmodel=kernel" менять нельзя.
|
| |
|
|
|
Удаление ненужных автоматически установленных пакетов в Debian и Ubuntu (доп. ссылка 1) |
[комментарии]
|
| | В процессе установки пакета, вместе с ним часто устанавливается и несколько
зависимостей. Если после экспериментов данный пакет будет удален через команду
"apt-get/aptitude remove" или через GUI-интерфейс, то дополнительно
установленные зависимости останутся в системе, несмотря на то, что вызвавший их
установку пакет уже удален и зависимости больше не используются. Для чистки
подобных зависимостей удобно использовать команду "apt-get autoremove".
Рассмотрим процесс чистки на примере.
$ sudo apt-get install pino
...
The following NEW packages will be installed:
libdbusmenu-glib1 libgee2 libindicate4 libnotify1 notification-daemon pino
...
Как видимо вместе с пакетом pino в систему будет установлено 4 новые библиотеки
и демон нотификации. Всем этим пакетам будет присвоен флаг автоматической
установки "automatically installed"
Например:
$ aptitude show libdbusmenu-glib1
Package: libdbusmenu-glib1
New: yes
State: installed
Automatically installed: yes
Version: 0.3.7-1
...
Посмотреть все автоматически установленные пакеты можно командой:
$ apt-mark showauto
После удаления пакета pino через apt-get или synaptic все ранее установленные с
ним дополнительные пакеты останутся в системе (aptitude удалит лишние
зависимости при следующем запуске).
$ sudo apt-get remove pino
...
The following packages were automatically installed and are no longer required:
notification-daemon libdbusmenu-glib1 libnotify1 libgee2 libindicate4
Use 'apt-get autoremove' to remove them.
Для оценки более не используемых зависимостей и удаления тех, что имеют метку
автоматической установки можно использовать команду:
$ sudo apt-get autoremove
The following packages will be REMOVED:
libdbusmenu-glib1 libgee2 libindicate4 libnotify1 notification-daemon
0 upgraded, 0 newly installed, 5 to remove and 219 not upgraded.
After this operation, 1307 kB disk space will be freed.
Функцию удаления группы автоматически установленных пакетов можно использовать
и при выполнении ручной чистки системы, для чего нужно вручную пометить
ненужные пакеты, которые потом будут удалены при выполнении "apt-get
autoremove", если они не присутствуют в списке зависимостей других пакетов. Это
существенно снизит риск удаления нужного пакета по ошибке.
Например, помечаем вручную библиотеку libxml-simple-perl:
$ sudo apt-mark markauto libxml-simple-perl
или
$ sudo aptitude markauto libxml-simple-perl
Тем не менее при маркировке нужно быть осторожным и не помечать первичные
пакеты. Например, пометив пакет gnome и выполнив "apt-get autoremove" будет
удалены все связанные с GNOME пакеты.
Отменить пометку можно командой unmarkauto:
$ sudo apt-mark unmarkauto gnome-session gnome-panel
|
| |
|
|
|
Пересборка пакетов в Debian GNU/Linux (доп. ссылка 1) |
[комментарии]
|
| | Иногда в Debian Stable нужно установить более новую версию пакета из Testing,
который не был перенесен в backports.
1. Загрузка пакета с исходными текстами
Проверяем чтобы в /etc/apt/sources.list были активированы репозитории deb-src:
deb-src http://ftp.debian.org/debian unstable main contrib non-free
deb-src http://ftp.debian.org/debian testing main contrib non-free
deb-src http://ftp.debian.org/debian stable main contrib non-free
Для загрузки самых свежих исходных текстов пакета "publican" следует выполнить
sudo apt-get update
apt-get source publican
Если необходимо установить исходные тексты пакета из определенной ветки
дистрибутива, например, Debian Testing, что является разумным компромиссом
между свежестью и стабильностью:
apt-get source publican/testing
Исходные тексты будут сохранены в текущую директорию:
ls -dF publican*
publican-2.1/ publican_2.1-2.dsc
publican_2.1-2.debian.tar.gz publican_2.1.orig.tar.gz
В случае, когда пакет отсутствует в репозиториях, загрузить пакет можно командой:
dget -u dsc-url
где dsc-url представляет собой URL к .dsc-файлу с описанием параметров пакета,
опция "-u" указывает на отмену стадии проверки валидности пакета. Для получения
утилиты dget нужно установить пакет.
2. Установка зависимостей
Для установки пакетов, необходимых для сборки заданной программы, следует
использовать команду "apt-get build-dep пакет", например:
apt-get build-dep publican/testing
Если пакет взят не из репозитория, то для выполнения аналогичного действия в
директории с исходными текстами пакета нужно выполнить команду:
dpkg-checkbuilddeps
которая выведет список задействованных при сборке пакетов, которые затем нужно
установить через "apt-get install".
3. Изменение исходных текстов перед сборкой
При необходимости код собираемой программы можно модифицировать, например,
приложить дополнительный патч или отредактировать debian/rules. При внесении
изменений во избежание конфликтов рекомендуется изменить номер версии,
используя команду dch из пакета devscripts:
dch --local имя
где "имя" является коротким именем, идентифицирующим вносящего изменение. После
выполнения команды будет предложено указать комментарий для помещения в debian/changelog.
4. Сборка пакета
Для сборки в директории с распакованным кодом выполняем команду debuild из пакета devscripts.
cd publican-2.1
debuild -us -uc
где опции "-us -uc" указывают пропустить связанный с проверкой сигнатур шаг, в
случае если у сборщика отсутствует валидный GPG-ключ, совпадающий с данными
вначале файла changelog.
После завершения сборки в предыдущей директории можно будет найти бинарный пакет:
cd ..
ls -dF publican*
publican-2.1/ publican_2.1-2rh1.dsc
publican_2.1-2.debian.tar.gz publican_2.1-2rh1_i386.changes
publican_2.1-2.dsc publican_2.1-2rh1_source.changes
publican_2.1-2rh1_all.deb publican_2.1.orig.tar.gz
publican_2.1-2rh1.debian.tar.gz
|
| |
|
|
|
Экономия дискового пространства путем исключения маловажных файлов через dpkg (доп. ссылка 1) |
[комментарии]
|
| | В составе большинства deb-пакетов содержатся данные, которые никогда не
понадобятся пользователю, например, файлы с переводами элементов интерфейса на
другие языки или документация. Начиная с версии 1.15.8 в dpkg появилась
возможность не устанавливать лишние данные.
Для контроля за тем, какую информацию установить, а какую нет, предусмотрены
две опции: --path-include=маска и --path-exclude=маска. В качестве маски могут
быть использованы любые glob-выражения, допустимые в shell (man glob).
Так как обычно для установки используются высокоуровневые утилиты, подобные
apt, вызывать dpkg вручную и задавать дополнительные опции не совсем удобно.
Поэтому логичнее изменить методику вызова dpkg в системе, создав
соответствующую инструкцию в каталоге /etc/dpkg/dpkg.cfg.d/.
Например, создадим файл etc/dpkg/dpkg.cfg.d/excludes, в котором зададим маски
для включаемых и исключаемых каталогов, на примере ограничения установки
локалей и системных руководств:
# Не устанавливаем локали за исключением русских:
path-exclude=/usr/share/locale/*
path-include=/usr/share/locale/ru/*
path-include=/usr/share/locale/locale.alias
# Не устанавливаем переводы системных руководств, за исключением перевода на русский язык
path-exclude=/usr/share/man/*
path-include=/usr/share/man/man[1-9]/*
path-include=/usr/share/man/ru*/*
Следует иметь в виду, что все ранее установленные части пакета, подпадающие под
маску исключения, будут удалены только после обновления пакета. Т.е. если
необходимо освободить место немедленно, не дожидаясь появления обновлений,
можно инициировать переустановку всех пакетов в системе:
aptitude reinstall
или
apt-get --reinstall install
|
| |
|
|
|
Настройка альтернатив в Debian на примере смены браузера по-умолчанию в GNOME (доп. ссылка 1) |
Автор: Сергей Афонькин
[комментарии]
|
| | В GNOME браузером по-умолчанию является Epiphany и если открывать html-файлы с
диска, то они откроются в Epiphany. Для того, чтобы файлы открывались в
Iceweasel (Firefox) достаточно в командной строке выполнить:
sudo update-alternatives --config gnome-www-browser
1 /usr/bin/iceweasel
* 2 /usr/bin/epiphany-gecko
3 /usr/bin/konqueror
4 /usr/bin/midori
5 /usr/bin/opera
6 /usr/bin/google-chrome
Отобразились 2 альтернативы, выступающие в роли "gnome-www-browser".
Нажмите enter, чтобы сохранить значение по умолчанию "*", или введите выбранное
число: вводим цифру 1 и нажимаем Enter.
Можно также задать браузер для X-ов, следующей командой:
sudo update-alternatives --config x-www-browser
Другие полезные альтернативы (полный список можно посмотреть в директории /etc/alternatives/):
update-alternatives --list java
update-alternatives --list editor
update-alternatives --list pager
update-alternatives --list ftp
Для установки альтернативы для определенной группы можно использовать такую команду:
update-alternatives --set editor /usr/bin/emacs
в данном случае устанавливаем в качестве текстового редактора по умолчанию emacs
Для добавления собственной альтернативы можно использовать команду:
update-alternatives --install /usr/bin/vi2 editor /usr/local/bin/vim2 50
где, имя итогового альтернативного файла /usr/bin/vi2, editor - имя группы,
/usr/local/bin/vim2 - путь к добавляемой в число альтернатив программе, 50 - приоритет.
Для удаления:
update-alternatives --remove editor /usr/bin/vi2
|
| |
|
|
|
Обновление Fedora/RHEL/Suse/Mandriva без обновления ядер |
Автор: Artem Tashkinov
[комментарии]
|
| | Очень многие пользователи и системные администраторы используют дистрибутивы
Fedora/RHEL/Suse/Mandriva с ядром собственной сборки и поэтому обновление или
установка ядра от вендора не является желанным.
Избежать установки ядер при обновлении можно следующим образом. Создайте файл
kernel.spec, определяющий пакет с заведомо более новой фиктивной версией ядра,
(данный вариант на 100% работает только на Fedora/RHEL) со следующим содержимым:
Name: kernel
Summary: The Linux kernel
Version: 2.6.100
Release: 1
License: GPLv2+
Group: System Environment/Kernel
URL: http://www.kernel.org/
Packager: Artem S. Tashkinov
%description
The kernel package contains the Linux kernel (vmlinuz), the core of any
Linux operating system. The kernel handles the basic functions
of the operating system: memory allocation, process allocation, device
input and output, etc.
%prep
%build
%install
%clean
%files
%changelog
* Thu Jul 8 2010 Artem S. Tashkinov <birdie@permonline.ru> 2.6.100
- First indefinite release (unless kernel developers
change kernel versioning)
Затем соберите и установите его с помощью следующих команд:
$ rpm -ba kernel.spec
$ rpm -ivh ~/rpmbuild/RPMS/`rpm --eval '%_target_cpu'`/kernel-2.6.100-1.i686.rpm
|
| |
|
|
|
Установка сервера для 1С:Предприятия 8 и PostgreSQL 8.4 на Ubuntu 10.04 LTS |
Автор: Игорь Вершинин
[комментарии]
|
| | Задача, казалось, несложной - необходимо установить выделенный сервер на новой
версии Ubuntu, самостоятельно скомпилировать PostgreSQL из исходников,
установить далее две версии серверной части 1С:Предприятия 8.1 и 8.2. Но, при
решении задачи всплыло много нюансов.
Брать готовый бинарник от EterSoft'а оказалось неверным - общая компиляция под
Mandriva, затем препарирование полученного через alien. Нарушается логика
расположения файлов конфигурации и библиотек в Ubuntu, плюс отставание от
текущего положения дел (уже вышла версия 8.4.4 PostgreSQL, а на ftp.etersoft.ru
лежит лишь 8.4.2). Я понимаю, что лучшее враг хорошего, но хочется самому
делать выводы, что лучшее, и что хорошее. Поэтому принято решение
самостоятельно собрать PostgreSQL с необходимыми патчами.
Серверные части 1С:Предприятия также написаны в расчете на некий
средне-универсальный дистрибутив Linux, но тут хотя бы честно. Все ставится в
/opt, конфигурационные файлы прописываются в /etc/init.d и домашней директории
пользователя usr1cv82(1). Да и изменить мы ничего не можем - доступа к
исходникам нет.
Итак. Собираем сам сервер. Корпус, материнская плата, процессор, планки памяти,
два одинаковых жестких диска... Я собрал программный RAID1 (зеркало) для
надежности хранения (все-таки собирается для "продакшн"), но это совершенно не
обязательно. Что обязательно - установка 64-битной версии, объем оперативной
памяти для любой СУБД критичен (а 32-битные версии ограничены 4 гигабайтами),
благо это сейчас совершенно недорого. Я установил 8 гигабайт. В общем,
выбирайте сами. Привод оптических дисков в сервер ставить смысла нет никакого,
загрузку можно провести через USB flash, а на будущее выделенному серверу
привод совершенно ни к чему - все необходимое докачивается из репозитариев или
копируется через утилиту scp.
Скачиваем образ сервера с http://www.ubuntu.com, там же подробнейшая инструкция
как сделать загружаемую USB flash из-под любой операционной системы.
Загружаемся, инсталлируем. Несколько обязательный комментариев. В принципе,
ничего сложного в процессе инсталляции нет, все подробно расписано. Но!
* Выбираем обязательно русский язык, чтобы сервер автоматически настроился на
использование русской локали (принципиально для первоначального запуска
патченной версии PostgreSQL, да и системные сообщения на русском не лишние)
* Обязательное подключение к Интернету. По ходу дела, программа инсталляции
несколько раз докачивает недостающие пакеты, плюс нам нужен доступ к
репозитариям для дальнейшей работы.
* В момент попытки получения ip-адреса по dhcp процедуру лучше прервать
(особенно если в это время в сети работает dhcp-сервер) или на следующем экране
выбрать "Возврат". Все-таки сервер, должен иметь фиксированный адрес и имя.
Задаем его самостоятельно.
* Из предлагаемого дополнительного софта ставим лишь OpenSSH, остальное после и самостоятельно.
После инсталляции перезагрузка, вытаскиваем "флэшку" (она больше не нужна), не
забываем в BIOS'е установить AHCI - жесткие диски работают быстрее.
После новой установки первым делом:
sudo apt-get install mc
Надо как-то работать в консоли. Затем:
sudo visudo (или воспользуемся редактором из mc)
Добавляем директиву NOPASSWD:ALL для группы %admin, приведя последнюю строку к виду:
%admin ALL=(ALL) NOPASSWD:ALL
Это нам необходимо, чтобы каждый раз не вводить свой пароль для sudo. Так как к
консоли сервера кроме администратора никто доступ не имеет (теоретически), то и
безопасность это не нарушает. Правилом хорошего тона считается разлогинится
после работы. А доступ к консоли без знания пароля получить нельзя, так что
если кто и узнает ваш пароль, то и команду sudo выполнит легко. Таким образом,
ничего кроме дополнительной потери времени и нервов постоянное парольное
подтверждение не дает.
Обновляем установку:
apt-get update
apt-get upgrade
Перезагружаемся, потому как ядро обновится на более свежее.
Устанавливаем NTP-сервер. Время на всех серверах должно быть синхронизировано,
иначе в логах потом не разберешься.
apt-get install ntp
В /etc/ntp.conf исправляем строку "server ntp.ubuntu.com" на вашу. Если в
локальной сети есть уже работающий сервер времени (у нас это сервер, отвечающий
за proxy), то укажите его адрес. Через некоторое время сервер синхронизирует
время. Если нет, оставьте, пусть компании Canonical будет приятно.
Подготовительные работы окончены. Приступаем к сборке. Скачиваем с
http://v8.1c.ru/overview/postgres_patches_notes.htm три патча:
1c_FULL_84-0.19.2.patch
postgresql-1c-8.4.patch
applock-1c-8.4.1.patch
Пусть вас не смущает то, что патчи для версии 8.4.1 - они отлично становятся и
на более старшие версии PostgreSQL (в рамках версии 8.4). Все минорные
исправления не затрагивают того, что патчит фирма "1С".
На сервере в домашнем каталоге пользователя-администратора создаем директорию
"1С". Копируем в нее любым удобным для нас способом (я использовал scp со своей
рабочей станции, можно перекинуть через собственный ftp или через "флэшку") эти
три патча. Переименовываем их, добавляя перед названием "20-",
"21-" и "22-", т. е. приводим их к виду:
20-1c_FULL_84-0.19.2.patch, 21-postgresql-1c-8.4.patch, 22-applock-1c-8.4.1.patch
Переходим в директорию "1С" и скачиваем туда исходники PostgreSQL:
apt-get source postgresql
После скачивания архивы автоматически распакуются, будут наложены специфичные
для Ubuntu патчи (что очень хорошо, так как итоговая сборка будет "родной").
Входим в этот каталог. Затем копируем наши патчи в каталог "/debian/patches/".
Далее нам предстоит исправить три файла, ответственных за правильную сборку
пакета. Все три файла содержаться в каталоге "debian".
Файл "changelog". Отвечает за правильное наименование пакетов после сборки.
Добавляем туда следующие строки в начало файла любым текстовым редактором
(например, через mc):
postgresql-8.4 (18.4.4-ailant-0ubuntu10.04) lucid; urgency=low
* Apply 1C patch for PostgreSQL (from 8.4.1 version)
- add mchar, fulleq, fasttrun
-- Igor Vershinin <ivershinin@ailant.com.ru> Fri, 04 Jun 2010 00:53:03 +0400
Версию устанавливаем как 18.4.4, чтобы в дальнейшем она самостоятельно не
обновилась при апдейте системы. Если будут наши исправления, то всегда возможно
скачать новые исходники и повторить с ними операцию, описанную в этой статье,
увеличив номер сборки (например, 18.4.4-ailant-1ubuntu10.04).
Следующий файл "control". Необходимо добавить зависимость от библиотеки
"libicu42" (требуется для патча от "1С"). В секции "Build-Depends" (в начале
файла) в конце списка добавляем ", libicu-dev".
Целиком строка будет выглядеть вот так:
bison, flex, docbook-utils, openjade, docbook, libicu-dev
И последний файл "postgresql-contrib-8.4.install". В него необходимо добавить
строки с именами 1С-овских модулей: mchar, fulleq и fasttrun. После строк:
usr/lib/postgresql/8.4/lib/pg_stat_statements.so
usr/lib/postgresql/8.4/lib/citext.so
usr/lib/postgresql/8.4/lib/btree_gin.so
надо добавить:
usr/lib/postgresql/8.4/lib/mchar.so
usr/lib/postgresql/8.4/lib/fulleq.so
usr/lib/postgresql/8.4/lib/fasttrun.so
На этом операцию по адаптации можно считать законченной. У нас получился
правильно "патченный", родной для операционной системы исходник. Аналогично
можно подготовить версию для любой debian-совместимой ОС.
К сожалению, исправления трех файлов (кроме последнего) нельзя сделать через
patch-файл в автоматическом режиме. Патчи применяются уже после того, как
скачиваются зависимости и определяется имя пакета.
Готовые патчи и исправленные файлы можно взять также на нашем ftp-сайте
ftp://ftp.ailant.com.ru/pub/soft/postgresql-8.4.4-1C-ubuntu/ . Там же в
каталоге bin лежит собранный пакет PostgreSQL для Ubuntu 10.04 (x86_64). Это
если кому не хочется самостоятельно собирать.
Компиляция может пройти двумя способами. Оба несложных. В первом случае идем "в
лоб" и компилируем в рабочей системе, но куча зависимостей будет загружена, что
не есть хорошо, для "продакш"-системы. Поэтому воспользуемся пакетом
"pbuilder". В этом случае компиляция будет проходить в специально созданном
chroot-окружении, и все изменения будут проходить в нем, не трогая рабочую
систему. Более подробно об этом можно почитать в https://wiki.ubuntu.com/PbuilderHowto
apt-get install pbuilder cdbs
Все, что ему необходимо, он сам вытянет по зависимостям. Второй пакет необходим
для компиляции. Далее:
pbuilder create
Создаем специальное окружение для компиляции. В этот момент много скачивается
из репозиториев. У меня с первого раза почему-то не сработало, был сбой и
pbuilder закончил работу с ошибкой. Я не стал разбираться отчего это произошло,
просто повторно выполнил команду создания.
В дальнейшем рекомендуется перед сборкой давать команду:
pbuilder update
для обновления окружения новыми пакетами.
Переходим в каталог исходников и
pdebuild
Сборка началась. В первый раз по зависимостям будет вытянуто около 500
мегабайт, надо быть к этому готовым. Либо собирать на unlim-канале (дома,
например). В дальнейшем пакеты кешируются. У нас используется пакет apt-proxy,
который также умеет это делать. Для предприятий, где работает не один сервер,
очень рекомендую.
Сборка проходит ровно и спокойно. По окончанию в каталоге
"/var/cache/pbuilder/result" будут лежать собранные пакеты.
Продолжаем. Необходимо установить несколько пакетов для поддержки работы PostgreSQL:
apt-get install postgresql-common postgresql-client-common libicu42 libossp-uuid16
Затем, собственно, ставим свежесобранный PostgreSQL:
dpkg -i libpq5_18.4.4-ailant-0ubuntu10.04_amd64.deb
dpkg -i libpgtypes3_18.4.4-ailant-0ubuntu10.04_amd64.deb
dpkg -i postgresql-client-8.4_18.4.4-ailant-0ubuntu10.04_amd64.deb
dpkg -i postgresql-8.4_18.4.4-ailant-0ubuntu10.04_amd64.deb
dpkg -i postgresql-contrib-8.4_18.4.4-ailant-0ubuntu10.04_amd64.deb
Остальные пакеты не нужны для работы "1С:Предприятия 8". В этот момент сервер
СУБД будет запущен, также будет проведена первичная инициализация базы данных.
Осталось сделать несколько штрихов.
Проверим, чтобы PostgreSQL всегда запускался после перезагрузки:
update-rc.d postgresql-8.4 defaults
Сделаем два симлинка, без которых "1С:Предприятие" не сможет работать с СУБД:
ln -s /usr/lib/locale/en_US.utf8 /usr/lib/locale/en_US
ln -s /usr/share/locale/en /usr/share/locale/en_US
Временно (правда, у меня осталось на постоянно) исправим правила доступа к
СУБД. В конфигурационном файле "/etc/postgresql/8.4/main/pg_hba.conf" исправим
в строке "host all all 0.0.0.0/0" md5 на trust. На момент начальной отладки так
гораздо проще, в дальнейшем (после запуска всей системы) выбирайте сами уровень
собственной защиты.
Все PostgreSQL собран и запущен. Устанавливаем "1С:Предприятие". Так как в
настоящее время версия 8.2 является основной, то начнем с нее. После установим
версию 8.1 для поддержки старых конфигураций (которые еще не перевели на новую платформу).
Переписываем с диска ИТС (скачиваем с сайта 1С) последнюю версию (на момент
написания статьи это 8.2.11.229) для архитектуры debian x86_64 (ведь именно
этот сервер мы ставили). Копируем на нашем сервере в папку "1С" в
домашней директории. Последовательно запускаем:
dpkg -i 1c-enterprise82-common_8.2.11-229_amd64.deb
dpkg -i 1c-enterprise82-server_8.2.11-229_amd64.deb
В принципе, достаточно. Пакеты "-nls" - это языковая поддержка. Нам она не
нужна, русский язык есть в основной поставке. Пакет "-ws" - это веб-сервисы.
Если нужны, то поставьте. Мне пока без надобности.
После инсталляции надо проверить наличие пользователя user1cv82 в файле
/etc/passwd и его домашнего каталога в /home. Именно в нем и будут храниться
специфические параметры запуска сервера. Дальше необходимо доставить несколько пакетов:
apt-get install imagemagick msttfcorefonts libgsf-1-114 texlive-binaries
Проверяем все ли библиотеки установлены:
/opt/1c/v8.2/x86_64/utils/config_server
Утилита должна отработать без сообщений. Если написала, что что-то не
установлено, надо доставить. Обычно она указывает не на название пакетов, а на
недостающие файлы. Узнать в каком они пакете можно через "apt-file search".
Делаем возможность запуска после перезагрузки и запускаем:
update-rc.d srv1cv82 defaults
invoke-rc.d srv1cv82 start
Должно быть "ОК". Если нет, то скорее всего необходимые порты уже заняты. Надо
проверить чем. Дальше проверяем, что все процессы запущены нормально:
ps aux | grep 1c
От имени пользователя "usr1cv82" должно быть запущено три процесса: ragent,
rmngr и rphost. После имен процессов идут номера портов, на которых они
работают. Если процесса не три, а один (такое почему-то иногда бывает, но
только при первоначальном запуске), то делаем:
invoke-rc.d srv1cv82 stop
Удаляем каталог ".1cv82" в домашней директории пользователя usr1cv82. И
перезапускаем сервер заново. Должно стать все нормально.
Аналогично устанавливаем и сервер "1С:Предприятия 8.1". Но с небольшими
изменениями. Во-первых, из-за ошибки скрипта домашний каталог пользователя
"usr1cv81" будет установлен неверно, необходимо исправить его, отредактировав
"/etc/passwd" и исправив путь на "/home/usr1cv81", по аналогии с пользователем
"usr1cv82". Затем создать собственно сам каталог в директории "home" и
установить на него владельца "usr1cv81" и группу "grp1cv81". Во-вторых,
необходимо исправить порты, на которых будет работать сервер. Редактируем
"/etc/init.d/srv1cv81", убирая комментарии со строк и добавляя номера:
SRV1CV8_PORT=11540
SRV1CV8_REGPORT=11541
SRV1CV8_RANGE=11560:11691
т. е. мы использовали порты на 10000 больше, чем порты по умолчанию. Дальше
запускаем сервер, проверяем, если надо удаляем директорию ".1cv81" в домашнем
каталоге пользователя usr1cv81.
Потом тестовая перезагрузка. Готово. На выделенном сервере работает
самостоятельно собранная версия PostgreSQL, а также два сервера
"1С:Предприятия" версий 8.1 и 8.2.
Работоспособность проверяется с любой windows-машины, подключением консоли
серверов "1С:Предприятия" к нашему серверу на заданный порт (1540 или 11540).
Кстати, при использовании в конфигурациях "1С:Предприятия 8" управляемых
блокировок, скорость работы СУБД PostgreSQL в ряде случаев бывает даже выше,
чем у MS SQL (под которую изначально и был заточен 1С). Но это все относится к
правильной оптимизации запросов, которые в версии 8.2 можно очень гибко настраивать.
И последнее. Несмотря на то, что сейчас все наши сервера работают под Ubuntu,
раньше использовалась Fedora. Пример сборки для нее (и похожих дистрибутивов)
есть в каталоге ftp://ftp.ailant.com.ru/pub/soft/postgresql-8.3.7-1C-fedora/ .
Там лежит как пример готовый spec-файл для сборки. Собирается все через mock (http://fedoraproject.org/wiki/Projects/Mock).
Дополнение: Компилировать PostgreSQL необходимо с ключом
"--disable-integer-datetimes", иначе при загрузке данных в СУБД через
1С:Предприятие 8 может вылететь ошибка про timestamp. Плюс вышло обновление
патча 0.19.3 от 1С с небольшим инзменением,вместо (строка 2118):
+LANGUAGE C RETURNS NULL ON NULL INPUT IMMUTABLE;
используется
+LANGUAGE C RETURNS NULL ON NULL INPUT VOLATILE;
|
| |
|
|
|
Автоматизированная сборка загрузочного DVD из CD-образов Russian Fedora 13 |
Автор: Igor
[комментарии]
|
| | Ниже представлен вариант автоматизированной сборки DVD из CD-образов Russian
Remix Fedora (RFRemix). Тестировалось под OS RFRemix 11 и RFRemix 12.
Изложенные в инструкции действия следует выполнять под пользователем root.
Создаем каталог куда копируем 6-ть образов CD (закачены с yandex):
RFRemix-13-i386-disc1.iso
RFRemix-13-i386-disc2.iso
RFRemix-13-i386-disc3.iso
RFRemix-13-i386-disc4.iso
RFRemix-13-i386-disc5.iso
RFRemix-13-i386-disc6.iso
В каталоге создаем bash-скрипт MakeDVD.sh со следующим содержимым:
#!/bin/bash
#Script create DVD ISO-image from CD ISO-images for Fedora 13
RFREMIX13_MEDIA_ID="1274745691.442497"
MAX_DISC_NUM=6
RFREMIX_DISC_NAME="RFRemix-13-i386-disc"
COMPS_FILE="RFRemix-13-comps.xml"
RPM_DIR="Packages"
DVD_LABEL="RFRemix 13"
RFRENIX_VER11=`((cat /etc/system-release) | awk '{ if(match($0,"11")!=0) print "11" }')`
RFRENIX_VER12=`((cat /etc/system-release) | awk '{ if(match($0,"12")!=0) print "12" }')`
CURDIR="$(pwd)"
COMPSFILE=$CURDIR"/srcdvd/repodata/"$COMPS_FILE
SRCDVDDIR="$CURDIR""/srcdvd"
DVDISOFILE="$CURDIR""/dvd-iso/RFRemix-13-i386-DVD.iso"
cleandata()
{
echo
echo 'Cleaning temporary data...'
echo
for ((i=1;i<=$MAX_DISC_NUM;i++)) ; do
if [ -a ./mnt/disc$i ]; then
umount -f ./mnt/disc$i ;
fi
done
rm -f -R ./mnt
rm -f -R ./srcdvd
}
echo
echo 'Create directories...'
echo
cleandata
rm -f -R ./dvd-iso
mkdir ./srcdvd
mkdir ./dvd-iso
mkdir ./mnt
for ((i=1;i<=$MAX_DISC_NUM;i++)) ; do mkdir ./mnt/disc$i ; done
echo
echo 'Mount a CD ISO-image...'
echo
for ((i=1;i<=$MAX_DISC_NUM;i++)) ; do mount -t iso9660 ./$RFREMIX_DISC_NAME$i.iso ./mnt/disc$i -o loop ; done
echo
echo 'Data preparation...'
echo
echo 'Copying packages from disc 1...'
cp -f -R ./mnt/disc1/* ./srcdvd
cp -f ./mnt/disc1/.discinfo ./srcdvd
rm -f ./srcdvd/repodata/*
cp ./mnt/disc1/repodata/*-comps.xml ./srcdvd/repodata/$COMPS_FILE
rm -f `(find ./srcdvd/*.TBL ./srcdvd/ | grep .TBL)`
for ((i=2;i<=$MAX_DISC_NUM;i++)) ; do
echo 'Copying packages from disc '$i'...';
cp ./mnt/disc$i/$RPM_DIR/* ./srcdvd/$RPM_DIR;
done
if [ "v"$RFRENIX_VER12 == "v12" ] && [ ! -e /usr/lib/python2.6/site-packages/createrepo/createrepo_rfremix12.patch ]; then
echo
echo 'Patching utility createrepo...'
echo
cp -f ./createrepo_rfremix12.patch /usr/lib/python2.6/site-packages/createrepo
cp /usr/lib/python2.6/site-packages/createrepo/__init__.py /usr/lib/python2.6/site-packages/createrepo/__init__OLD.py
patch -i /usr/lib/python2.6/site-packages/createrepo/createrepo_rfremix12.patch /usr/lib/python2.6/site-packages/createrepo/__init__.py
fi
if [ "v"$RFRENIX_VER11 == "v11" ] && [ ! -e /usr/lib/python2.6/site-packages/createrepo/createrepo.patch ]; then
echo
echo 'Patching utility createrepo...'
echo
cp -f ./createrepo.patch /usr/lib/python2.6/site-packages/createrepo
cp /usr/lib/python2.6/site-packages/createrepo/__init__.py /usr/lib/python2.6/site-packages/createrepo/__init__OLD.py
patch -i /usr/lib/python2.6/site-packages/createrepo/createrepo.patch /usr/lib/python2.6/site-packages/createrepo/__init__.py
fi
echo
echo 'Creation of information repositories...'
echo
createrepo -g "$COMPSFILE" --baseurl "media://"$RFREMIX13_MEDIA_ID -d -o "$SRCDVDDIR" "$SRCDVDDIR"
echo
echo 'Checksum repodata/repomd.xml...'
echo
SHA256REPO=`(sha256sum ./srcdvd/repodata/repomd.xml) | awk '{ print $1 }'`
REPOINFO="repodata/repomd.xml = sha256:""$SHA256REPO"
(cat ./mnt/disc1/.treeinfo) | awk '{ if(match($0,"repodata")==0) print; else print "'"$REPOINFO"'" }' > ./srcdvd/.treeinfo
echo
echo 'Creating a bootable DVD ISO-image...'
echo
mkisofs -r -T -joliet-long -V "$DVD_LABEL" -b isolinux/isolinux.bin -c isolinux/boot.cat \
-no-emul-boot -boot-load-size 4 -boot-info-table -o "$DVDISOFILE" "$SRCDVDDIR" 2> ./make_iso.log
cleandata
ls -l ./dvd-iso
echo
echo 'Create DVD ISO completed!'
echo
В каталоге размещаем два patch-файла для createrepo
(пакет должен быть установлен). Патчи необходимы, иначе
мы получим пропуск некоторых rpm-пакетов.
Файл createrepo.patch (для RFRemix 11):
*** ./__init__.py 2010-05-29 22:51:15.000000000 +0300
--- ./__init__update.py 2010-05-30 07:26:02.000000000 +0300
***************
*** 72,78 ****
self.oldpackage_paths = [] # where to look for the old packages -
self.deltafile = 'prestodelta.xml.gz'
self.num_deltas = 1 # number of older versions to delta (max)
! self.max_delta_rpm_size = 100000000
self.update_md_path = None
self.skip_stat = False
self.database = False
--- 72,78 ----
self.oldpackage_paths = [] # where to look for the old packages -
self.deltafile = 'prestodelta.xml.gz'
self.num_deltas = 1 # number of older versions to delta (max)
! self.max_delta_rpm_size = 1000000000L
self.update_md_path = None
self.skip_stat = False
self.database = False
***************
*** 588,594 ****
"""
# duck and cover if the pkg.size is > whatever
! if int(pkg.size) > self.conf.max_delta_rpm_size:
if not self.conf.quiet:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % pkg)
--- 588,594 ----
"""
# duck and cover if the pkg.size is > whatever
! if long(pkg.size) > self.conf.max_delta_rpm_size:
if not self.conf.quiet:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % pkg)
***************
*** 638,644 ****
for d in self.conf.oldpackage_paths:
for f in self.getFileList(d, 'rpm'):
fp = d + '/' + f
! if int(os.stat(fp)[stat.ST_SIZE]) > self.conf.max_delta_rpm_size:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % f)
continue
--- 638,644 ----
for d in self.conf.oldpackage_paths:
for f in self.getFileList(d, 'rpm'):
fp = d + '/' + f
! if long(os.stat(fp)[stat.ST_SIZE]) > self.conf.max_delta_rpm_size:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % f)
continue
Файл createrepo_rfremix12.patch (для RFRemix 12):
*** ./__init__.py 2010-05-30 09:28:40.000000000 +0300
--- ./__init__update_f12.py 2010-05-30 09:38:01.000000000 +0300
***************
*** 74,80 ****
self.oldpackage_paths = [] # where to look for the old packages -
self.deltafile = 'prestodelta.xml.gz'
self.num_deltas = 1 # number of older versions to delta (max)
! self.max_delta_rpm_size = 100000000
self.update_md_path = None
self.skip_stat = False
self.database = False
--- 74,80 ----
self.oldpackage_paths = [] # where to alook for the old packages -
self.deltafile = 'prestodelta.xml.gz'
self.num_deltas = 1 # number of older versions to delta (max)
! self.max_delta_rpm_size = 1000000000L
self.update_md_path = None
self.skip_stat = False
self.database = False
***************
*** 613,619 ****
"""
drpm_pkg_time = time.time()
# duck and cover if the pkg.size is > whatever
! if int(pkg.size) > self.conf.max_delta_rpm_size:
if not self.conf.quiet:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % pkg)
--- 613,619 ----
"""
drpm_pkg_time = time.time()
# duck and cover if the pkg.size is > whatever
! if long(pkg.size) > self.conf.max_delta_rpm_size:
if not self.conf.quiet:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % pkg)
***************
*** 671,677 ****
for f in self.getFileList(d, 'rpm'):
fp = d + '/' + f
fpstat = os.stat(fp)
! if int(fpstat[stat.ST_SIZE]) > self.conf.max_delta_rpm_size:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % f)
continue
--- 671,677 ----
for f in self.getFileList(d, 'rpm'):
fp = d + '/' + f
fpstat = os.stat(fp)
! if long(fpstat[stat.ST_SIZE]) > self.conf.max_delta_rpm_size:
self.callback.log("Skipping %s package " \
"that is > max_delta_rpm_size" % f)
continue
Установить атрибут MakeDVD.sh на выполнение.
Запустить файл MakeDVD.sh.
В каталоге dvd-iso получим DVD ISO-образ Russian Remix Fedora 13.
Исходники скрипта и патчей.
|
| |
|
|
|
Анализ содержимого DEB-пакетов (доп. ссылка 1) |
[комментарии]
|
| | Наиболее простым способом просмотра содержимого как установленного, так и не
установленного, DEB-пакета является использование утилиты apt-file.
Устанавливаем:
sudo apt-get install apt-file
sudo apt-file update
Выводим список файлов для любого установленного пакета или пакета из
репозитория, в отличие от "dpkg -L" установка пакета для его анализа не
обязательна, выборка производится на основе сохраненных индексов:
apt-file list имя_пакета
например:
apt-file list wget
Ищем в состав какого пакета входит заданный файл:
apt-file search /usr/bin/ldd
apt-file search libUil.so
точное соответствие (-x - использовать perl-совместимые регулярные выражения):
apt-file -x search '^/bin/ls$'
или используем более замысловатую выборку по маске
apt-file search "/(usr/bin/vim|sbin/lvm)"
для просмотра содержимого локально скопированного пакета, отсутствующего в
репозитории, можно использовать команду:
dpkg-deb -c file.deb
|
| |
|
|
|
Организация работы APT через NTLM-proxy |
Автор: deathmokar
[комментарии]
|
| | APT (aptitude, apt-get) не проходит в интернет напрямую через MS ISA (proxy).
Проблема в NTLM авторизации от MS. В сети можно найти описание решения
(http://michaelcarden.net/blog/index.php?p=58) через задействование локального
прокси-сервера ntlmaps, но работать этот метод отказался.
Решение нашлось на сайте http://cntlm.sourceforge.net/
Конфигурационный файл данного прокси крайне прост (/etc/cntlm.conf):
Username - имя пользователя для ISA
Domain - имя MS-домена
Password - пароль
Proxy - сервер ISA (ip или имя) и его порт (8080)
Остальное не трогал.
Например:
Username myname
Domain MYDOMAIN
Password mypass
#Workstation - не понадобилось
Proxy proxy.mynet.com:8080
После правки перезапускаем прокси:
/etc/init.d/cntlm restart
Сам APT направляем на него так:
touch /etc/apt/apt.config.d/proxy
В любом редакторе правим файл до состояния:
Acquire::http::Proxy "http://127.0.0.1:3128/";
Acquire::ftp::Proxy "ftp://127.0.0.1
|
| |
|
|
|
Как сформировать установочный iso-образ RHEL заданным набором пакетов (доп. ссылка 1) |
[комментарии]
|
| | Инструкция по подготовке загрузочного ISO собственной комплектации на базе RHEL
5.x или CentOS 5.x. Создаваемый диск будет содержать только набор пакетов,
установленных в текущей системе.
1. Загружаем iso-образ загрузочного DVD и сохраняем их в /tmp
2. Создаем базовую директорию
mkdir -p /build/rhel52
3. Монтируем ISO
mount -oloop /tmp/rhel-5-server-x86_64-dvd.iso /mnt
4. Копируем файлы с DVD в директорию /build/rhel52
rsync -rv /mnt/* /build/rhel52
cp /mnt/.discinfo /build/rhel52
cp /mnt/.treeinfo /build/rhel52
5. На текущей системе, содержание которой нам необходимо повторить в
создаваемом ISO, генерируем список пакетов:
rpm -qa --queryformat '%{name},%{version}-%{release},%{arch}\n' | sort -n > /tmp/rhel5.2-rpm
6. Добавляем окончание .rpm к элементам сформированного списка:
cat /tmp/rhel5.2-rpm | sed 's/$/.rpm/g' > /build/rhel52/rhel52-list
7. Создаем список RPM, находящихся на примонтированном DVD:
ls -1 /build/rhel52/Server > /build/rhel52/rhel52-all
8. Генерируем список пакетов, которые нам не нужны:
diff -uNr /build/rhel52/rhel52-list /build/rhel52/rhel52-all | grep ^+ > /build/rhel52/remove-list
9. Удаляем первые три строки из файла rhel52-all (удаляем первую строку и файлы
TRANS.TBL и repodata):
vi /build/rhel52-all
10. Создаем скрипт для удаления ненужных файлов
#!/bin/ksh
#uncomment the next line for troubleshooting
#set -x
LINES=`cat remove-list | wc -l`
LINE_NO=1
while [ $LINE_NO -le $LINES ]
do
BADFILE=`sed -n "${LINE_NO}p" remove-list`
rm -f /build/rhel52/Server/$BADFILE
LINE_NO=`expr $LINE_NO + 1 `
done
11. Обновляем индексные файлы на DVD, учтя удаленные пакеты:
createrepo -g /build/rhel52/Server/repodata/comps-rhel5-server-core.xml /build/rhel52/Server
12. Создаем директорию для дополнительных пакетов, которые нам хочется
сохранить на установочном носителе:
mkdir /build/rhel52/addons
15. Копируем дополнительные пакеты:
cp /pathtofiles/addons/* /build/rhel52/addons/
13. Копируем типовой kickstart-файл из текущей системы:
cp kickstart_file /build/rhel52
14. Заменяем если в kickstart-файле "--url http://" на "cdrom"
После секции %post добавляем:
%post --nochroot
mount /tmp/cdrom /mnt/sysimage/mnt
Заменяем "/bin/rpm -Uhv http://" на "/bin/rpm -Uhv /mnt/addons/", чтобы ставить
файлы не из web, а их локальной директории addons. Также заменяем все
упоминания wget на директорию addons.
15. Для удобства установки в /build/rhel52/isolinux/boot.msg добавляем
подсказку по вызову kickstart-конфигурации "ks=cdrom:/rhel52.ks.cfg"
16. Создаем загрузочный ISO:
mkisofs -r -T -J -V "RHEL52 DVD" -b isolinux/isolinux.bin -c isolinux/boot.cat \
-no-emul-boot -boot-load-size 4 -boot-info-table -o /tmp/rhel52.iso /build/rhel52
|
| |
|
|
|
Создание локального зеркала Debian (apt-mirror + ProFTPd + Apache2) |
Автор: Yuri Rybnikov
[комментарии]
|
| | Введение: Нужно было сделать зеркало Debian в локальной сети университета. Под
эти нужны была создана виртуальная машина и установлен "голый" Debian.
IP адрес достался по-наследству от старого зеркала: 192.168.1.200.
Были поставленыVMware Tools. И всё сконфигурировано для работы.
Далее пойдем по порядку.
В нашем университете используется прокси-сервер,
и чтобы установить его по умолчанию в файл конфигурации окружения /etc/profile
необходимо внести изменения, а именно добавить:
export http_proxy=http://192.168.251.1:8080/
export ftp_proxy=ftp://192.168.251.1:8080/
Ставим пакет, который будет выполнять зеркалирование apt-mirror:
apt-get install apt-mirror
Дальше нам надо определиться с файлом конфигурации зеркала. Что будет зеркалироваться и откуда.
Так как через университетский прокси доступно быстрое зеркало http://ftp.mgts.by/debian
Правим /etc/apt/mirrors.list:
# apt-mirror configuration file
##
## The default configuration options (uncomment and change to override)
##
#
set base_path /var/spool/apt-mirror
set mirror_path $base_path/mirror
set skel_path $base_path/skel
set var_path $base_path/var
#set defaultarch i386
set nthreads 20
set _tilde 0
# etch's section
#deb http://ftp.mgts.by/debian etch main contrib non-free
# lenny's section
deb http://ftp.mgts.by/debian lenny main contrib non-free
# squeeze's section
deb http://ftp.mgts.by/debian squeeze main contrib non-free
# sid's section
deb http://ftp.mgts.by/debian sid main contrib non-free
##
## Cleaner configuration example
##
set cleanscript $var_path/clean.sh
# Cleaning section
clean http://ftp.mgts.by/
skip-clean http://ftp.mgts.by/debian/doc/
Что бы не было ошибки при выполнении /var/spool/apt-mirror/var/clean.sh надо
пропатчить /usr/bin/apt-mirror
Содержание файла apt-mirror.patch:
--- /usr/bin/apt-mirror 2007-12-02 11:22:02.000000000 +0100
+++ apt-mirror-patched 2008-06-15 11:28:47.000000000 +0200
@@ -518,14 +518,14 @@
my $dir = shift;
my $is_needed = 0;
return 1 if $skipclean{$dir};
- opendir(DIR, $dir) or die "apt-mirror: can't opendir $dir: $!";
- foreach (grep { !/^\.$/ && !/^\.\.$/ } readdir(DIR)) {
+ opendir(my $dir_h, $dir) or die "apt-mirror: can't opendir $dir: $!";
+ foreach (grep { !/^\.$/ && !/^\.\.$/ } readdir($dir_h)) {
my $item = $dir . "/". $_;
$is_needed |= process_directory($item) if -d $item && ! -l $item;
$is_needed |= process_file($item) if -f $item;
$is_needed |= process_symlink($item) if -l $item;
}
- closedir DIR;
+ closedir $dir_h;
push @rm_dirs, $dir unless $is_needed;
return $is_needed;
}
Патчим:
cat apt-mirror.patch | patch -p1
Логинимся под пользователем apt-mirror:
su - apt-mirror
Запускаем программу зеркалирования:
apt-mirror
Идем пить чай.
Оговорюсь, в зависимости от количества дистрибутивов выбранных для
зеркалирования и каталогов для зеркалирования объем скачанной информации может
быть очень большой.
Поэтому запаситесь терпением и работайте в screen'е :)
Должны быть всякие сообщения о том что всё ок. А при ошибке надо гуглить и исправлять.
После окончания успешного зеркалирования выполняем /var/spool/apt-mirror/var/clean.sh:
# /bin/bash /var/spool/apt-mirror/var/clean.sh
Чистим от "шлаков". И освобождаются Гигабайты пространства.
Настраиваем автоматизацию по планировщику. Правим планировщик для проверки
зеркала каждый день в час ночи и очистки от "мусора" в четыре утра.
В /etc/cron.d/apt-mirror добавляем:
#
# Regular cron jobs for the apt-mirror package
#
0 1 * * * apt-mirror /usr/bin/apt-mirror > /var/spool/apt-mirror/var/cron.log
0 4 * * * root /bin/bash /var/spool/apt-mirror/var/clean.sh > /var/spool/apt-mirror/var/cron_cl.log
#
Ставим apache2 для доступа по HTTP к зеркалу:
apt-get install apache2
Делаем доступ к зеркалу через HTTP, для этого создаем симлинк:
ln -s /var/spool/apt-mirror/mirror/ftp.mgts.by/debian /var/www/debian
Далее делаем, как и положено, ссылку на stable дистрибутив:
cd /var/spool/apt-mirror/mirror/ftp.mgts.by/debian/dists
ln -s lenny/ stable
Дальше надо сделать доступ по FTP к зеркалу с помощью сервера ProFTPd:
apt-get install proftpd
Конфигурируем его. Правим /etc/proftpd/proftpd.conf под наши нужды:
Include /etc/proftpd/modules.conf
UseIPv6 off
IdentLookups off
ServerName "Debian mirror"
ServerType standalone
DeferWelcome off
MultilineRFC2228 on
DefaultServer on
ShowSymlinks on
TimeoutNoTransfer 600
TimeoutStalled 600
TimeoutIdle 1200
DisplayLogin welcome.msg
DisplayChdir .message true
ListOptions "-l"
DenyFilter \*.*/
RequireValidShell off
# Port 21 is the standard FTP port.
Port 21
MaxInstances 30
User proftpd
Group nogroup
Umask 022 022
AllowOverwrite on
TransferLog /var/log/proftpd/xferlog
SystemLog /var/log/proftpd/proftpd.log
User ftp
Group nogroup
UserAlias anonymous ftp
DirFakeUser on ftp
DirFakeGroup on ftp
# Пускать пользователей с шелом /bin/false и прочей невалидной ерундой
RequireValidShell off
MaxClients 100
Так как ProFTPd не понимает симлинки за пределы текущего FTP-дерева, то сделаем хитрый mount:
mkdir /home/ftp/debian
mount --bind /var/spool/apt-mirror/mirror/ftp.mgts.by/debian /home/ftp/debian
Чтобы не пропадал mount после перезагрузки в /etc/fstab вносим изменения,
добавляем в конец строчку:
/var/spool/apt-mirror/mirror/ftp.mgts.by/debian /home/ftp/debian none bind
Всё. Готово. Для уверенности можем перезагрузить сервер и понять, что всё будет работать :)
Ссылки:
* http://apt-mirror.sourceforge.net - apt-mirror (apt sources mirroring tool)
* http://www.howtoforge.com/local_debian_ubuntu_mirror - How To Create A Local
Debian/Ubuntu Mirror With apt-mirror
* http://www.linuxnsk.ru/index.php?option=com_content&task=view&id=171&Itemid=1
- Как создать локальное зеркало Debian/Ubuntu используя apt-mirror (перевод)
*
http://wiki.binarylife.ru/index.php/Apt-get_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D0%BF%D1%80%D0%BE%D0%BA%D1%81%D0%B8 -
Apt-get через прокси
* http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=484876 - apt-mirror: many closedir() errors
* http://itblog.su/proftpd-vs-symlinks.html - proftpd vs symlinks
* http://sudouser.com/nastrojka-cron - Настройка Cron
|
| |
|
|
|
Упрощение тестирования экспериментальных версий Ubuntu при помощи TestDrive (доп. ссылка 1) |
[обсудить]
|
| | Для желающих регулярно следить за процессом разработки Ubuntu ежедневно
публикуются тестовые сборки, позволяющие наглядно оценить прогресс в развитии
дистрибутива. Для автоматизации выполнения рутинных операций по загрузке и
запуску таких сборок под управлением систем виртуализации подготовлена удобная
утилита testdrive (http://edge.launchpad.net/testdrive).
Утилита testdrive работает в режиме командной строки и после запуска дает
возможность выбрать тип тестируемой сборки (десктоп, сервер, версия для
нетбуков и т.п.). Если ранее при помощи программы уже осуществлялась загрузка
тестовых образов, то по сети будут переданы только изменившиеся в новом
iso-образе данные, что позволяет ускорить загрузку и сэкономить трафик.
После загрузки iso-образ автоматически конфигурируется для запуска под
управлением систем виртуализации KVM или VirtualBox.
Установить программу можно из PPA-репозитория https://edge.launchpad.net/~testdrive/+archive/ppa
sudo add-apt-repository ppa:testdrive/ppa
sudo apt-get update
sudo apt-get install testdrive
|
| |
|
|
|
Сборка дополнительный модулей ядра в Debian и Ubuntu (доп. ссылка 1) |
[комментарии]
|
| | Установить дополнительный модуль из исходных текстов для Linux ядра в Debian,
не нарушая пакетной структуры дистрибутива, можно при помощи приложения
module-assistant, в результате работы которого на выходе получается обычный
deb-пакет с заданным модулем.
Для примера произведем установку модуля ndiswrapper в Debian Lenny.
Устанавливаем module-assistant:
apt-get install module-assistant
Загружаем необходимые для работы сборки модулей заголовочные файлы ядра и
пакеты, подобные build-essential:
m-a prepare
Обновляем индекс с установленными в данный момент модулями:
m-a update
Посмотреть список модулей можно через команду:
m-a list
или в сокращенном виде:
m-a -t list | grep -E '^[^ ].*\(' | cut -d " " -f 1 | sort
Перед сборкой проверяем наличие в /etc/apt/sources.list подключения
репозиториев contrib и non-free, которые могут понадобиться для установки
зависимостей для собираемого модуля.
Собираем нужный модуль, который после сборки будет автоматически установлен (a-i = auto-install):
m-a a-i ndiswrapper
Устанавливаем сразу несколько модулей разом:
m-a a-i madwifi zaptel openswan sl-modem kvm drbd
чтобы просто собрать пакет без установки, нужно выполнить (a-b = auto-build):
m-a a-b ndiswrapper
Если выполнить команду "m-a" без аргументов, то module-assistant запустится в
интерактивном режиме, где все действия можно проделать в диалоговом режиме
через интерфейс на базе меню.
Настраиваем загрузку Windows-драйвера через ndiswrapper:
apt-get install ndiswrapper-utils-1.9 wireless-tools
ndiswrapper -i bcmwl5a.inf
Загружаем модуль:
modprobe ndiswrapper
Проверяем его загрузку:
lsmod | grep ndiswrapper
Настраиваем автозагрузку модуля указав его имя в в /etc/modules:
ndiswrapper
Проверяем работу беспроводной карты и создаем WEP-соединение:
ifconfig wlan0 up
iwconfig wlan0 key open 1234567890
iwconfig wlan0 essid номер
dhclient wlan0
|
| |
|
|
|
Настройка сервера сетевой установки на базе CentOS (доп. ссылка 1) |
[комментарии]
|
| | Устанавливаем tftp-сервер:
yum install tftp-server
и активируем его в /etc/xinetd.d/tftp:
disable = no
Перезапускаем xinetd, чтобы изменения подействовали:
service xinetd restart
Устанавливаем пакет syslinux:
yum install syslinux
Копируем необходимые для загрузки файлы syslinux в директорию tftpboot:
cp /usr/lib/syslinux/pxelinux.0 /tftpboot
cp /usr/lib/syslinux/menu.c32 /tftpboot
cp /usr/lib/syslinux/memdisk /tftpboot
cp /usr/lib/syslinux/mboot.c32 /tftpboot
cp /usr/lib/syslinux/chain.c32 /tftpboot
Создаем директорию с PXE меню:
mkdir /tftpboot/pxelinux.cfg
Создаем для каждого релиза CentOS, которые потребуется устанавливать удаленно,
поддиректории для загрузочных образов:
mkdir -p /tftpboot/images/centos/i386/3.0
mkdir -p /tftpboot/images/centos/i386/3.1
mkdir -p /tftpboot/images/centos/x86_64/3.0
mkdir -p /tftpboot/images/centos/x86_64/3.1
mkdir -p /tftpboot/images/centos/i386/4.0
mkdir -p /tftpboot/images/centos/i386/4.1
mkdir -p /tftpboot/images/centos/x86_64/4.0
mkdir -p /tftpboot/images/centos/x86_64/4.1
mkdir -p /tftpboot/images/centos/i386/5.0
mkdir -p /tftpboot/images/centos/i386/5.1
mkdir -p /tftpboot/images/centos/x86_64/5.0
mkdir -p /tftpboot/images/centos/x86_64/5.1
Для каждого релиза и архитектуры копируем образ ядра vmlinuz и ram-диск
initrd.img из директории /images/pxeboot/ на первом установочном диске каждого
релиза (из $Release/$ARCH копируем в /tftpboot/images/centos/$ARCH/$RELEASE).
Настраиваем DHCP, добавляем в /etc/dhcpd.conf (вместо xxx.xxx.xxx.xxx
прописываем адрес нашего PXE-сервера):
allow booting;
allow bootp;
option option-128 code 128 = string;
option option-129 code 129 = text;
next-server xxx.xxx.xxx.xxx;
filename "/pxelinux.0";
Перезапускаем DHCP сервер:
service dhcpd restart
Создаем PXE меню, добавляем в /tftpboot/pxelinux.cfg/default примерно следующее:
default menu.c32
prompt 0
timeout 300
ONTIMEOUT local
MENU TITLE PXE Menu
LABEL Pmajic
MENU LABEL Pmajic
kernel images/pmagic/bzImage
append noapic initrd=images/pmagic/initrd.gz root=/dev/ram0 init=/linuxrc ramdisk_size=100000
label Dos Bootdisk
MENU LABEL ^Dos bootdisk
kernel memdisk
append initrd=images/622c.img
LABEL CentOS 5 x86 NO KS eth0
MENU LABEL CentOS 5 x86 NO KS eth0
KERNEL images/centos/5/x86/vmlinuz
APPEND ks initrd=images/centos/5/x86_64/initrd.img \
ramdisk_size=100000 ksdevice=eth1 ip=dhcp url --url http://xxx.xxx.xxx.xxx/mirrors/CentOS-5-i386/
LABEL CentOS 5 x86_64 NO KS eth0
MENU LABEL CentOS 5 x86_64 NO KS eth0
KERNEL images/centos/5/x86_64/vmlinuz
APPEND ks initrd=images/centos/5/x86_64/initrd.img \
ramdisk_size=100000 ksdevice=eth1 ip=dhcp url --url http://xxx.xxx.xxx.xxx/mirrors/CentOS-5-x86_64/
|
| |
|
|
|
Восстановление даты модификации файла из rpmdb (доп. ссылка 1) |
Автор: Артем Носов
[комментарии]
|
| | Восстановить дату последней модификации файла из базы rpmdb позволяет команда:
touch -m --date="`rpm -q --qf '%{FILEMTIMES:date}' -f имя_файла`" имя_файла
Например, рассмотрим ситуацию
rpm -V postgresql-server
.......T c /var/lib/pgsql/.bash_profile
У файла поменялась дата модификации в связи с внесением в него временных
изменений. Восстановим дату модификации на хранимую в rpmdb
touch -m --date="`rpm -q --qf '%{FILEMTIMES:date}' -f /var/lib/pgsql/.bash_profile`" /var/lib/pgsql/.bash_profile
Проверим, что изменения имели место быть
rpm -V postgresql-server
Проверка прошла успешно.
|
| |
|
|
|
Как в Debian/Ubuntu установить отсутствующий в репозитории Perl модуль |
[комментарии]
|
| | В случае отсутствия определенного Perl модуля в стандартных репозиториях Debian
и Ubuntu, можно поставить модуль через задействования механизмов установки
модулей CPAN, но такие модули не впишутся в пакетную инфраструктуру
дистрибутива. Поэтому для установки нестандартных Perl модулей следует
использовать dh-make-perl.
Ставим пакет dh-make-perl:
apt-get install dh-make-perl
Устанавливаем нужный Perl модуль (в примере Module::Name) из репозитория CPAN:
dh-make-perl --cpan Module::Name --install
Например:
dh-make-perl --cpan HTML::CTPP2 --install
Утилита dh-make-perl сама загрузит нужный модуль, соберет его, оформит deb-пакет и установит его.
Если модуль не из CPAN, можно распаковать модуль и выполнить (--build -
сформировать пакет, но не устанавливать):
dh-make-perl директория_с_модулем --build
|
| |
|
|
|
Перенос пакетов с зависимостями между Debian-based дистрибутивами |
Автор: Vitto
[комментарии]
|
| | Столкнулся с вопросом: как установить программу в debian/ubuntu без интернета.
Дело в том, для переноса уже установленных программ используют aptoncd, который
делает мини-репозиторий из кэша пакетов. Но как быть если кэш чистился и в нем
лежат не все необходимые пакеты? Или необходимо принести программу на ubuntu а
на компьютере стоит Debian ? Да и архитектур много.
Для получения пакетов со всеми зависимостями для установки на конкретную машину
нам понадобится файл "/var/lib/dpkg/status" с исходной машины (на которую несем
пакеты для установки). В нем содержится список установленных пакетов и их
состояние. На целевой системе не должно быть пакетов, установленных с ошибками
иначе apt откажется работать.
Если нужно использовать альтернативный sources.list, то его следует создать.
Затем создаем директорию, где будет наш кэш и директорию partial в ней. Далее
дело техники.
Получаем список пакетов из sources.list:
sudo apt-get -o Dir::State::status='наш файл status' -o Dir::Cache::archives="куда кладем пакеты" \
-o Dir::Etc::sourcelist="файл sources.list" -o APT::Architecture="архитектура" update
Создаем кэш:
sudo apt-get -d -o Dir::State::status='наш файл status' -o Dir::Cache::archives="куда кладем пакеты" \
-o Dir::Etc::sourcelist="файл sources.list" -o APT::Architecture="архитектура" install <нужные пакеты>
В результате в подготовленной директории появятся все пакеты, которые
необходимы для установки указанных пакетов на нужную нам машину, которые мы
определяем в мини-репозиторий с помощью aptoncd.
|
| |
|
|
|
Восстановление после неудачной установки deb-пакета (доп. ссылка 1) (доп. ссылка 2) |
Автор: Delayer
[комментарии]
|
| | Ниже инструкция по удалению некорректно собранного deb-пакета, если после
попытки его удаления dpkg вываливается с ошибкой.
Удаляем связанную с пакетом информацию (допустим пакет имеет имя package-name)
cd /var/lib/dpkg/info
rm package-name.*
Открываем с правами администратора в любимом текстовом редакторе файл
/var/lib/dpkg/status и удаляем секцию с упоминанием удаляемого пакета, имеющую
примерно следующее содержание:
Package: package-name
Status: install ok installed
Priority: extra
Section: alien
Installed-Size: 8440
Maintainer: root
Architecture: amd64
Version: v4.0rc9-999
Depends: blablabla
Conffiles:
Description: blahblahblah
.
Удаляем следы остаточных конфликтов выполнив:
apt-get -f install
|
| |
|
|
|
Защита пакетов, установленных из определенного Yum репозитория (доп. ссылка 1) |
[комментарии]
|
| | Для того, чтобы гарантировать, что пакеты, установленные в CentOS / RHEL из
определенного внешнего Yum-репозитория не будут переустановлены/обновлены при
появлении более новых версий подобных пакетов в других репозиториях можно
использовать плагин yum-protectbase.
Устанавливаем плагин:
yum install yum-protectbase
Активируем плагин, добавив в /etc/yum/pluginconf.d/protectbase.conf
[main]
enabled = 1
Находим репозиторий, который нужно защитить в директории /etc/yum.repos.d и
добавляем в конфигурацию опцию
protect = 1
Например, для репозитория epel в файле /etc/yum.repos.d/epel.repo меняем:
[epel]
name=Extra Packages for Enterprise Linux 5 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/5/$basearch
mirrorlist=http://mirrors.fedoraproject.org/mirrorlist?repo=epel- 5&arch=$basearch
failovermethod=priority
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL
protect = 1
|
| |
|
|
|
Упрощение удаления группы пакетов в Aptitude, через использования меток (доп. ссылка 1) |
Автор: jetxee
[комментарии]
|
| | Очень полезная возможность в aptitude - пользовательские метки для выбранных пакетов.
Например, нужно поставить какой-то набор пакетов, чтобы собрать определенную
программу из исходных текстов,
а затем удалить пакеты, установленные только для сборки.
При установке помечаем выбранные пакеты какой-то своей меткой (builddeps в моём примере):
sudo aptitude install --add-user-tag builddeps libчто-то-dev libчто-то-ещё-dev ...
А потом, когда эти пакеты больше не требуются, их удаляем, выбрав по той же метке:
sudo aptitude purge '?user-tag(builddeps)'
Поисковый шаблон ?user-tag(метка) можно использовать совместно со всеми другими
поисковыми шаблонами.
Присваивать метки можно не только при установке, но и во многих других операциях.
|
| |
|
|
|
Удаление неиспользуемых пакетов в Debian GNU/Linux (доп. ссылка 1) |
[комментарии]
|
| | Для чистки системы от оставшихся после удаления пакетов, неудаленных
зависимостей, можно использовать программу deborphan.
По умолчанию deborphan осуществляет поиск неиспользуемых библиотек, но можно
указать расширить область охвата на
файлы с данными, dev-пакеты и т.п.
Устанавливаем deborphan
apt-get install deborphan
Выводим все неиспользуемые библиотеки:
deborphan > /tmp/rm_list.txt
Выводим неиспользуемые dev-пакеты:
deborphan --guess-dev >> /tmp/rm_list.txt
Проверяем /tmp/rm_list.txt на наличие ложных срабатываний, убираем лишнее.
Удаляем неиспользуемые пакеты:
cat /tmp/rm_list.txt | xargs apt-get -y remove purge
Посмотреть все неиспользуемые пакеты, какие удалось найти (в выводе оказалось
много нужных пакетов):
deborphan --guess-all
|
| |
|
|
|
Настройка установки обновлений с исправлением проблем безопасности в RHEL/CentOS (доп. ссылка 1) |
[комментарии]
|
| | Плагин yum-security позволяет использовать в yum команды list-security и
info-security, а также опции
"--security", "--cve", "--bz" и "--advisory" для фильтрации исправлений проблем
безопасности из общего массива обновлений.
Устанавливаем плагин:
# yum install yum-security
Выводим список доступных обновлений, в которых непосредственно исправлены уязвимости:
# yum list-security
Для вывода всех связанных с безопасностью обновлений (с учетом зависимостей):
# yum --security check-update
Для вывода всех сообщений о проблемах, отмеченных в bugzilla:
# yum list-security bugzillas
Вывод информации об исправлениях, связанных с уведомлением о наличии уязвимостей RHSA-2009:1148-1:
# yum info-security RHSA-2009:1148-1
Вывод списка пакетов в которых устранены заданные ошибки отмеченные в Bugzilla, CVE и RHSA:
# yum --bz 3595 --cve CVE-2009-1890 --advisory RHSA-2009:1148-1 info updates
Установка только обновлений, связанных с безопасностью:
# yum update --security
|
| |
|
|
|
Установка ненайденного ключа для PPA репозиториев Ubuntu (доп. ссылка 1) |
Автор: silverghost
[комментарии]
|
| | Если система ругается, что не найден ключ репозитория:
W: Ошибка: http://ppa.launchpad.net intrepid Release: Следующие подписи не могут быть проверены,
так как недоступен открытый ключ: NO_PUBKEY 5A9BF3BA4E5E17B5
Это легко исправить двумя командами:
gpg --keyserver keyserver.ubuntu.com --recv 5A9BF3BA4E5E17B5
gpg --export --armor 5A9BF3BA4E5E17B5 | sudo apt-key add -
|
| |
|
|
|
Как настроить кеширующий репозиторий для Fedora с помощью nginx |
Автор: fb769
[комментарии]
|
| | Устанавливаем необходимые пакеты
yum install nginx yum-utils
правим конфиг /etc/nginx/nginx.conf перед последней закрыющейся } дописываем
include /etc/nginx/vh/*;
создаем каталог
mkdir /etc/nginx/vh
а в нем файл repocache.local следующего содержания
server {
listen 80;
server_name repocache.local;
location /pub/fedora {
autoindex on;
root /home/repocache;
error_page 404 = @fetch_yandex;
}
location / {
autoindex on;
root /home/repocache;
error_page 404 = @fetch_yandex;
}
location @fetch_yandex {
internal;
rewrite ^/pub(.*)$ /$1 break;
proxy_pass http://mirror.yandex.ru;
proxy_store on;
proxy_store_access user:rw group:rw all:r;
proxy_temp_path /home/repocache/temp;
root /home/repocache/pub;
}
}
создаем каталоги
mkdir /home/repocache
mkdir /home/repocache/bin
mkdir /home/repocache/pub
mkdir /home/repocache/temp
chown -R nginx:nginx /home/repocache
в каталог /home/repocache помещаем скрипт clean.sh
#!/bin/bash
for f in $@;
do
echo $f
for ff in `repomanage --old $f`;
do
rm -f $ff
done
rm -f $f/repodata/*
done
и repocache.sh
#!/bin/bash
find /home/repocache/pub -type d -regex .*/updates/.*/i386 -exec /home/repocache/bin/clean.sh {} +
find /home/repocache/pub -type d -regex .*/updates/.*/x86_64 -exec /home/repocache/bin/clean.sh {} +
rm -f /home/repocache/temp/*
#!/bin/bash
for f in `repomanage --old $1`;
do
echo $f
rm -f $f
done
rm -f $1repodata/*
и repocache.sh
#!/bin/bash
path_to_repo_dir="/home/repocache/pub/"
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/linux/updates/11/i386/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/linux/updates/11/x86_64/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/rpmfusion/free/fedora/updates/11/i386/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/rpmfusion/free/fedora/updates/11/x86_64/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/rpmfusion/nonfree/fedora/updates/11/i386/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/rpmfusion/nonfree/fedora/updates/11/x86_64/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/russianfedora/russianfedora/fixes/fedora/updates/11/i386/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/russianfedora/russianfedora/fixes/fedora/updates/11/x86_64/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/russianfedora/russianfedora/free/fedora/updates/11/i386/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/russianfedora/russianfedora/free/fedora/updates/11/x86_64/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/russianfedora/russianfedora/nonfree/fedora/updates/11/i386/
/home/repocache/bin/clean.sh ${path_to_repo_dir}fedora/russianfedora/russianfedora/nonfree/fedora/updates/11/x86_64/
rm -f /home/repocache/temp/*
Запускаем nginx
service nginx start
Добавляем в crontab запуск скрипта /home/repocache/bin/repocache.sh раз в сутки (ночью)
Перенастраиваем локальные компы и на новый репозиторий и пробуем обновиться
Удачи.
|
| |
|
|
|
Установка Ubuntu Server с флеш-карты (доп. ссылка 1) (доп. ссылка 2) |
Автор: xAnd
[комментарии]
|
| | Установка десктопных дистрибутивов с USB-накопителей обычно не вызывает особых проблем,
UNetBootin есть и под Windows и под Linux, кроме того, есть ещё несколько способов изготовления
загрузочных "флешек". Для серверного дистрибутива Ubuntu этот способ не
подходит. Программа установки запускается,
всё проходит гладко до монтирования привода CD-ROM и на этом заканчивается. Ни
ручное монтирование привода,
ни использование стандартных драйверов
не помогает, что в общем-то естественно, CD-ROM’а-то нет. В итоге, выход
нашёлся на официальном help’е Ubuntu.
И вот, что в итоге нам понадобится для создания "правильно" установочной
"флешки" для Ubuntu Server:
1. Собственно сам ISO-образ Ubuntu Server
2. initrd.gz (http://archive.ubuntu.com/ubuntu/dists/jaunty/main/installer-amd64/current/images/hd-media/initrd.gz)
3. wmlinuz (http://archive.ubuntu.com/ubuntu/dists/jaunty/main/installer-amd64/current/images/hd-media/vmlinuz)
4. Flash-накопитель от 1 Гб и больше
Если будете ставить другую версию или другую целевую платформу, то ссылки будут другие.
Ещё нам понадобится небольшой скрипт:
# Replace "sdx" with "sdb" or whatever your flash drive is
# - If unsure which device is your flash drive then
# run "sudo fdisk -l | less" in order to identify it
ISOIMAGE=ubuntu-9.04-server-amd64.iso
sudo apt-get install syslinux mtools mbr
echo "Use fdisk to manually create a 1GB bootable FAT16 partition."
read -p "Press [Enter] to start the fdisk program..."
# sudo fdisk /dev/sdx
# sudo mkfs -t vfat /dev/sdx1
sudo mkdir -p /mnt/flash
sudo mount -t vfat /dev/sdx1 /mnt/flash
sudo syslinux -s /dev/sdx1
sudo mkdir -p /mnt/iso
sudo mount -o loop $ISOIMAGE /mnt/iso
sudo cp -R /mnt/iso/isolinux/* /mnt/flash
sudo mv /mnt/flash/isolinux.cfg /mnt/flash/syslinux.cfg
sudo mkdir -p /mnt/flash/install
sudo cp vmlinuz /mnt/flash/install
sudo cp initrd.gz /mnt/flash/install
# clear pool directory, which is unnecessary for installation
# that enables installation on 1G flash; remove if installing on
# bigger devices and you run into problems
sudo rm -rf /mnt/flash/pool
sudo cp $ISOIMAGE /mnt/flash
sudo install-mbr /dev/sdx
sudo umount /mnt/flash
sudo umount /mnt/iso
Копируем его, вставляем в любимый текстовый редактор. Переменной $ISOIMAGE
присваеваем имя ISO-образа,
а все упоминания sdx заменяем на имя устройства флешки (обычно sdb, если у Вас
один физический диск).
Сохраняем полученный файл в директории и выполняем:
chmod +x script
sudo ./script
Во время работы скрипта изначально был прописан запуск fdisk и переформатирование,
но для стандартных, уже отформатированных под FAT32 флешек, делать это не обязательно.
|
| |
|
|
|
Установка ARM-сборки Debian GNU/Linux в qemu (доп. ссылка 1) (доп. ссылка 2) (доп. ссылка 3) |
[комментарии]
|
| | Перед экспериментами по установке Linux на устройства на базе архитектуры ARM
(например, Sharp Zaurus,
Openmoko FreeRunner, планшетные ПК NOKIA, NAS на базе SoC Marvell) вначале
стоит потренироваться в эмуляторе.
Кроме того, окружение созданное в эмуляторе удобно использовать
для создания и сборки пакетов программ или модулей ядра.
Ставим на рабочую машину qemu. Для debian/ubuntu:
sudo apt-get install qemu
Создаем дисковый образ размером 10Гб для виртуальной машины:
qemu-img create -f qcow hda.img 10G
Загружаем ядро, initrd и инсталлятор Debian для архитектуры ARM:
wget http://people.debian.org/~aurel32/arm-versatile/vmlinuz-2.6.18-6-versatile
wget http://people.debian.org/~aurel32/arm-versatile/initrd.img-2.6.18-6-versatile
wget http://ftp.de.debian.org/debian/dists/etch/main/installer-arm/current/images/rpc/netboot/initrd.gz
Загружаем инсталлятор и устанавливаем Debian по сети, следуя инструкциям программы установки:
qemu-system-arm -M versatilepb -kernel vmlinuz-2.6.18-6-versatile -initrd initrd.gz -hda hda.img -append "root=/dev/ram"
Запускаем установленную систему:
qemu-system-arm -M versatilepb -kernel vmlinuz-2.6.18-6-versatile -initrd initrd.img-2.6.18-6-versatile \
-hda hda.img -append "root=/dev/sda1"
Устанавливаем дополнительные программы, например, gcc:
apt-get install gcc
Проверяем:
gcc -dumpmachine
"arm-linux-gnu"
|
| |
|
|
|
Использование apt-p2p для ускорения обновления Ubuntu (доп. ссылка 1) |
[комментарии]
|
| | Приближается выход релиза Ubuntu 9.04, в день которого из-за перегрузки зеркал
могут наблюдаться проблемы со скоростью загрузки обновлений.
Для оптимизиации процесса предлагается задействовать apt-прокси, организующий
загрузку данных по принципу P2P сетей.
Устанавливаем apt-p2p:
sudo apt-get install apt-p2p
Правим /etc/apt/sources.list (добавляем "localhost:9977" после "http://"):
deb http://localhost:9977/archive.canonical.com/ubuntu hardy partner
deb-src http://localhost:9977/archive.canonical.com/ubuntu hardy partner
deb http://localhost:9977/*mirror-address*/ubuntu/ hardy main universe restricted multiverse
deb-src http://localhost:9977/*mirror-address*/ubuntu/ hardy main universe restricted multiverse
Обновляем список пакетов:
sudo apt-get update
Запускаем процесс обновления Ubuntu 8.10 до версии 9.04
sudo update-manager -d
Открываем в браузере http://localhost:9977 и смотрим информацию о скорости
загрузки и другую статистику
|
| |
|
|
|
Добавление поддержки IP sets и пересборка ядра в Debian GNU/Linux (доп. ссылка 1) |
Автор: sanmai
[комментарии]
|
| | Настроим IP sets (http://ipset.netfilter.org/) в Debian. Ipset позволяет использовать
большие таблицы IP и MAC адресов, подсетей номеров портов совместно с iptables
(подключение через одно
правило, в таблице используется хэширование). Возможно быстрое обновление списка целиком.
Например:
ipset -N servers ipmap --network 192.168.0.0/16
ipset -A servers 192.168.0.1
iptables -A FORWARD -m set --set servers dst,dst -j ACCEPT
Ставим исходные тексты ядра и устанавливаем необходимые для сборки пакеты:
# apt-get install kernel-package libncurses5-dev fakeroot
/usr/src# REV=`date +%F`
/usr/src# KV=2.6.29
/usr/src# wget http://www.kernel.org/pub/linux/kernel/v2.6/linux-${KV}.tar.bz2
/usr/src# wget http://www.kernel.org/pub/linux/kernel/v2.6/linux-${KV}.tar.bz2.sign
/usr/src# gpg --verify linux-${KV}.tar.bz2.sign
/usr/src# tar xvjf linux-${KV}.tar.bz2
/usr/src# ln -s linux-${KV} linux
Устанавливаем патчи ipset:
# cd /usr/src/
src # aptitude install git-core ipset
src # git clone git://git.netfilter.org/ipset.git
src # cd ipset/
ipset # make KERNEL_DIR=/usr/src/linux patch_kernel
cd kernel; ./patch_kernel /usr/src/linux
Собираем ядро:
ipset # cd /usr/src/linux
/usr/src/linux# make-kpkg clean
/usr/src/linux# make menuconfig
/usr/src/linux# cp .config ~/
Отвечаем yes на все что нам нужно.
Начинаем непосредственно компиляцию:
/usr/src/linux# fakeroot make-kpkg --revision=${REV} kernel_image
Пьем чай. Спокойно. Оно заканчивается:
dpkg --build /usr/src/linux/debian/linux-image-${KV} ..
dpkg-deb: building package `linux-image-${KV}' in `../linux-image-${KV}_${REV}_amd64.deb'.
make[2]: Leaving directory `/usr/src/linux-${KV}'
make[1]: Leaving directory `/usr/src/linux-${KV}'
/usr/src/linux#
/usr/src/linux# dpkg -i ../linux-image-${KV}_${REV}_amd64.deb
Если не получилось, удаляем и компилируем с той же ${REV}:
/usr/src/linux# dpkg -r linux-image-${KV}
/usr/src/linux# REV=`date +%F`
/usr/src/linux# rm -fr debian/
/usr/src/linux# make menuconfig
И так далее как было выше.
После установки обновляем конфиг grub:
/usr/src/linux# update-grub
Searching for GRUB installation directory ... found: /boot/grub
Searching for default file ... found: /boot/grub/default
Testing for an existing GRUB menu.lst file ... found: /boot/grub/menu.lst
Searching for splash image ... none found, skipping ...
Found kernel: /vmlinuz-${REV}
Updating /boot/grub/menu.lst ... done
Обязательно проверяем и перезагружаемся:
/usr/src/linux# cat /boot/grub/menu.lst
/usr/src/linux# reboot
Заключительный тест:
~ $ ping server
Debian 5.0 (Lenny и ipset).
Дополнение от pavel_simple:
В Debian 5.0 (Lenny), модулей ipset как таковых нет. Вместо этого имеется всё необходимое,
чтобы ими можно было воспользоваться.
1. устанавливаем пакеты.
#apt-get build-dep netfilter-extensions-source
#apg-get install netfilter-extensions-source
#cd /usr/src
#tar xjf netfilter-extensions.tar.bz2
2. собираем и устанавливаем
#m-a a-i netfilter-extension
3. пользумся
|
| |
|
|
|
Резервная копия rpm пакетов, обновляющихся через yum. (доп. ссылка 1) |
Автор: Romik_g
[комментарии]
|
| | Если добавить в секцию "[main"] файла /etc/yum.conf опцию
tsflags=repackage
то резервные копии rpm пакетов, которые обновились, вместе с конфигурационными файлами,
будут сохраняться в директории /var/spool/repackage/. Не забывайте следить за
свободным местом на диске.
Подробности в man yum.conf и man rpm.
Сохранение изменений файлов конфигурации работает, только если вы держите конфигурационные файлы
в стандартных для конкретных rpm пакетов местах.
|
| |
|
|
|
Как вручную распаковать RPM пакет из последних версий AltLinux и OpenSUSE |
[комментарии]
|
| | Для новых версий AltLinux и OpenSUSE не пройдет стандартный метод
rpm2cpio packet.rpm | cpio -idmuv --no-absolute-filenames
cpio выдаст ошибку, а при сохранении в файл и проверке утилитой file будут
определены бинарные данные.
Дело в том, что AltLinux и OpenSUSE перешли на использование алгоритма LZMA для
сжатия cpio архива внутри RPM,
поэтому для ручного раскрытия дополнительно нужно использовать утилиту lzma:
rpm2cpio packet.rpm |lzma -d | cpio -idmuv --no-absolute-filenames
Пакет с консольной утилитой lzma можно загрузить с сайта http://tukaani.org/lzma/ или
поставить из пакетов (lzma или lzma-utils).
|
| |
|
|
|
Использование apt-zip и yumdownloader для загрузки обновлений с другой машины (доп. ссылка 1) |
[комментарии]
|
| | apt-zip позволяет минимизировать ручные операции при обновлении Debian/Ubuntu
на машине с медленным соединением к сети.
Устанавливаем apt-zip:
apt-get install apt-zip
В /etc/apt/apt-zip.conf определяем носитель для переноса пакетов между машинами.
Например, меняем "MEDIUM=/media/zip" на "MEDIUM=/media/disk"
Обновляем кеш пакетов:
apt-get update
Записываем на Flash диск примонтированный как /media/disk список пакетов для обновления:
apt-zip-list
На Flash будет записан shell скрипт (fetch-script-wget-имя_машины ) для загрузки пакетов
при помощи утилиты wget. На машине с высокоскоростным линком достаточно просто
запустить этот скрипт.
Тип обновления задается в /etc/apt/apt-zip.conf через переменную DEFAULT_APTGETACTION:
upgrade - обновление уже установленных пакетов из репозиториев, определенных в /etc/apt/sources.list
dselect-upgrade - от upgrade отличается использованием dselect
dist-upgrade - поддерживает расширенный разрешения конфликтов, больше подходит
для выполнения обновления
всего дистрибутива до более новой версии.
После того как необходимые пакеты будут скопированы на Flash, на машине на которой
нужно произвести обновление необходимо выполнить:
apt-zip-inst
Для запроса установки новых дополнительных пакетов можно использовать:
apt-zip-list -a upgrade -p openoffice.org,digikam
...
apt-zip-inst -a upgrade -p openoffice.org,digikam
--------------
Рекомендации от _selivan_. Если дома есть dial-up, создаем скрипт upd.sh:
#!/bin/bash
# Usage: get_soft_links.sh <package1> ... <packageN>
URLS=soft`date +%F_%H.%M`-urls.txt
LIST=soft`date +%F_%H.%M`-list.txt
DIR=~/links
# get links
apt-get --print-uris -y -qq dist-upgrade | cut -d\' -f2 > $DIR/$URLS
apt-get --print-uris -y -qq install $@ | cut -d\' -f2 >> $DIR/$URLS
# print names of requested packages to file
echo $@ > $DIR/$LIST
#convert unix newline format to windows for windows download managers
sed -i -e 's/$/\r/' $DIR/$URLS
Если диалапа нет - на один шаг больше:
apt-get --print-uris update
...
--------------
Рекомендации от sHaggY_caT по использованию yumdownloader в Fedora, Centos, ASP
и других Red Hat-подобных дистрибутивах:
Ставим yum-utils.
Для генерации листа закачки можно использовать скрипт
(первый аргумент название пакета, второй, имя выходного файла):
#!/bin/sh
yumdownloader --urls $1 | sed '1,2d' > /media/disk/$2.txt
Удаление первых двух строк поставлено, так как там служебная информация от плагинов и yum.
К сожалению, yum не разделяет вывод служебной информации и результат на потоки,
по этому, сделать 2>/dev/null нельзя
Что касается машины совсем без интернета, в тут возможность подобная "apt-get
--print-uris update" не получится.
Можно только сгенерировать список для загрузки с ключем "-C":
yumdownloader -C --urls пакет
Преварительно нужно все-таки обновить кэш с помощью "yum update".
В основанных на Red Hat дистрибутивах скаченные пакеты можно либо с помощью yum либо с помощью rpm:
yum localinstall название_файлов_пакетов_через_пробел
rpm -Uhv название_файлов_пакетов_через_пробел
Yum скачает недостающие зависимости. Если список был сгенерирован верно, то это не нужно,
и необходимо использовать rpm.
Две полезные команды, которые установят все rpm-пакеты из текущей директории:
ls -l | grep rpm | awk '{print $9}' | xargs yum localinstall
ls -l | grep rpm | awk '{print $9}' | xargs rpm -Uhv
--------------
Как заставить apt-get установить вручную загруженные пакеты: http://www.opennet.dev/tips/info/1707.shtml
Для загрузки обновлений на внешней машине с Windows можно использовать Keryx
(http://www.opennet.dev/opennews/art.shtml?num=19650)
В графическом интерфейсе synaptic есть возможность сгенерировать скрипт для
загрузки выбранных пакетов
с их последующей установкой: "генерировать скрипт закачки пакетов" и "добавить закаченные пакеты".
|
| |
|
|
|
Инструкция по обновлению Fedora 9 до Fedora 10 (доп. ссылка 1) |
[комментарии]
|
| | Первым шагом обновляем базу пакетов текущего релиза:
yum -y update
Чистим кэш yum:
yum clean all
Устанавливаем пакет preupdate:
yum install preupgrade
Запускаем GUI интерфейс для проведения обновления (выбираем "Fedora 10"):
preupgrade
На сервере без X window запускаем консольный вариант:
preupgrade-cli "Fedora 10 (Cambridge)"
Вариант 2. Используем средсва yum.
Устанавливаем RPM-пакеты с параметрами нового релиза:
rpm -Uvh ftp://download.fedora.redhat.com/pub/fedora/linux/releases/10/Fedora/i386/os/Packages/fedora-release-*.noarch.rpm
Для архитектуры x86_64 меняем в пути "/i386/" на "/x86_64/"
Инициируем процесс обновления:
yum upgrade
При использовании репозитория RPMFusion, его нужно обновить отдельно:
rpm -Uvh http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-stable.noarch.rpm \
http://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-stable.noarch.rpm
yum -y update
|
| |
|
|
|
Общий yum cache для нескольких машин (доп. ссылка 1) |
Автор: Жольнай Кирилл
[комментарии]
|
| | Берем самый yum-активный из серверов локальной сети, и расшариваем /var/cache/yum по NFS:
В /etc/exports добавляем:
/var/cache/yum 192.168.0.212/255.255.255.0(rw)
Перезапускаем NFS:
service nfs restart
Включаем хранение кэша в /etc/yum.conf как на сервере, так и на клиенте:
В /etc/yum.conf меняем keepcache=0 на keepcache=1:
sed -i 's/keepcache=0/keepcache=1/' /etc/yum.conf
На клиентской машине монтируем нужные нам папки, в /etc/fstab добавляем:
# yum common cache
192.168.0.231:/var/cache/yum/base/packages /var/cache/yum/base/packages nfs
192.168.0.231:/var/cache/yum/updates/packages /var/cache/yum/updates/packages nfs
192.168.0.231:/var/cache/yum/addons/packages /var/cache/addons/base/packages nfs
192.168.0.231:/var/cache/yum/centosplus/packages /var/cache/addons/centosplus/packages nfs
192.168.0.231:/var/cache/yum/extras/packages /var/cache/addons/extras/packages nfs
И монтируем их:
mount -a
Если ему каких-нибудь папок не хватит - создайте:
mkdir -p /var/cache/yum/{base,updates,addons,centosplus,extras}/packages
Все, пакеты теперь будут скачиваться один раз.
В случае недоступности сервера ничего страшного не произойдет - просто пакет скачается.
|
| |
|
|
|
Использование DKMS для перестроения драйверов без их пересборки при обновлении Linux ядра |
[комментарии]
|
| | В Ubuntu 8.10 интегрирована технология DKMS (Dynamic Kernel Module Support, http://linux.dell.com/dkms),
позволяющая автоматически перестраивать текущие модули ядра с драйверами
устройств после обновления версии ядра.
Пример 1. Драйвер mad-wifi на ноутбуке Samsung R25 с wifi-картой на чипсете Atheros AR242x.
Оригинал заметки: http://blog.antage.name/2008/11/atheros-wifi-dkms.html
1. Ставим DKMS:
sudo apt-get install dkms
2. Качаем и распаковываем исходники драйвера:
cd
wget http://snapshots.madwifi-project.org/madwifi-hal-0.10.5.6/madwifi-hal-0.10.5.6-r3875-20081105.tar.gz
sudo tar xzf madwifi-hal-0.10.5.6-r3875-20081105.tar.gz -C /usr/src/
3. Создаем конфиг модуля в файле /usr/src/madwifi-hal-0.10.5.6-r3875-20081105/dkms.conf:
PACKAGE_NAME="madwifi-hal"
PACKAGE_VERSION="0.10.5.6-r3875-20081105"
AUTOINSTALL="yes"
BUILT_MODULE_NAME[0]="ath_pci"
BUILT_MODULE_LOCATION[0]="ath/"
DEST_MODULE_LOCATION[0]="/kernel/net/"
BUILT_MODULE_NAME[1]="ath_hal"
BUILT_MODULE_LOCATION[1]="ath_hal/"
DEST_MODULE_LOCATION[1]="/kernel/net/"
BUILT_MODULE_NAME[2]="ath_rate_sample"
BUILT_MODULE_LOCATION[2]="ath_rate/sample/"
DEST_MODULE_LOCATION[2]="/kernel/net/"
BUILT_MODULE_NAME[3]="ath_rate_minstrel"
BUILT_MODULE_LOCATION[3]="ath_rate/minstrel/"
DEST_MODULE_LOCATION[3]="/kernel/net/"
BUILT_MODULE_NAME[4]="ath_rate_amrr"
BUILT_MODULE_LOCATION[4]="ath_rate/amrr/"
DEST_MODULE_LOCATION[4]="/kernel/net/"
BUILT_MODULE_NAME[5]="ath_rate_onoe"
BUILT_MODULE_LOCATION[5]="ath_rate/onoe/"
DEST_MODULE_LOCATION[5]="/kernel/net/"
BUILT_MODULE_NAME[6]="wlan"
BUILT_MODULE_LOCATION[6]="net80211/"
DEST_MODULE_LOCATION[6]="/kernel/net/"
BUILT_MODULE_NAME[7]="wlan_scan_ap"
BUILT_MODULE_LOCATION[7]="net80211/"
DEST_MODULE_LOCATION[7]="/kernel/net/"
BUILT_MODULE_NAME[8]="wlan_scan_sta"
BUILT_MODULE_LOCATION[8]="net80211/"
DEST_MODULE_LOCATION[8]="/kernel/net/"
BUILT_MODULE_NAME[9]="wlan_tkip"
BUILT_MODULE_LOCATION[9]="net80211/"
DEST_MODULE_LOCATION[9]="/kernel/net/"
BUILT_MODULE_NAME[10]="wlan_xauth"
BUILT_MODULE_LOCATION[10]="net80211/"
DEST_MODULE_LOCATION[10]="/kernel/net/"
BUILT_MODULE_NAME[11]="wlan_wep"
BUILT_MODULE_LOCATION[11]="net80211/"
DEST_MODULE_LOCATION[11]="/kernel/net/"
BUILT_MODULE_NAME[12]="wlan_ccmp"
BUILT_MODULE_LOCATION[12]="net80211/"
DEST_MODULE_LOCATION[12]="/kernel/net/"
BUILT_MODULE_NAME[13]="wlan_acl"
BUILT_MODULE_LOCATION[13]="net80211/"
DEST_MODULE_LOCATION[13]="/kernel/net/"
4. Добавлем драйвер в DKMS:
sudo dkms add -m madwifi-hal -v 0.10.5.6-r3875-20081105
5. Собираем и инсталлируем:
sudo dkms build -m madwifi-hal -v 0.10.5.6-r3875-20081105
sudo dkms install -m madwifi-hal -v 0.10.5.6-r3875-20081105
Пример 2. Автосборка модуля файловой системы BTRFS при обновлении ядра.
Оригинал заметки: http://deepwalker.blogspot.com/2008/11/810-dkms-nvidia-btrfs.html
Загружаем исходники модуля ядра и кладем их в /usr/src/btrfs-0.16.
В том же каталоге создаем dkms.conf следующего содержания:
MAKE[0]=make
BUILT_MODULE_NAME[0]=btrfs
DEST_MODULE_LOCATION[0]="/kernel/fs/btrfs"
PACKAGE_NAME="btrfs"
PACKAGE_VERSION="0.16"
CLEAN="make clean"
AUTOINSTALL="yes"
Далее следует серия команд для запуска модуля в работу:
# dkms add -m btrfs -v 0.16
# dkms add -m btrfs -v 0.16
Creating symlink /var/lib/dkms/btrfs/0.16/source -> /usr/src/btrfs-0.16
DKMS: add Completed.
# dkms build -m btrfs -v 0.16
Kernel preparation unnecessary for this kernel. Skipping...
Building module:
cleaning build area....
make KERNELRELEASE=2.6.27-7-generic............
cleaning build area....
DKMS: build Completed.
# dkms install -m btrfs -v 0.16
Running module version sanity check.
btrfs.ko:
- Original module
- No original module exists within this kernel
- Installation
- Installing to /lib/modules/2.6.27-7-generic/updates/dkms/
depmod........
DKMS: install Completed.
modprobe btrfs
|
| |
|
|
|
Решение проблем с некорректно установленными пакетами в Debian и Ubuntu (доп. ссылка 1) |
Автор: Okulov Vitaliy
[комментарии]
|
| | После обновления ОС и установки gnome столкнулся с проблемой:
dpkg: ../../src/packages.c:191: process_queue: Assertion 'dependtry <= 4' failed
Соотвественно пакеты больше не ставились и не обновлялись. Погуглив решил
проблему следующим образом:
sudo dpkg -l | grep -v ^ii
dpkg -l выводит список установленных пакетов,
grep -v ^ii - оставляет в выводе только неправильно установленные пакеты.
После получения списка таких пакетов, удалил первый из списка неправильно
установленный пакет командой
sudo dpkg -purge remove имя_пакета
После вышеуказанных манипуляций проблема ушла.
|
| |
|
|
|
Примеры использования пакетного менеджера Zypper в openSUSE (доп. ссылка 1) |
[комментарии]
|
| | Найти заданный пакет по имени:
zypper se banshee-1
zypper se bans*
По умолчанию в результатах поиска отображается имя, описание и тип. Для промотора
дополнительных параметров, например, номера версии и имени репозитория, можно использовать:
zypper se -s пакет
Вывод краткой справки по пакету:
zypper if пакет
Удаление пакетов по маске:
zypper rm gtk*devel*
Установка пакетов по маске:
zypper in gtk-sharp?
Удаление пакета с версией старше заданной:
zypper rm пакет>1.2.3
Установка и удаление одной командой:
zypper in пакет_для_установки -пакет_для_удаления +пакет_для_установки
Принудительная установка уже присутствующего в системе пакета:
zypper in --force пакет
Установка RPM пакетов из файла, а не из репозитория:
zypper in ./file.rpm
zypper in http://<;url>/file.rpm
Обновить все установленные в системе пакеты (исправления проблем безопасности и
критических ошибок):
zypper up
Обновить систему до более новой версии openSUSE:
zypper dup
Установить программы, необходимые для пересборки заданного пакета из исходных текстов:
zypper si -d пакет
Посмотреть список мета-пакетов (сгруппированных наборов):
zypper pt
Установить мета-пакет:
zypper in -t pattern xfce
Найти мета-пакет по маске:
zypper se -t pattern media
Посмотреть список доступных репозиториев пакетов:
zypper lr
Добавить новый репозиторий:
zypper ar <url> <name>
Временно отключить первый репозиторий в списке:
zypper mr -d 1
Временно отключить репозиторий по имени:
zypper mr -d repo-oss
Удалить первый репозиторий из списка:
zypper rr 1
Выполнение действия в тестовом режиме, без фактического выполнения операции:
zypper in --dry-run пакет
Заморозить состояние пакета в текущем виде, для предотвращения случайной установки или удаления:
zypper addlock пакет
Снятие блокировки:
zypper removelock пакет
|
| |
|
|
|
Установка OpenSUSE на удаленной машине с управлением по SSH (доп. ссылка 1) |
[обсудить]
|
| | На машине, на которой планируется установка, загружаем ядро и образ ram-диска:
cd /tmp
wget http://mirrors.kernel.org/opensuse/distribution/11.0/repo/oss/boot/i386/loader/linux
wget http://mirrors.kernel.org/opensuse/distribution/11.0/repo/oss/boot/i386/loader/initrd
cp linux /boot/vmlinuz.install
cp initrd /boot/initrd.install
Модифицируем настройки Grub, /boot/grub/menu.lst (параметры kernel нужно переписать в одну строку)
title Boot -- openSUSE 11.0
root (hd0,0)
kernel /boot/vmlinuz.install noapic usessh=1 sshpassword="12345645"
install=http://mirrors.kernel.org/opensuse/distribution/11.0/repo/oss/
hostip=192.168.42.2 gateway=192.168.42.1 nameserver=192.168.42.1
initrd /boot/initrd.install
Где
192.168.42.2 - IP машины на которую производится установка,
192.168.42.1 - DNS и шлюз
12345645 - пароль по которому будет осуществлен вход на устанавливаемую машину по SSH
Скрипт для автоматизации вышеприведенных действий можно загрузить по ссылке
http://www.suse.de/~lnussel/setupgrubfornfsinstall.html
После перезагрузки, заходим c паролем 12345645:
ssh -X root@192.168.42.2
и начинаем процесс установки запустив yast (текстовый режим) или yast2 (графический режим).
В случае обрыва процесса установки его можно продолжить, повторив настройки grub
и выполнив после входа по SSH:
/usr/lib/YaST2/startup/YaST2.ssh
При наличии "чистой" машины образ ядра можно загрузить по сети при помощи PXE.
Пример можно найти в материале: http://wiki.opennet.ru/NetworkBoot
Конфигурация pxelinux будет выглядеть примерно так:
default pxelinux
prompt 1
timeout 600
label pxelinux.install
kernel vmlinuz
append initrd=initrd.install noapic usessh=1 sshpassword="12345645"
install=http://mirrors.kernel.org/opensuse/distribution/11.0/repo/oss/
hostip=192.168.42.2 gateway=192.168.42.1 nameserver=192.168.42.1
|
| |
|
|
|
Создание установочного LiveUSB с Ubuntu и OpenSUSE Linux (доп. ссылка 1) |
Автор: Roman Tuz
[комментарии]
|
| | Подготовка загрузочного Flash для установки Ubuntu Linux.
Устанавливаем syslinux:
sudo apt-get install syslinux
Устанавливаем загрузчик на Flash (/dev/sdb1 - определить можно из вывода mount или dmesg):
syslinux -s /dev/sdb1
Копируем полностью содержимое стандартного установочного LiveCD диска с Ubuntu Linux на Flash.
Копируем из директории casper два файла vmlinuz и initrd.gz в корень Flash,
а также все файлы из деректорий isolinux и install.
Переименовываем файл isolinux.cfg в syslinux.cfg.
Другой вариант - создание LiveUSB через специальный GUI интерфейс:
В /etc/apt/sources.list добавляем репозиторий:
deb http://ppa.launchpad.net/probono/ubuntu hardy main
Ставим пакет liveusb:
sudo apt-get update
sudo apt-get install liveusb
Монтируем образ загрузочного диска:
sudo mount -o loop -tiso9660 ubuntu-8.04.1-desktop-i386.iso /cdrom
Запускаем программу из "Система" - "Администрирование" - "Установить Live USB".
Для создания установочного USB диска с OpenSUSE выполняем.
Устанавливаем syslinux:
zypper install syslinux
Монтируем установочный ISO образ в директорию /mnt
mount -o loop ./openSUSE-11.0-DVD-i386.iso /mnt/cdrom
Вставляем usb flash и находим устройство к которому она подключена, анализируя вывод команд:
fdisk -l
cat /proc/partitions
mount
dmesg
После того как определили искомый /dev/sdb, монтируем Flash:
mount /dev/sdb /mnt/flash
Копируем на Flash содержимое установочного диска, отдельно перенеся загрузчик в корень:
cp /mnt/cdrom/boot/i386/loader/* /mnt/flash
и переименовав файл конфигурации:
mv /mnt/flash/isolinux.cfg /mnt/flash/syslinux.cfg
Отмонтируем flash и устанавливаем загрузчик:
umount /mnt/flash
syslinux /dev/sdb
|
| |
|
|
|
Как заставить apt-get установить вручную загруженные пакеты |
[комментарии]
|
| | В графическом интерфейсе synaptic есть возможность сгенерировать скрипт для
загрузки выбранных пакетов
с их последующей установкой: "генерировать скрипт закачки пакетов" и "добавить закаченные пакеты".
Там где synaptic недоступен, можно поступить иначе:
При указании опции --print-uris в apt-get, вместо установки будет выведен список адресов
для загрузки выбранных пакетов с учетом зависимостей.
apt-get -y --print-uris install список_пакетов
посмотреть какие пакеты нужно загрузить для обновления:
apt-get -y --print-uris upgrade
apt-get -y --print-uris dist-upgrade
посмотреть какие индексы нужно загрузить:
apt-get --print-uris update
Эти пакеты можно загрузить отдельно и скопировать в /var/cache/apt/archives, например:
apt-get -qq -y --print-uris upgrade | cut -f1 -d' ' | tr -d "'" > packet_list.txt
cd /var/cache/apt/archives
wget --input-file packet_list.txt
затем повторить команду "apt-get install список_пакетов", пакеты будут установлены из кэша
Вместо /var/cache/apt/archives можно указать и другую директорию:
apt-get -o dir::cache::archives="/download" install список_пакетов
|
| |
|
|
|
Использование http-прокси в APT и при обновлении Ubuntu |
Автор: Heckfy
[комментарии]
|
| | Для обновления дистрибутива ubuntu до новейшего необходимо выполнить:
$ sudo update-manager -d
Если сообщения о новом дистрибутиве почему-то нет, но оно должно быть,
необходимо настроить "Сервис прокси".
Пример:
$ http_proxy='http://proxy.test.ru:3128/' sudo update-manager -d
Апдейт менеджер можно заменить на do-release-upgrade
Работа apt-get и некоторых других консольных приложений через прокси
осуществляется аналогичным образом:
export http_proxy=http://username:password@host:port/
export ftp_proxy=http://username:password@host:port/
Еще один способ конфигурирования работы apt через прокси:
Создаем /etc/apt/apt.conf.d/01proxy:
Acquire {
http::Proxy "http://username:password@host:port/";
}
|
| |
|
|
|
Настройка поддержки мультимедиа в Ubuntu 8.04 (доп. ссылка 1) |
[комментарии]
|
| | Подсказка про установку аудио и видео-кодеков, поддержки просмотра защищенных DVD.
sudo apt-get install gstreamer0.10-plugins-ugly-multiverse \
gstreamer0.10-plugins-bad-multiverse gstreamer0.10-plugins-bad \
gstreamer0.10-plugins-ugly gstreamer0.10-ffmpeg libxine1-ffmpeg \
libdvdread3 liblame0
В /etc/apt/sources.list добавляем репозиторий Medibuntu:
deb http://packages.medibuntu.org/ hardy free non-free
Импортируем PGP ключ и устанавливаем libdvdcss2 и w32-кодеки:
wget -q http://packages.medibuntu.org/medibuntu-key.gpg -O- \
| sudo apt-key add -
sudo apt-get update
sudo apt-get install libdvdcss2 w32codecs ffmpeg
Дополнительные закрытые компоненты, включая flash плагин, java, шрифты.
sudo apt-get install flashplugin-nonfree libflashsupport
(или можно поставить открытый аналог flash - mozilla-plugin-gnash)
sudo apt-get install sun-java6-fonts sun-java6-jre sun-java6-plugin
sudo apt-get install msttcorefonts
Поддержку мультимедиа можно поставить одной командой:
sudo apt-get install ubuntu-restricted-extras
Для Kubuntu - kubuntu-restricted-extras, для xubuntu - xubuntu-restricted-extras
Недостающие кодеки для Ubuntu и Debian можно попытаться найти в репозитории http://debian-multimedia.org/
|
| |
|
|
|
Как в Debian/Ubuntu установить пакет с диска с учетом зависимостей (доп. ссылка 1) |
Автор: Tigro
[комментарии]
|
| | Установка .deb пакета, уже загруженного на локальный диск,
с разрешением зависимостей и доустановкой недостающих пакетов:
gdebi пакет.deb
|
| |
|
|
|
Перекомпиляция пакета в Debian и Ubuntu (доп. ссылка 1) |
[комментарии]
|
| | Перекомпиляция пакета может понадобиться например, для упаковки более новой версии программы,
наложения определенного патча или пересборки с особенными опциями.
Устанавливаем программы, необходимые для сборки пакетов:
apt-get install devscripts
apt-get install build-essential
В /etc/apt/sources.list раскомментируем строки с deb-src для нужного репозитория, например:
deb-src http://ftp.us.debian.org/debian/ etch main non-free contrib
Загружаем пакет с исходными текстами в текущую директорию:
apt-get source имя_пакета
Если под рукой уже есть .dsc, tar.gz и diff.gz файлы, раскрываем их командой:
dpkg-source -x имя_пакета.dsc
Устанавливаем зависимые пакеты (библиотеки, заголовочные файлы и т.д.), требуемые для сборки:
apt-get build-dep имя_пакета
Вносим изменения в появившейся директории "имя_пакета-версия".
Если собрались импортировать в пакет более новую версию программы, то
воспользуемся утилитой uupdate:
uupdate -u путь_к_tar_gz_архиву_c_более_новой_версией_программы
При этом в автоматическом режиме будут адаптированы патчи от старой версии,
в случае несостыковок придется исправлять патчи руками.
Собираем пакет:
cd имя_пакета-версия
debuild -us -uc
"-us" и "-uc" указываем так как не являемся мантейнером пакета и не можем
создать цифровую подпись для пакета.
Вместо враппера debuild можем напрямую использовать:
dpkg-buildpackage -rfakeroot
После сборки готовый пакет появится в родительской директории, устанавливаем его:
cd ..
dpkg -i <package_file.deb>
Пример для пакета с MySQL:
mkdir build
cd build
apt-get source mysql-server-5.0
apt-get build-dep mysql-server-5.0
cd mysql-dfsg-5.0-5.0.32
debuild -us -uc
cd ..
dpkg -i *.deb
|
| |
|
|
|
Как обновить только пакеты находящиеся в архиве APT (доп. ссылка 1) |
Автор: Stanislav Kislicin
[обсудить]
|
| | Для того чтобы заставить apt обновить систему используя только пакеты из кэша /var/cache/apt/archives,
а не лезть за ними в интернет, нужно выполнить:
apt-get -no-download -ignore-missing upgrade
Если пакета нет в кэше, он не будет поставлен.
|
| |
|
|
|
Обеспечение безопасности посредством GLSA в Gentoo Linux (доп. ссылка 1) |
Автор: daevy
[комментарии]
|
| | Постоянное обновление системы - одно из важнейших мероприятий по обеспечению безопасности.
Можно следить за обновлениями посредством GLSA, для этого не обходимо
чтобы в системе был установлен пакет app-portage/gentoolkit.
в составе пакета идет утилита glsa-check, с которой нам и предстоит работать.
Итак преступим.
Сначала можно посмотреть все доступные выпуски GLSA
# glsa-check -l
Все строки, содержащие [A] и [U], можно проигнорировать, т.к. они неприменимы для данной системы.
Теперь проверим подвержена ли наша система GLSA
# glsa-check -t all
Или можно просмотреть пакеты которые необходимо переустановить
# glsa-check -p $(glsa-check -t all)
И применить их...
# glsa-check -f $(glsa-check -t all)
И конечно перезапускаем те демоны, которые подверглись переустановке.
|
| |
|
|
|
Установка пакетов с пересборкой из исходных текстов в Ubuntu Linux (доп. ссылка 1) |
Автор: openkazan.info
[комментарии]
|
| | Устанавливаем пакет apt-build:
apt-get install apt-build
Настраиваем его командой dpkg-reconfigure apt-build, тут нам надо будет ответить
на вопросы об уровне оптимизации и об архитектуре вашего процессора.
Далее надо убедится, что у нас раскоментированы репозитарии исходников в /etc/apt/sources.list
(эти строки начинаются с deb-src). Обновляем список репозитариев apt-get update.
Ну и всё, дальше вместо apt-get используем apt-build. Ключи и опции apt-build такие же как и у apt-get:
apt-build update - обновление списка репозитариев и софта в них,
apt-build upgrade - апгрейд установленных пакетов,
apt-build install - устанавливаем программу,
apt-build world - а это перекомпилит всю вашу систему! Тут всё на ваш страх и риск!
При первом запуске apt-build вы увидите следующее сообщение об ошибке:
-----Rebuilding the world!-----
-----Building package list-----
Please read README.Debian first.
Просто apt-build не знает какой софт у вас установлен.
Для того чтобы побороть эту ошибку достаточно ввести команду:
dpkg --get-selections | awk '{if ($2 == "install") print $1}'> /etc/apt/apt-build.list
Ну а дальше работаем с apt-build как с apt-get.
Рекомендую вставлять ключи --yes and --force-yes для того чтобы весь процесс
проходил на автомате.
|
| |
|
|
|
Использование шаблонов при поиске пакетов в Aptitude (доп. ссылка 1) |
Автор: jetxee
[комментарии]
|
| | Список полезных шаблонов, которые можно использовать в aptitude search
~nимя - в имени встречается текст "имя" (можно использовать
регулярные выражения, например, ~n^lib отбирает только имена начинающиеся с lib)
~dтекст - в описании пакета встречается "текст" (очень полезно, если название программы
неизвестно, но известно, что она должна делать)
~i - отбирает только уже установленные пакеты
~N - отбирает только новые пакеты (которых раньше не было в репозитории)
~U - отбирает пакеты, которые можно обновить
~Dтребование - отбирает пакеты, которые зависят от "требования"
(можно использовать регулярные выражения)
~Rзависимый - отбирает пакеты, которые необходимы для "зависимого"
(можно использовать регулярные выражения)
| - логическое "ИЛИ"
! - логическое отрицание
Например:
Найти пакеты в имени которого встречается kde:
aptitude search ~nkde
Найти пакеты в описании к которым встречается HDR и image:
aptitude search ~dHDR~dimage
Найти пакеты в названии которых встречается aptitude. но в системе они не установлены:
aptitude search '!~i~naptitude'
Найти установленные пакеты в названии которых встречается firefox или iceweasel:
aptitude search '~i(~nfirefox|~niceweasel)'
|
| |
|
|
|
|
|
Модификация образа загрузочного RAM диска (initrd) в Linux |
[комментарии]
|
| | Задача добавить модуль ядра usb-storage в "initrd.img" от Fedora Linux
для загрузки с диска с USB интерфейсом.
mkdir ./initrd
mv ./initrd.img ./initrd.img.gz
gunzip ./initrd.img
Метод 1. initrd.img в виде сжатого образа файловой системы
mount -o loop ./initrd.img ./initrd
Метод 2. initrd.img в виде сжатого cpio архива
cd ./initrd
cpio -ic < ../initrd.img
Копируем в ./initrd/lib модуль usb-storage.ko
(следим, чтобы уже были модули scsi_mod.ko, (o|e|u)hci-hcd.ko, usbcore.ko)
Прописываем "insmod /lib/usb-storage.ko" в конец списка загрузки модулей ./initrd/init
Может потребоваться скопировать команду sleep и прописать после
загрузки модуля usb-storage задержку, необходимую на обнаружения накопителя.
umount ./initrd # для метода 1.
cd ./initrd
find . -print| cpio -oc |gzip -9 -c > ../initrd_new.img # для метода 2.
Другой вариант упаковки (для Fedora 8):
find . -print| cpio -H newc -o |gzip -9 -c > ../initrd_new.img
При загрузке с USB диска большого объема (250Гб) при установке ОС в
разделе в центре диска не удалось использовать Lilo и Grub. Lilo при
загрузке ругался на несоответствие текущей геометрии диска той что
была в момент его установки. Установка Grub привела к зависанию
ноутбука в момент опроса USB диска (проблема BIOS). Выход нашелся в
установке загрузчика от FreeBSD:
1. Делаем бэкап текущего MBR USB диска:
dd if=/dev/sda of=mbr_sda.bin bs=1 count=512
2. Берем boot0 из комплекта FreeBSD и копируем в него данные о таблицах разделов текущего диска:
dd if=mbr_sda.bin of=boot0 bs=1 count=66 skip=446 seek=446
3. Копируем загрузчик в MBR USB диска:
dd if=boot0 of=/dev/sda bs=1 count=512
4. В текущий раздел Linux устанавливаем Grub:
# grub
grub> find /boot/grub/stage1
(hd0,1) раздел /dev/sda2
grub> root (hd0,1)
grub> setup (hd0,1)
|
| |
|
|
|
apt + gpg: как добавить сигнатуру репозитория |
Автор: Heckfy
[комментарии]
|
| | После обновления до Etch в APT появилось много изменений. Одно из них - защита
от подмены доменной записи.
# apt-get update
W: GPG error: http://deb.opera.com stable Release:
The following signatures couldn't be verified because the public key is not available:
+NO_PUBKEY 033431536A423791
W: You may want to run apt-get update to correct these problems
Для решения проблемы с "apt-get update" предлагается запустить "apt-get
update". Не будем зацикливаться.
Получим публичный ключ и сохраним его в пользовательской базе:
$ sudo gpg --keyserver subkeys.pgp.net --recv-keys 033431536A423791
gpg: requesting key 6A423791 from hkp server subkeys.pgp.net
gpg: key 6A423791: public key "Opera Software Archive Automatic Signing Key <hostmaster@opera.com>" imported
gpg: no ultimately trusted keys found gpg: Total number processed: 1
gpg: imported: 1
Теперь отдадим нашему apt ключ:
$ gpg --armor --export 033431536A423791 | sudo apt-key add -
OK
Что-то произошло.
$ ls -l /etc/apt
total 40
-rw-r--r-- 1 root root 2524 Nov 14 2006 apt-file.conf
drwxr-xr-x 2 root root 112 May 27 02:54 apt.conf.d
-rw-r--r-- 1 root root 98 May 27 02:54 listchanges.conf
-rw------- 1 root root 0 May 25 10:08 secring.gpg
-rw-r--r-- 1 root root 1059 May 25 02:15 sources.list
-rw-r--r-- 1 root root 812 May 24 00:19 sources.list-sarge
drwxr-xr-x 2 root root 48 Feb 27 00:21 sources.list.d
-rw-r--r-- 1 root root 632 Nov 12 2005 sources.list~
-rw------- 1 root root 1200 May 30 10:26 trustdb.gpg
-rw-r--r-- 1 root root 4473 May 30 10:26 trusted.gpg
-rw-r--r-- 1 root root 4473 May 30 10:26 trusted.gpg~
Сегодня - May 30. Не знаю, что там в trust*, но это нравится нашему apt:
$ sudo apt-get update
Ign file: stable Release.gpg Ign file: stable Release.gpg
Ign file: stable Release.gpg Get:1 file: stable Release [802B]
Get:2 file: stable Release [627B] Get:3 file: stable Release [627B]
Ign file: stable/main Packages
Ign file: stable/main Packages
Ign file: stable/main Packages
Get:4 http://deb.opera.com stable Release.gpg [189B] Hit http://deb.opera.com stable Release
Ign http://deb.opera.com stable/non-free Packages/DiffIndex
Ign http://deb.opera.com stable/non-free Packages
Hit http://deb.opera.com stable/non-free Packages Fetched 189B in 0s (227B/s)
Reading package lists... Done
На всякий случай, посмотрим, что еще изменилось за сегодня в системе:
$ locate gpg > 1
# updatedb && locate gpg > 2 && diff 1 2
56a60,65
> /home/hec/.gnupg/pubring.gpg
> /home/hec/.gnupg/pubring.gpg~
> /home/hec/.gnupg/secring.gpg
> /home/hec/.gnupg/trustdb.gpg
> /home/hec/.local/share/applications/menu-xdg/X-Debian-Apps-Tools-kgpg.desktop
390c404
< /var/lib/apt/lists/partial/deb.opera.com_opera_dists_stable_Release.gpg
---
> /var/lib/apt/lists/deb.opera.com_opera_dists_stable_Release.gpg
Создались и изменились файлы в ~/.gnupg и deb.opera.
com_opera_dists_stable_Release.gpg перешел из /var/lib/apt/lists/partial/ в /var/lib/apt/lists/
Ссылки по теме:
http://strugglers.net/wiki/The_following_signatures_couldn't_be_verified
http://www.osp.ru/lan/1997/07/132968/ - Атака и защита DNS
|
| |
|
|
|
Примеры управления пакетами через dpkg (доп. ссылка 1) |
[комментарии]
|
| | Установка одного пакета:
dpkg -i <.deb file name>
Пример: dpkg -i avg71flm_r28-1_i386.deb
Рекурсивная установка группы пакетов помещенных в директорию:
dpkg -R
Пример: dpkg -R /usr/local/src
Распаковать пакет, но не переходить на стадию конфигурации:
dpkg --unpack package_file
Пример: dpkg --unpack avg71flm_r28-1_i386.deb
Выполнить стадию конфигурирования для ранее распакованного пакета:
dpkg --configure package
Пример: dpkg --configure avg71flm_r28-1_i386.deb
Удаление ранее установленного пакета, с сохранением файлов конфигурации:
dpkg -r
Пример: dpkg -r avg71flm_r28-1_i386.deb
Удаление ранее установленного пакета, с удалением файлов конфигурации:
dpkg -P
Пример: dpkg -P avg71flm
Обновление информации о доступных для установки пакетах из файла "Packages.dpkg"
dpkg --update-avail <Packages-file>
Добавление (комбинирование) информации о дополнительных пакетах из файла "Packages.dpkg"
dpkg --merge-avail <Packages-file>
Обновление информации о пакете непосредственно из пакета:
dpkg -A package_file
Удалить информацию о ранее установленных, но удаленных, и теперь недоступных, пакетах:
dpkg --forget-old-unavail
Удалить информацию о доступности пакетов:
dpkg --clear-avail
Найти частично установленные пакеты:
dpkg -C
Отобразить различия в двух наборах пакетов:
dpkg --compare-versions ver1 op ver2
Построить deb пакет:
dpkg -b directory [filename]
Показать содержимое пакета:
dpkg -c filename
Показать информацию о пакете:
dpkg -I filename [control-file]
Показать список пакетов удовлетворяющих маске:
dpkg -l package-name-pattern
Пример: dpkg -l vim
Показать список всех установленных пакетов:
dpkg -l
dpkg --get-selections
Установить пакеты, по списку сохраненному в файле:
apt-get update
cat файл_со_списком_пакетов| dpkg --set-selections
apt-get dselect-upgrade
Отобразить состояние пакета
dpkg -s package-name
Пример: dpkg -s ssh
Показать список файлов в системе, добавленных из указанного пакета.
dpkg -L package-Name
Пример: dpkg -L apache2
Поиск пакета по входящему в его состав файлу:
dpkg -S filename-search-pattern
Пример: dpkg -S /sbin/ifconfig
Вывод детальной информации о пакете:
dpkg -p package-name
Пример: dpkg -p cacti
|
| |
|
|
|
Установка CentOS и FC 6 на материнские платы Intel P965 (ICH8R) с IDE-CDROM |
Автор: Державец Борис
[комментарии]
|
| | Установка CentOS 4.4 (RHEL AS 4.4) и FC 6 на материнские платы с чипсетом
Intel P965 & Intel ICH8R с IDE-CDROM'a.
1.Установить в BIOS режим AHCI для Intel ICH8R и Jmicron JMB363
2.На подсказке
boot:linux all-generic-ide pci=nommconf
3. Cпецифицировать во время графической установки
Kernel boot options :
all-generic-ide pci=nommconf
При установке GRUB в /boot partition выполнить:
boot:linux all-generic-ide pci=nommconf rescue
...................
# chroot /mnt/sysimage
# df -h
/dev/sdaX ....... /boot
.............................
# dd if=/dev/sdaX of=linux.bin bs=512 count=1
# mcopy linux.bin a:
Такой стиль установки позволяет системам успешно определять
IDE-CDROM не только при установке , но и в рабочем режиме.
|
| |
|
|
|
Как автоматизировать установку Debian и Fedora Linux (доп. ссылка 1) |
[обсудить]
|
| | Инсталлятор Debian можно заставить использовать файл ответов на вопросы установки (pre-seeding).
Установите пакет debconf-utils
apt-get install debconf-utils
Создайте pre-seeding файл для повторения начальной установки:
debconf-get-selections --installer > preseed.cfg
Добавьте последующие изменения:
debconf-get-selections >> preseed.cfg
При необходимости отредактируйте preseed.cfg на свой вкус и скопируйте на дискету.
В момент загрузки передайте в качестве параметра путь к preseed.cfg файлу (как
опции загрузки ядра):
preseed/file=/floppy/preseed.cfg debconf/priority=critical
Что касается Fedora, то создать файл автоустановки можно использовав пакет system-config-kickstart:
yum -y install system-config-kickstart
/usr/sbin/system-config-kickstart
После запуска в диалоговом режиме будет сформировано содержание файла ks.cfg,
информацию о котором нужно передать как параметр при загрузке:
linux ks=/floppy/ks.cfg
|
| |
|
|
|
Локальный репозитарий CentOS через HTTP proxy |
[комментарии]
|
| | До появления прямого соединения с интернетом (провайдером был открыт только http),
было довольно проблематично поддерживать локальный репозитарий пакетов в актуальном состоянии.
Для выхода из подобной ситуации был написан следующий скрипт,
который в некотором приближении заменяет rsync.
#!/bin/sh
cd /opt/rpm-update
#mirror_base_url=http://ftp.belnet.be/packages/centos/4.3/os/i386/CentOS/RPMS/
#mirror_update_url=http://ftp.belnet.be/packages/centos/4.3/updates/i386/RPMS/
mirror_base_url=$1
local_rpm_directory=$2
#local_rpm_directory=/var/ftp/pub/centos-4.3/
file_html=./index.html
file_rpms=./files.log
rm -f $file_html
rm -f $file_rpms
echo "---------------------------------------------------------"
echo "obtaining file list from $mirror_base_url ..."
wget -q --no-cache $mirror_base_url
echo "ok."
cut -d"=" $file_html -f4 | cut -d"\"" -f2 | grep rpm | sort > $file_rpms
a=`cat $file_rpms`
for cur_rpm in $a
do
cur_rpm_file=$local_rpm_directory$cur_rpm
if [ -e $cur_rpm_file ]
then
echo "$cur_rpm exist." > /dev/null
else
echo "downloading $cur_rpm ..."
wget -q --no-cache $mirror_base_url$cur_rpm
echo "ok."
mv ./$cur_rpm $local_rpm_directory
fi
done
rm -f $file_html
rm -f $file_rpms
и вызов этого скрипта
#!/bin/sh
echo "***** run4 START ***** " >> /var/log/rpm_update4
/opt/rpm-update/lsus.sh
http://ftp.belnet.be/packages/centos/4.3/updates/i386/RPMS/ /var/ftp/pub/centos-4.3/
>> /var/log/rpm_update4
/opt/rpm-update/lsus.sh
http://ftp.belnet.be/packages/centos/4.3/os/i386/CentOS/RPMS/ /var/ftp/pub/centos-4.3/
>> /var/log/rpm_update4
/opt/rpm-update/lsus.sh
http://ftp.belnet.be/packages/centos/4.3/extras/i386/RPMS/ /var/ftp/pub/centos-4.3/
>> /var/log/rpm_update4
echo "generating headers..." >> /var/log/rpm_update4
yum-arch -q /var/ftp/pub/centos-4.3/
echo "ok." >> /var/log/rpm_update4
echo "generating repo..." >> /var/log/rpm_update4
createrepo -q /var/ftp/pub/centos-4.3/
echo "ok." >> /var/log/rpm_update4
echo "***** run4 STOP ***** " >> /var/log/rpm_update4
вызывается по крону, если на сервере появились свежие пакеты, быстренько
заливает их в локальный репозитарий.
|
| |
|
|
|
Как обновить содержимое установочного DVD для Fedora Core 5 Linux (доп. ссылка 1) |
Автор: Rob Garth
[комментарии]
|
| | Копируем обновления на локальную машину
http://download.fedora.redhat.com/pub/fedora/linux/core/updates/5/i386/
Создаем директорию, в которой будем создавать новый образ диска.
mkdir -p /opt/FC_2006.4/i386
cd /opt/FC_2006.4
Монтируем оригинальный установочный диск
mount -o loop /full/path/FC-5-i386-DVD.iso /mnt
и синхронизируем его содержимое, за исключением rpm пакетов, в созданную ранее директорию.
rsync --archive --exclude 'Fedora/RPMS/*.rpm' /mnt/ i386
Копируем только актуальные rpm пакеты для которых не было обновлений.
Наличие обновлений отслеживаем при помощи утилиры novi.
for fn in `novi path/to/updates /mnt/Fedora/RPMS/ | awk '{print $2}'`; do
cp $fn i386/Fedora/RPMS/
done
Обновляем индексные файлы
cd i386
createrepo -u "media://1142397575.182477#1" -g Fedora/base/comps.xml .
cd ..
Создаем ISO образ и md5 слепок.
mkisofs -R -J -T -v -no-emul-boot -boot-load-size 4 -boot-info-table \
-V "Fedora Core 5 (Patched.0406)" -b isolinux/isolinux.bin \
-c isolinux/boot.cat -x "lost+found" -o FC5-i386-dvd-patched.iso i386
/usr/lib/anaconda-runtime/implantisomd5 FC5-i386-dvd-patched.iso
|
| |
|
|
|
Пример настройки сервера удаленной загрузки под Linux (доп. ссылка 1) |
[комментарии]
|
| | DHCP.
dhcpd.conf:
# расскоментировать для DHCPD 3.0
# ddns-update-style none;
group {
# IP address of TFTP/NFS server
next-server 10.0.0.3;
# The name of the file to be downloaded by the ROM
filename "/tftpboot/pxelinux.0";
# A default server directory to be used as / by the clients
#option root-path "/clients/shared/root";
# IP addresses of DNS servers
#option domain-name-servers XX.XX.XX.XX, YY.YY.YY.YY;
# IP addresses of routers
#option routers AA.AA.AA.AA, BB.BB.BB.BB;
# An entry for one specific client
host sample-client {
# Ethernet address of the client machine
hardware ethernet EE:EE:EE:EE:EE:EE;
# IP address to assign
fixed-address 10.0.1.1;
# Override root-path option for this machine
# Our initial configuration will use separate
# root directories for each client.
option root-path "/clients/10.0.1.1/root";
}
}
NFS.
/etc/exports на сервере:
/clients/10.0.1.1/root 10.0.1.1/255.255.255.255(rw,no_root_squash)
/clients/10.0.1.1/usr 10.0.1.1/255.255.255.255(rw,no_root_squash)
/clients/10.0.1.1/var 10.0.1.1/255.255.255.255(rw,no_root_squash)
/clients/10.0.1.1/tmp 10.0.1.1/255.255.255.255(rw,no_root_squash)
/home 10.0.0.0/255.0.0.0(rw)
/etc/fstab для клиента:
10.0.0.3:/clients/10.0.1.1/root / nfs rw,hard,intr,nolock 0 0
10.0.0.3:/clients/10.0.1.1/usr /usr nfs rw,hard,intr,nolock 0 0
10.0.0.3:/clients/10.0.1.1/var /var nfs rw,hard,intr,nolock 0 0
10.0.0.3:/clients/10.0.1.1/tmp /tmp nfs rw,hard,intr,nolock 0 0
10.0.0.3:/home /home nfs rw,hard,intr,nolock 0 0
Проверка NFS:
mount 127.0.0.1:/clients/10.0.1.1/root /mnt
/clients/shared/root/etc/init.d/netboot-dirs - скрпит монтирование разделов по
NFS загрузке для клиента:
#!/bin/sh
IP=`ifconfig eth0 | grep inet | sed 's/.*inet //;s/ netmask.*//'`
/bin/mount 10.0.0.3:/clients/$IP/var /var
/bin/mount 10.0.0.3:/clients/$IP/tmp /tmp
etc/init.d/netboot-dirs создание /var и /tmp разделов в ОЗУ для клиента:
#!/bin/sh
# File: etc/init.d/netboot-dirs
# Initialize a 1MB /var
/sbin/mke2fs -q /dev/ram12 1024
/bin/mount /dev/ram12 /var
/bin/chown 0:0 /var
/bin/chmod 755 /var
# Create some needed dirs
cd /var
/bin/mkdir -p --mode=755 run lib log/news spool/cron/crontabs
/bin/mkdir -p --mode=1777 tmp lock
# Initialize a 4MB /tmp
# -N option tunes this for small files
/sbin/mke2fs -q -N 2048 /dev/ram11 4096
/bin/mount /dev/ram11 /tmp
/bin/chown 0:0 /tmp
/bin/chmod 1777 /tmp
|
| |
|
|
|
Формирование списка имен RPM пакетов и зависимостей в Linux (доп. ссылка 1) |
Автор: uldus
[комментарии]
|
| | Формирование списка названий пакетов (не полных имен):
rpm -q -a --queryformat '%{NAME}\n'
Как после установки группы пакетов через "rpm -i --nodeps", проверить каких
зависимостей не хватает:
rpm -q -a --queryformat '%{NAME}\n'|sort|uniq > list_inst.txt
cat list_inst.txt| xargs -l1 rpm -q -R |grep -E "[<=>]"| cut -d ' ' -f1| cut -d '(' -f1| sort| uniq > list_req.txt
diff list_inst.txt list_req.txt| grep '>' > missing.txt
|
| |
|
|
|
Установка Domino R 6.5 на Linux |
Автор: Gennadi Kalaschnikow
[комментарии]
|
| | Для инсталляци Domino R6.5 необходимо в файле .bashrc, который находиться в
директории юзера "notes" сделать такую запись:
export LD_ASSUME_KERNEL = 2.2.5
|
| |
|
|
|
Подсказка по использованию APT |
[комментарии]
|
| | apt-get update - обновление локального кэша пакетов;
apt-cache search маска - поиск нужного пакета;
apt-cache show пакет - просмотр информации о пакете;
apt-get install пакет - установка пакета;
apt-get remove пакет - удаление пакета;
apt-get update; apt-get upgrade - полное обновление системы.
|
| |
|
|
|
Как, после сборки ядра Linux, инициализировать initrd (ядро падает при монтировании root раздела) (доп. ссылка 1) |
Автор: as
[комментарии]
|
| | initrd - RAM-диск, инициализируемый загрузчиком, требуется для подключения
модулей ядра, необходимых
на этапе до монтирования root-раздела, (например, до монтирования нужно
подгрузить - ext2/ext3/scsi модули).
1) man initrd - все изумительно описано;
2) после сборки ядра создаем новый initrd:
mkinitrd /boot/initrd-2.4.21 2.4.21;
3) в /etc/lilo.conf:
initrd=/boot/initrd-2.4.21
В mkinitrd сам initrd можно назвать как угодно, но второй параметр обязательно версия ядра.
|
| |
|
|
|
Как в RedHat управлять из командной строки runlevel (init.d) скриптами |
[комментарии]
|
| | Перезапуск сервисов:
service имя start
service имя stop
service имя restart
Добавление или удаление сервисов (удобнее использовать утилиту ntsysv, sysvconfig или rcconf):
chkconfig --list
chkconfig --add имя
chkconfig --del имя
chkconfig [--level уровень] имя <on|off|reset>
|
| |
|
|
|
Подсказка по опциям RPM. |
[обсудить]
|
| | Установка пакетов: rpm -i <пакеты>
Деинсталляция пакета: rpm -e <пакеты>
Обновление или установка пакетов: rpm -U <пакеты>
Только обновление пакетов если они ранее установлены: rpm -F <пакеты>
Полезно: --force -установить несмотря ни на что, --nodeps - без проверки
зависимости, -vh - приятный вывод, --test - проверка.
Информация о пакете: rpm -q <пакет>
Список всех пакетов в системе: rpm -q -a
Узнать какому пакету принадлежит файл: rpm -q -f <файл>
Полезно: -i - более полное описание пакета, -R - список зависимостей пакета, -l
- список файлов в пакете,
-c - список конфигов в пакете, -d - список документации.
Установка из исходников: rpm --recompile <srpm> , собрать бинарный пакет: rpm --rebuild <srpm>.
Перестроить базу: rpm --rebuilddb
|
| |
|
|
|
Как вручную распаковать rpm файл |
[комментарии]
|
| | rpm2cpio file.rpm | cpio -idmuv --no-absolute-filenames
|
| |
|
|
|
|
|
Первоначальная настройка VPS сервера на базе CentOS 8 |
Автор: KoD
[комментарии]
|
| | В наши дни многие информационные сервисы работают на
виртуальных машинах. На рынке появляется огромное количество поставщиков услуг
виртуализации, у которых можно получить VPS по вполне вменяемым ценам.
В этой статье я хотел бы поделиться своим вариантом первоначальной настройки
виртуалки на базе CentOS 8 и принять рекомендации по её улучшению.
Предполагается, что VPS предназначена для разработки/тестирования/презентации
WEB-приложения в общем случае, т.е. не ориентируясь на какие-либо специфические
особенности и среды программирования.
Первые шаги
Во-первых, после установки необходимо создать непривилегированного пользователя:
# groupadd user
# useradd -m -d /home/user -s /bin/bash -g user -G wheel user
# passwd user
Сгенерировать пару криптографических ключей (на клиентской машине) следующей командой:
client$ ssh-keygen -t ed25519
И перенести открытый ключ на сервер:
client$ ssh-copy-id user@example.ru
Затем задать более безопасные настройки для демона sshd (на сервере).
Под X.X.X.X понимается IP-адрес клиента, с которого будет происходить соединение на VPS.
# sed -i 's/PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config
# sed -i 's/PasswordAuthentication yes/PasswordAuthentication no/' /etc/ssh/sshd_config
# echo "AllowUsers user@X.X.X.X user@X.X.X.*" >> /etc/ssh/sshd_config
# systemctl restart sshd.service
После выхода из под учётной записи администратора, можно соединиться с сервером
по SSH и продолжить дальнейшую настройку.
Далее следует файрволл. Его настраиваем так, чтобы на 22 порт SSH могли
подключаться пользователи из авторизованной подсети, а остальные соединения отбрасывались:
$ sudo firewall-cmd --zone=internal --add-source=X.X.X.X/32 --add-source=X.X.X.0/24
$ sudo firewall-cmd --zone=internal --add-service=ssh
$ sudo firewall-cmd --zone=public --remove-service=ssh
$ sudo firewall-cmd --zone=public --add-service=http --add-service=https
$ sudo firewall-cmd --get-active-zones
internal
sources: X.X.X.X/32 X.X.X.0/24
public
interfaces: ens3
$ sudo firewall-cmd --runtime-to-permanent
$ sudo firewall-cmd --reload
Опять же, под X.X.X.X понимается IP-адрес клиента, с которого будет происходить соединение на VPS.
Установка программного обеспечения
Прежде всего следует обновить систему до актуального состояния и перезагрузиться:
$ sudo dnf upgrade --refresh
$ sudo reboot
Затем установим необходимое для разработки программы:
$ sudo dnf groupinstall "Development tools"
$ sudo dnf install clang
Clang устанавливаю, как дополнение к GCC для кроссплатформенной компиляции разработок.
Установка и настройка СУБД
Из основного репозитория качаем клиент, сервер и заголовки MariaDB.
Запускаем, проверяем, и настраиваем СУБД
$ sudo dnf install mariadb mariadb-server mariadb-devel
$ sudo systemctl start mariadb
$ sudo systemctl status mariadb
Active: active (running)
$ sudo systemctl enable mariadb
Created symlink /etc/systemd/system/mysql.service > /usr/lib/systemd/system/mariadb.service.
Created symlink /etc/systemd/system/mysqld.service > /usr/lib/systemd/system/mariadb.service.
Created symlink /etc/systemd/system/multi-user.target.wants/mariadb.service > /usr/lib/systemd/system/mariadb.service.
Скрипт mysql_secure_installation устанавливает пароль для root MariaDB
и выключает небезопасные настройки. Далее можно создать БД и пользователей.
$ sudo mysql_secure_installation
$ mysql -u root -p
mysql> CREATE DATABASE `mydb`;
mysql> GRANT USAGE ON *.* TO 'user'@localhost IDENTIFIED BY 'mypassword';
mysql> GRANT ALL privileges ON `mydb`.* TO 'user'@localhost;
mysql> FLUSH PRIVILEGES;
mysql> SHOW GRANTS FOR 'user'@localhost;
Первоначальная настройка MariaDB завершена.
Установка и настройка HTTPD apache2
Ниже следует установка сервера httpd.
В качестве менеджера SSL-сертификатов будем использовать certbot из репозитория EPEL:
$ sudo dnf install httpd
$ sudo dnf install epel-release
$ sudo dnf install certbot python3-certbot-apache mod_ssl
Добавляем виртуальный хост в конфиг сервера. Предполагается, что DNS имя сервера уже
зарегистрировано и делегировано, создана A-запись на IP VPS.
$ vi /etc/httpd/conf.d/vhosts.conf
<VirtualHost *:80>
ServerAdmin webmaster@example.ru
ServerName example.ru
ServerAlias www.example.ru
DocumentRoot /var/www/html/example.ru/
<Directory "/var/www/cgi-bin">
AllowOverride None
Options +ExecCGI
AddHandler cgi-script .cgi .sh
Require all granted
</Directory>
</VirtualHost>
Эта конфигурация так же включает выполнение CGI-скриптов на стороне сервера, так что
можно приступать к разработке WEB-приложений после перезагрузки сервиса:
$ sudo systemctl enable httpd
$ sudo systemctl start httpd
Не забываем получить сертификаты в центре сертификации Let`s Encrypt:
$ sudo certbot -d example.ru -d www.example.ru
Вышеизложенный порядок действий не обязательно каждый раз делать вручную.
Можно написать и отладить простой shell-скрипт, который проделает все
операции в автоматическом режиме и первоначальная настройка VPS сервера займёт
незначительное время.
|
| |
|
|
|
Связывание повторяемых сборок GNU Guix с архивом исходных текстов Software Heritage (доп. ссылка 1) |
Автор: znavko
[комментарии]
|
| | Перевод статьи Людвика Курте от 29.03.2019, опубликованной в блоге Guix.
В статье рассказано как в дистрибутиве GNU Guix связать повторяемые сборки,
позволяющие убедиться в тождественности бинарных файлов эталонным исходным
текстам, с загрузкой исходных текстов из архива кода Software Heritage.
Software Heritage ставит перед собой задачу создания полного архива всех
доступных в Сети исходных текстов. Код загружается из разных источников
(GitHub, репозитории Debian, коллекции GNU и т.п.) с автоматическим переносом
информации об изменениях, формируя таким образом историю развития кода разных
проектов (можно посмотреть каким код был в разное время). В Guix можно
использовать Software Heritage для получения кода, если репозиторий из которого
собран пакет перестал существовать. В контексте повторяемых сборок пользователь
может загрузить из Software Heritage состояние кода проекта, соответствующее
имеющемуся бинарному пакету, и проверить, что бинарные файлы собраны именно из
этого кода без добавления скрытых изменений.
GNU Guix может использоваться как пакетный менеджер, чтобы устанавливать и
обновлять пакеты ПО. Также Guix может выступать менеджером окружения, создавать
контейнеры или виртуальные машины, управлять операционной системой на компьютере.
Ключевым отличием GNU Guix, выделяющим его среди других подобных инструментов,
является воспроизводимость. Для пользователя это означает следующее.
Пользователь задаёт в конфигурационном файле программное окружение и запускает
его установку. Пользователи могут делиться конфигурацией окружения с другими,
чтобы воспроизвести или адаптировать его для своих нужд. Эта особенность играет
ключевую роль для разработки программного обеспечения, так как чтобы получить
результат внедрения программы в программное окружение, вначале нужно
воспроизвести программное окружение. Этой темой мы занимаемся в рамках проекта
Guix-HPC. На программном уровне это означает, что Guix, как и другие проекты сообщества
Reproducible Builds, производит сверку результатов
воспроизводимой сборки,
бит за битом.
В вопросе воспроизводимости Guix ушёл вперёд. Пользователю Guix, можно сказать,
доступна машина времени, позволяющая запустить окружение с предыдущими версиями
пакетов. Но оставался один нюанс, который не позволял использовать эту
технологию на практике - стабильный архив исходного кода. Тогда и появился
Software Heritage (SWH).
Когда исходный код исчезает
Guix содержит тысячи описаний пакетов. Каждое описание пакета задаёт URL
исходного кода пакета и хеш, зависимости и процедуру сборки. В большинстве
случаев исходный код пакета - это архив, извлекаемый с сайта, но всё чаще
исходный код ссылается на конкретную ревизию, размещённую в системе управления версиями.
Что происходит, если ссылка на исходный код становится нерабочей? Все усилия,
обеспечивающие воспроизводимость, не работают, когда исчезает исходный код.
Исходный код, действительно, исчезает, более того, он может быть изменён в
источнике. В GNU мы предоставляем стабильный хостинг, где размещаются релизы
почти навсегда, без изменений (с незначительными редкими изменениями). Но
большое количество свободного программного обеспечения в Интернете размещается
на личных сайтах, которые имеют непродолжительное время жизни, или на
коммерческих хостингах, которые работают и закрываются.
По умолчанию Guix ищет исходный код по хешу в кэше наших серверов сборки. Бесплатно
механизм подстановок расширяет функционал сборки, включая скачивание. Однако
ограничения не позволяют нашим серверам сборки хранить весь исходный код всех
пакетов долгое время. Так что вполне вероятно, что пользователь не сможет
пересобрать пакет через месяцы или годы, просто потому что исходный код
переместился или исчез.
Работа с архивом
Совершенно ясно, что для обеспечения воспроизводимых сборок должен быть
постоянный доступ к исходному коду. Архив Software Heritage позволит нам
воспроизводить программное окружение через годы вопреки непостоянству
хостингов. Миссия Software Heritage - сохранить весь когда либо опубликованный
исходный код, включая историю версий. Этот архив уже периодически поглощает
релизы ПО с серверов GNU, репозитории с GitHub, пакеты PyPI и многое другое.
Мы предусмотрели политику, по которой Guix будет обращаться к архиву Software
Heritage при невозможности скачать исходный код из источника. Описания пакетов
при этом не нуждаются в изменениях: они всё ещё указывают на первоначальный
URL, но механизм скачки прозрачно работает с Software Heritage, когда необходимо.
В Guix есть два типа скачивания исходных кодов: скачивание архива и
осуществление контроля изменений версий. В первом случае взаимодействие с
Software Heritage очень простое: Guix выполняет поиск по хешу SHA256, который
ему известен, используя интерфейс архива.
Выборка истории изменения версий более сложная. В этом случае вначале
необходимо определить идентификатор коммита, чтобы обратиться к нужной
ревизии на Software Heritage. Код ревизии затем будет доступен через API хранилища.
Хранилище (Vault API) позволяет получить архив, соответствующий определённой
ревизии пакета. Однако ясно, что не все ревизии доступны в качестве архивов,
так что хранилище имеет интерфейс, через который можно запросить подготовку
нужной ревизии. Подготовка асинхронная и может занимать некоторое время. В
настоящее время, если ревизия недоступна, механизм скачивания Guix запрашивает
и ждёт его готовности. Процесс может занять некоторое время, но в итоге
завершается успешно.
Вот так! С этого момента мы собрали цепочку. Благодаря Software Heritage,
который предоставляет стабильный архив, воспроизводимая сборка Guix работает.
Этот код был внедрён в ноябре 2018, создав первый свободный дистрибутив,
основанный на стабильном архиве.
Новые вызовы
Мы достигли цели и сделали её осязаемой, но нам известно о недостатках.
Во-первых, даже если программное обеспечение, которое описано в наших пакетах,
доступно в виде архивов, Software Heritage содержит относительно немногие из
них. Software Heritage поглощает архивы, особенно те, которые найдены на
серверах GNU, но он нацелен в первую очередь на сохранение репозиториев систем
управления версиями, а не архивов релизов.
Нам всё ещё неясно, что делать с обычными старыми архивами. С одной стороны,
они есть и не могут быть проигнорированы. Более того, многие содержат
артефакты, которых нет в системе управления версими, например, скрипты
configure, и довольно часто они сопровождаются криптографическими подписями
разработчиков, которые позволяют получателям подтвердить код - важная
информация, которая часто отсутствует в системе управления версиями. С другой
стороны, теги систем управления версиями всё чаще становятся механизмом
распространения релизов программ. Вполне вероятно, что теги станут главным
механизмом распространения ПО в ближайшем будущем.
Теги систем управления версиями тоже не идеальны, так как они изменчивы и
привязаны к репозиторию. С другой стороны, идентификаторы коммита Git
совершенно точно указывают на нужную версию пакета, так как они относятся к
пакету и не зависят от репозитория. Но наши описания пакетов часто ссылаются на
теги, а не коммиты, так как это даёт понять, что пакет ссылается на актуальный
релиз, а не обычную ревизию (такой вот треугольник Zooko).
Есть и другая проблема, которая происходит из того, что Guix вычисляет хеш
версии пакета иначе, чем Software Heritage. Оба вычисляют хеш по файлам
директории, но они упорядочивают файлы в разных последовательностях (SWH
сериализует директории как дерево Git, а Guix использует "нормализованный
архив", или Nars, формат, который использует демон сборки, наследованный от
Nix). Это не позволяет Guix искать ревизии по хешу содержимого. Решением
вероятно будет добавление в Guix поддержки такого метода, как в Software
Heritage, ну, или Software Heritage добавит метод Guix.
Ожидание завершения подготовки архива также может вызывать проблемы. Команда
Software Heritage внедряет возможность
автоматического добавления тегов в систему управления версиями. Таким
образом, нужные ревизии почти всегда будут доступны в хранилище.
Также мы не гарантируем, что программы, поставляемые Guix, доступны в качестве
архива. Мы запросили Software Heritage периодически скачивать исходный код
программного обеспечения, поставляемого Guix.
Движемся далее
Работая над поддержкой Software Heritage, мы включили в Guix модуль Guile,
реализующий HTTP-интерфейс Software Heritage. Вот некоторые вещи, которые он умеет:
(use-modules (guix swh))
;; Check whether SWH has ever crawled our repository.
(define o (lookup-origin "https://git.savannah.gnu.org/git/guix.git"))
=> #{{origin> id: 86312956 ...>
;; It did! When was its last visit?
(define last-visit
(first (origin-visits o)))
(date->string (visit-date last-visit))
=> "Fri Mar 29 10:07:45Z 2019"
;; Does it have our "v0.15.0" Git tag?
(lookup-origin-revision "https://git.savannah.gnu.org/git/guix.git" "v0.15.0")
=> #{{revision> id: "359fdda40f754bbf1b5dc261e7427b75463b59be" ...>
Guix также является библиотекой Guile, так что используя guix и swh, мы получаем интересные вещи:
(use-modules (guix) (guix swh)
(gnu packages base)
(gnu packages golang))
;; This is our GNU Coreutils package.
coreutils
=> #{package coreutils@8.30 gnu/packages/base.scm:342 1c67b40>
;; Does SWH have its tarball?
(lookup-content (origin-sha256 (package-source coreutils))
"sha256")
=> #{{content> checksums: (("sha1" ...)) data-url: ...>
;; Our package for HashiCorp's Configuration Language (HCL) is
;; built from a Git commit.
(define commit
(git-reference-commit
(origin-uri (package-source go-github-com-hashicorp-hcl))))
;; Is this particular commit available in the archive?
(lookup-revision commit)
=> #{{revision> id: "23c074d0eceb2b8a5bfdbb271ab780cde70f05a8" ...>
В настоящее время мы используем этот инструментарий, но конечно, это не всё,
что мы можем. Например, можно выяснить, какие пакеты Guix добавлены. Также
можно запросить архив исходного кода каждого пакета с помощью интерфейса
'save code', но однако есть ограничения по скорости.
Подведём итоги
Поддержка Software Heritage в Guix даёт для воспроизводимого развёртывания
стабильный архив исходного кода и полное резервирование ранних версий. Впервые
мы получили пакетный менеджер, который может пересобирать предыдущие версии
программ. Это имеет практическую выгоду в области воспроизводимости: мы можем
создавать воспроизводимое программное окружение - основу воспроизводимых
экспериментов в области разработки ПО.
Собственно, мы можем предоставить инструменты загрузки программного обеспечения
с доступом к ранним версиям. Да и сам Guix резервируется, так что мы выходим на
метауровень, когда мы можем ссылаться на ревизии Guix, ссылаясь на ревизии
пакетов, предоставляемые им. Есть барьеры, которые необходимо преодолеть, но
результат уже обозрим.
|
| |
|
|
|
Использование slackpkg для chroot |
Автор: АнкхС
[комментарии]
|
| | Можно назначить переменную окружения
export ROOT=/mychroot
После этого slackpkg начинает обработку корня относительно каталога /mychroot и выполнив, например
slackpkg update
slackpkg install a
Все пакеты и пакетная база попадут в иерархию, относительно каталога,
определённого в переменной окружения ROOT.
|
| |
|
|
|
Пересборка пакетов для Ubuntu (Debian) (доп. ссылка 1) |
Автор: Davidov
[комментарии]
|
| | Думаю, практически все понимают преимущества пакетных менеджеров над установкой при помощи
./configure && make && make install.
На примере недавно появившегося патча для Pidgin я хочу показать,
как легко пересобирать пакеты в deb-based дистрибутивах.
Подготовка.
Нам понадобятся следующие пакты: devscripts build-essential fakeroot
sudo apt-get install devscripts build-essential fakeroot
Скачиваем исходники.
Для этого должны быть подключены соответствующие репозитории.
Нам нужен libpurple0, т.к. патч относится к этой библиотеке.
На самом же деле libpurple, pidgin и pidgin-data имеют общий исходник, там что
мы можем написать как
apt-get source libpurple0
так и
apt-get source pidgin
Обратите внимание, что apt-get source надо делать не из под sudo.
Исходники скачиваются в текущую директорию.
Патчим.
wget http://launchpadlibrarian.net/15741199/pidgin-2.4.2-icq.patch
cd pidgin-2.4.1
patch -p0 < ../pidgin-2.4.2-icq.patch
Устанавливаем зависимости, необходимые для сборки:
sudo apt-get build-dep libpurple0
Пересобираем пакет (из той же директории)
debuild -us -uc
Получившийся пакет устанавливаем:
cd ..
sudo dpkg -i libpurple0_2.4.1-1ubuntu2_amd64.deb
Если у вас i386-дистрибутив, то пакет будет называться libpurple0_2.4.1-1ubuntu2_i386.deb.
|
| |
|
|
|
Установка ATI Catalyst 8.5 в Ubuntu 8.04 (доп. ссылка 1) |
Автор: Pronix
[комментарии]
|
| | 1. Скачать ati-driver-installer-8-5-x86.x86_64.run
2. В консоли выполнить для синхронизации списка пакетов, доступных в репозиториях:
sudo apt-get update
Затем, установить пакеты, необходимые для сборки модуля ядра из исходных
текстов и создания deb пакета:
sudo apt-get install build-essential fakeroot dh-make debhelper debconf libstdc++5 dkms linux-headers-$(uname -r)
3. В консоли запускаем инсталлятор драйвера в режиме создания пакетов:
sudo sh ati-driver-installer-8-5-x86.x86_64.run --buildpkg Ubuntu/8.04
4. Теперь нужно занести в черный список драйвер fglrx из репозитория Ubuntu, выполняем
sudo gedit /etc/default/linux-restricted-modules-common
и в строке "DISABLED_MODULES" добавляем "fglrx"
получаем строку:
DISABLED_MODULES="fglrx"
сохраняем файл
5. далее в консоли устанавливаем подготовленные пакеты с драйвером:
sudo dpkg -i xorg-driver-fglrx_8.493*.deb fglrx-kernel-source_8.493*.deb fglrx-amdcccle_8.493*.deb
6. Перезагружаем X сервер.
7. проверяем:
$ fglrxinfo
display: :0.0 screen: 0
OpenGL vendor string: ATI Technologies Inc.
OpenGL renderer string: Radeon X1900 Series
OpenGL version string: 2.1.7537 Release
PS: все вышесказанное проверялось на i386 конфигурации с видеокартой X1900,
для amd64 возможны небольшие отличая в установке.
Оригинал: http://pronix.isgreat.org/news.php?item.86.5
|
| |
|
|
|



 Как вариант предложено дополнительно использовать
Как вариант предложено дополнительно использовать 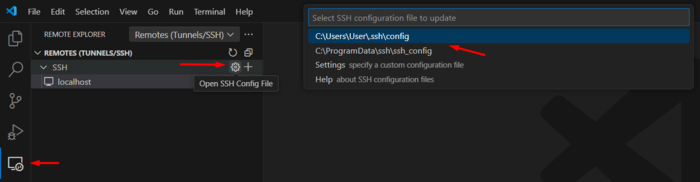 В окне соединений плагина Remote Explorer на строке соединения нажимаем Connect
in current Window. Вводим пароль в окне поиска, когда система его запросит. В
случае успеха откроется новое окно VS Code с индикатором подключения в правом
нижнем углу (>{SSH: localhost). Если панель с командной строкой не открыта
нажимаем Ctrl+J и видим приглашение консоли.
Установка Asterisk в отладочном режиме с минимальной конфигурацией.
В консоли нужно убедится, что Интернет доступен из ВМ:
ping 1.1.1.1
Качаем свежую версию исходного кода Asterisk с сайта компании.
wget
В окне соединений плагина Remote Explorer на строке соединения нажимаем Connect
in current Window. Вводим пароль в окне поиска, когда система его запросит. В
случае успеха откроется новое окно VS Code с индикатором подключения в правом
нижнем углу (>{SSH: localhost). Если панель с командной строкой не открыта
нажимаем Ctrl+J и видим приглашение консоли.
Установка Asterisk в отладочном режиме с минимальной конфигурацией.
В консоли нужно убедится, что Интернет доступен из ВМ:
ping 1.1.1.1
Качаем свежую версию исходного кода Asterisk с сайта компании.
wget 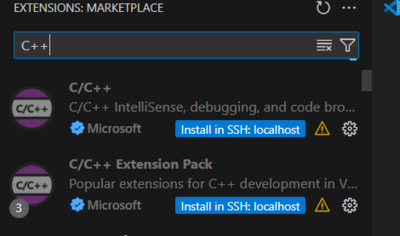
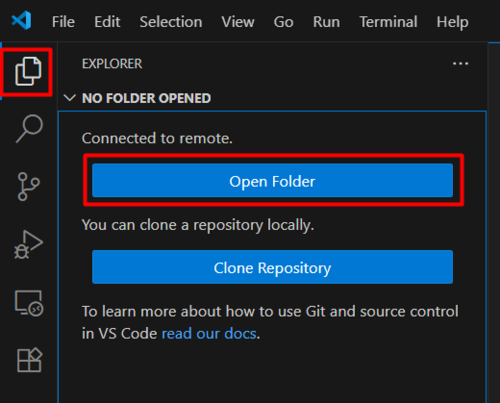 В меню VS Code выбираем пункт Run - Add Configuration - CMake Debug и в
открывшемся файле .vscode/launch.json удаляем все и добавляем 2 новых конфигурации:
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug Asterisk (Local Launch)",
"type": "cppdbg",
"request": "launch",
"program": "/usr/sbin/asterisk",
"args": ["-f", "-vvvgc"], // Консольный режим с максимальным логгированием
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"setupCommands": [
{
"description": "Enable pretty-printing",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
},
{
"name": "Debug Asterisk (Local Attach)",
"type": "cppdbg",
"request": "attach",
"program": "/usr/sbin/asterisk",
"processId": "${command:pickProcess}",
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"miDebuggerArgs": "--interpreter=mi",
"setupCommands": [
{
"description": "Enable pretty-printing",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "Set debug mode",
"text": "handle SIG33 pass nostop noprint"
}
],
}
]
}
Это конфигурации с локальным запуском и с присоединением к уже запущенному процессу.
Сохраняем .vscode/launch.json (Ctrl+s).
В окне дерева каталогов Asterisk в VS Code Explorer (Ctrl+Shift+E) открываем файл
main/asterisk.c
Мотаем на строчку 3613 и видим там функцию int main(int argc, char *argv[]).
Устанавливаем точку остановки, нажав на красный кружок левее от номера строки
(появится при наведении указателя мыши).
В меню VS Code выбираем пункт Run - Add Configuration - CMake Debug и в
открывшемся файле .vscode/launch.json удаляем все и добавляем 2 новых конфигурации:
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug Asterisk (Local Launch)",
"type": "cppdbg",
"request": "launch",
"program": "/usr/sbin/asterisk",
"args": ["-f", "-vvvgc"], // Консольный режим с максимальным логгированием
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"setupCommands": [
{
"description": "Enable pretty-printing",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
},
{
"name": "Debug Asterisk (Local Attach)",
"type": "cppdbg",
"request": "attach",
"program": "/usr/sbin/asterisk",
"processId": "${command:pickProcess}",
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"miDebuggerArgs": "--interpreter=mi",
"setupCommands": [
{
"description": "Enable pretty-printing",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "Set debug mode",
"text": "handle SIG33 pass nostop noprint"
}
],
}
]
}
Это конфигурации с локальным запуском и с присоединением к уже запущенному процессу.
Сохраняем .vscode/launch.json (Ctrl+s).
В окне дерева каталогов Asterisk в VS Code Explorer (Ctrl+Shift+E) открываем файл
main/asterisk.c
Мотаем на строчку 3613 и видим там функцию int main(int argc, char *argv[]).
Устанавливаем точку остановки, нажав на красный кружок левее от номера строки
(появится при наведении указателя мыши).
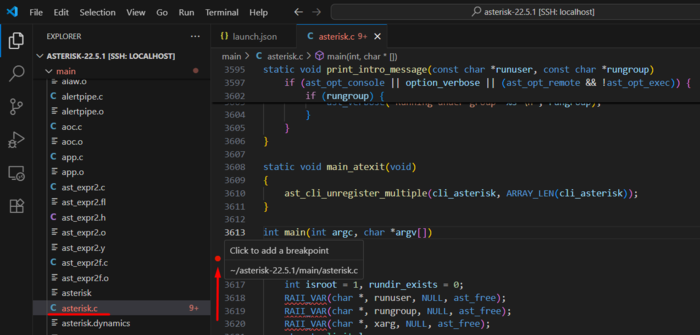 Запускаем процесс отладки нажав на клавиатуре F5 или через меню Run - Debug.
Процесс должен остановиться на точке входа и далее контролируем исполнение
Выполнить строку без захода внутрь функции F10
Выполнить строку с заходом внутрь функции F11
Запускаем процесс отладки нажав на клавиатуре F5 или через меню Run - Debug.
Процесс должен остановиться на точке входа и далее контролируем исполнение
Выполнить строку без захода внутрь функции F10
Выполнить строку с заходом внутрь функции F11
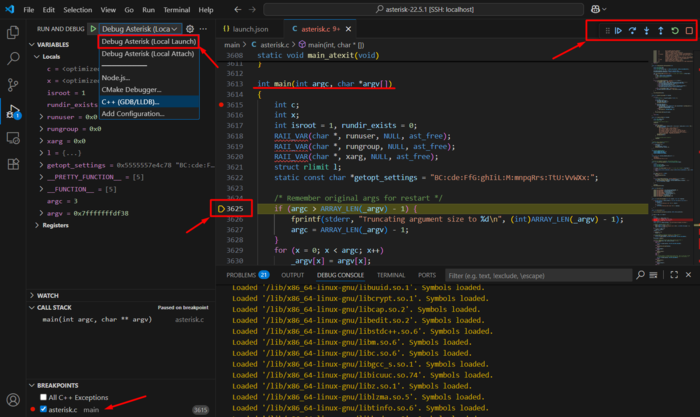 В меню слева выбираем окно Run and Debug (Ctrl+Shift+D), видим локальные
переменные, текущие потоки и точки останова.
Отладка чтения файла конфигурации PBX extensions.conf:
Ранее мы скомпилировали необходимый модуль pbx_config.so и он должен быть в /usr/lib/asterisk/modules/
ls /usr/lib/asterisk/modules/
Так же в /etc/asterisk/modules.conf должна находится следующая конфигурация:
[modules]
autoload = yes
Открываем файл pbx/pbx_config.c на строке 2151 и ставим breakpoint на функции
static int load_module(void)
Запускаем отладку. Если остановились на раннее установленной точке в main() то
просто нажимаем F5 и ждём останова в pbx/pbx_config.c:2151
Далее, построчно исполняем программу с помощью F10 - F11 и смотрим, что
происходит с внутренним состоянием процесса.
Заключение.
Далее, можно докомпилировать интересующие модули из того же дерева каталогов через:
make menuselect
make
sudo make install
Можете посмореть в сторону проекта
В меню слева выбираем окно Run and Debug (Ctrl+Shift+D), видим локальные
переменные, текущие потоки и точки останова.
Отладка чтения файла конфигурации PBX extensions.conf:
Ранее мы скомпилировали необходимый модуль pbx_config.so и он должен быть в /usr/lib/asterisk/modules/
ls /usr/lib/asterisk/modules/
Так же в /etc/asterisk/modules.conf должна находится следующая конфигурация:
[modules]
autoload = yes
Открываем файл pbx/pbx_config.c на строке 2151 и ставим breakpoint на функции
static int load_module(void)
Запускаем отладку. Если остановились на раннее установленной точке в main() то
просто нажимаем F5 и ждём останова в pbx/pbx_config.c:2151
Далее, построчно исполняем программу с помощью F10 - F11 и смотрим, что
происходит с внутренним состоянием процесса.
Заключение.
Далее, можно докомпилировать интересующие модули из того же дерева каталогов через:
make menuselect
make
sudo make install
Можете посмореть в сторону проекта  Связь переменных sysctl с различными стадиями обработки сетевых потоков в Linux
Входящие пакеты (Ingress)
1. Пакеты прибывают в NIC (сетевой адаптер)
2. NIC проверяет `MAC` (если не включён promiscuous-режим) и `FCS (Frame check
sequence)` и принимает решение отбросить пакет или продолжить обработку.
3. NIC используя DMA (
Связь переменных sysctl с различными стадиями обработки сетевых потоков в Linux
Входящие пакеты (Ingress)
1. Пакеты прибывают в NIC (сетевой адаптер)
2. NIC проверяет `MAC` (если не включён promiscuous-режим) и `FCS (Frame check
sequence)` и принимает решение отбросить пакет или продолжить обработку.
3. NIC используя DMA (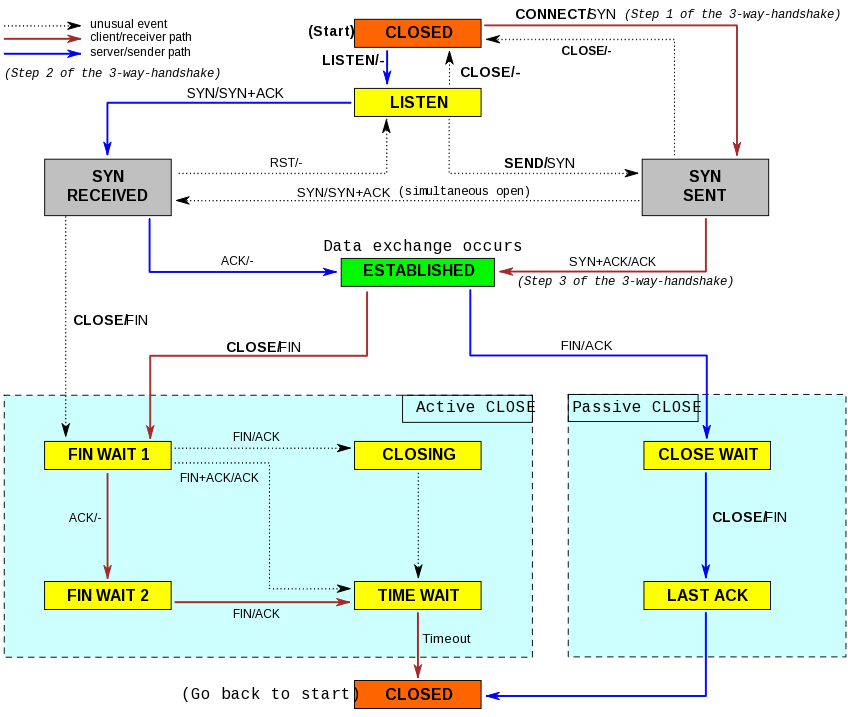 Источник:
Источник:  Для настройки параметров подключения предоставляется консольный и web-интерфейс
(задаётся пароль подключения к внешней беспроводной сети, пароль для
подключения к ретранслятору и выбор режима работы). Поддерживаются функции
межсетевого экрана, позволяющего ограничить доступ к IP-адресам, подсетям и
сетевым портам через простой ACL, а также ограничить пропускную способность
подключения клиента. Для IoT-устройств предусмотрена поддержка протокола MQTT.
Имеется поддержка режима мониторинга, позволяющего анализировать проходящий
через ретранслятор трафик в приложениях, поддерживающих формат pcap (например, wireshark).
Для прошивки достаточно подключить плату через последовательный порт или
переходник USB2Serial,
Для настройки параметров подключения предоставляется консольный и web-интерфейс
(задаётся пароль подключения к внешней беспроводной сети, пароль для
подключения к ретранслятору и выбор режима работы). Поддерживаются функции
межсетевого экрана, позволяющего ограничить доступ к IP-адресам, подсетям и
сетевым портам через простой ACL, а также ограничить пропускную способность
подключения клиента. Для IoT-устройств предусмотрена поддержка протокола MQTT.
Имеется поддержка режима мониторинга, позволяющего анализировать проходящий
через ретранслятор трафик в приложениях, поддерживающих формат pcap (например, wireshark).
Для прошивки достаточно подключить плату через последовательный порт или
переходник USB2Serial,  Зона покрытия без отражающего экрана:
Зона покрытия без отражающего экрана:
 Зона покрытия с отражающим экраном:
Зона покрытия с отражающим экраном:

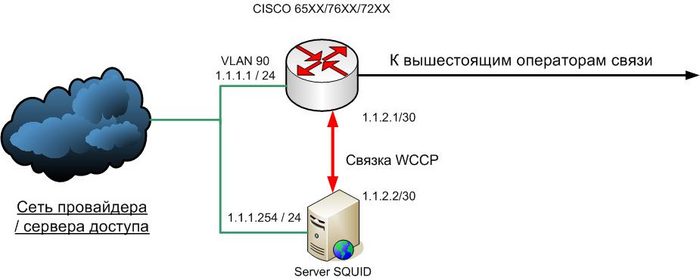 Трафик HTTP и HTTPS, выходящий из облака нашей сети (в примере VLAN90) через
наш бордер CISCO, мы будем сравнивать с ACL, содержащим IP-адреса, извлеченные
из списка Роскомнадзора. В случае совпадения, мы отправляем трафик по протоколу
WCCP (Web Cache Communication Protocol) на сервер(а) SQUID. Данная схема
позволит нам избежать анализа всего трафика и анализировать только тот, который
идет на заявленные IP, что не может не сказаться положительно на общей
производительности системы.
Из минусов данной связки следует, что допустим если внесенный в реестр ресурс с
IP=3.3.3.3, доменом=bad.xxx и URL=
Трафик HTTP и HTTPS, выходящий из облака нашей сети (в примере VLAN90) через
наш бордер CISCO, мы будем сравнивать с ACL, содержащим IP-адреса, извлеченные
из списка Роскомнадзора. В случае совпадения, мы отправляем трафик по протоколу
WCCP (Web Cache Communication Protocol) на сервер(а) SQUID. Данная схема
позволит нам избежать анализа всего трафика и анализировать только тот, который
идет на заявленные IP, что не может не сказаться положительно на общей
производительности системы.
Из минусов данной связки следует, что допустим если внесенный в реестр ресурс с
IP=3.3.3.3, доменом=bad.xxx и URL= Быстрые и неправильные решения
Данные проблемы можно попытаться решить наскоком, и что может ложно успокоить,
"всё будет работать". Поменяв маршрут по умолчанию на белых хостах на
собственный маршрутизатор создастся видимость, что всё починилось:
маршрутизация до филиалов и серых сетей появилась, а межсетевой экран даже
сможет срабатывать на выход. Но кому более всего нужен межсетевой экран на
выход? Вот то-то же. Да и с маршрутизацией не всё на самом деле в порядке.
На каждый посланный вами из белой сети в Интернет пакет, вы будете получать
ICMP redirect, говорящий, что маршрутизатор вами установлен не тот:
PING branch.mydomain.ru (branch-IP): 56 data bytes
From GW-IP Redirect (change route)
84 bytes from branch-IP: icmp_seq=0 ttl=63 time=N ms
Windows машины, у которых по умолчанию применяется политика реагирования на
этот код, будут бесконечно добавлять в таблицу маршрутизации записи на каждый
хост в Интернете через маршрутизатор провайдера.
Хорошо, а давайте добавим все статические маршруты, а между провайдерским и
своим коммутатором поставим прозрачный файервол. Ну что ж, это решение будет
работать пока вам не надоест возиться с маршрутизацией и не возникнет мысль,
что может сделаем управляющий интерфейс прозрачного файервола в белой сети и он
и будет центральным маршрутизатором. Увы, как только вы это сделаете, всё
вернётся к проблеме, описанной ранее.
Правильное решение
Из предыдущей главы стало понятно, что нам нужно:
Быстрые и неправильные решения
Данные проблемы можно попытаться решить наскоком, и что может ложно успокоить,
"всё будет работать". Поменяв маршрут по умолчанию на белых хостах на
собственный маршрутизатор создастся видимость, что всё починилось:
маршрутизация до филиалов и серых сетей появилась, а межсетевой экран даже
сможет срабатывать на выход. Но кому более всего нужен межсетевой экран на
выход? Вот то-то же. Да и с маршрутизацией не всё на самом деле в порядке.
На каждый посланный вами из белой сети в Интернет пакет, вы будете получать
ICMP redirect, говорящий, что маршрутизатор вами установлен не тот:
PING branch.mydomain.ru (branch-IP): 56 data bytes
From GW-IP Redirect (change route)
84 bytes from branch-IP: icmp_seq=0 ttl=63 time=N ms
Windows машины, у которых по умолчанию применяется политика реагирования на
этот код, будут бесконечно добавлять в таблицу маршрутизации записи на каждый
хост в Интернете через маршрутизатор провайдера.
Хорошо, а давайте добавим все статические маршруты, а между провайдерским и
своим коммутатором поставим прозрачный файервол. Ну что ж, это решение будет
работать пока вам не надоест возиться с маршрутизацией и не возникнет мысль,
что может сделаем управляющий интерфейс прозрачного файервола в белой сети и он
и будет центральным маршрутизатором. Увы, как только вы это сделаете, всё
вернётся к проблеме, описанной ранее.
Правильное решение
Из предыдущей главы стало понятно, что нам нужно:


 Мы видим - сервер получил нужные параметры.
Теперь выполним команду:
# ./adc_install.sh -ad_install
Мы видим - сервер получил нужные параметры.
Теперь выполним команду:
# ./adc_install.sh -ad_install

 Зададим пароль администратору Samba AD... ну скажем --> "OpenSUSE15".
Зададим IP DNS --> 192.168.1.1
Зададим пароль администратору Samba AD... ну скажем --> "OpenSUSE15".
Зададим IP DNS --> 192.168.1.1

 Установка Samba AD+DDNS+DHCPD закончена.
Осталось только сделать "reboot" сервера, чтобы наши установки вступили в силу.
После старта проверим статус Samba AD, DNS и DHCP-Сервера.
Выполним команду:
# ./adc_install.sh -ad_restart
... и проверим статус сервера выполнив команду:
# ./adc_install.sh -ad_status
Установка Samba AD+DDNS+DHCPD закончена.
Осталось только сделать "reboot" сервера, чтобы наши установки вступили в силу.
После старта проверим статус Samba AD, DNS и DHCP-Сервера.
Выполним команду:
# ./adc_install.sh -ad_restart
... и проверим статус сервера выполнив команду:
# ./adc_install.sh -ad_status

 Сделаем тест системы.
И выполним команду:
# ./adc_install.sh -ad_test
Сделаем тест системы.
И выполним команду:
# ./adc_install.sh -ad_test

 Теперь можем создать пользователя домена... ну скажем --> Wasja Pupkin.
Выполним команду:
# ./adc_install.sh -uadd
Теперь можем создать пользователя домена... ну скажем --> Wasja Pupkin.
Выполним команду:
# ./adc_install.sh -uadd

 Wasja Pupkin получил login для машины Windows в домене DYHAP: --> w.pupkin
Так же netlogon скрипт: --> w.pupkin.bat
И email-адрес: --> w.pupkin@dyhap.net
Выполним команду:
# ./adc_install.sh -mail_test
А вот email-адреса "test_user@dyhap.net" как и пользователя домена "test_user" в системе нет.
Создадим пользователя домена --> test_user.
Wasja Pupkin получил login для машины Windows в домене DYHAP: --> w.pupkin
Так же netlogon скрипт: --> w.pupkin.bat
И email-адрес: --> w.pupkin@dyhap.net
Выполним команду:
# ./adc_install.sh -mail_test
А вот email-адреса "test_user@dyhap.net" как и пользователя домена "test_user" в системе нет.
Создадим пользователя домена --> test_user.

 Установка Samba Active Directory Domain Controller закончена.
Теперь приступим к установке почтового сервера.
Выполнив команду:
# ./adc_install.sh -mail_inst
мы установим:
1. service postfix
2. service dovecot
3. service amavis
4. service spamd
5. service clamd
6. service clamav-milter
7. service fail2ban
8. service freshclam
Для этого необходимо создать:
1. ssl-сертификаты
2. администратора почтового сервера... --> mailadmin
3. пароль администратору mailadmin .. ну скажем --> "OpenSUSE15"
Установка Samba Active Directory Domain Controller закончена.
Теперь приступим к установке почтового сервера.
Выполнив команду:
# ./adc_install.sh -mail_inst
мы установим:
1. service postfix
2. service dovecot
3. service amavis
4. service spamd
5. service clamd
6. service clamav-milter
7. service fail2ban
8. service freshclam
Для этого необходимо создать:
1. ssl-сертификаты
2. администратора почтового сервера... --> mailadmin
3. пароль администратору mailadmin .. ну скажем --> "OpenSUSE15"


 Установка почтового Сервера закончена.
Теперь можно добавить компьютер Windows по имени "win12" в домен Active Directory.
1. Стартуем компьютер в локальной сети
--> параметры сетевого адаптера получены от DHCP сервера
2. "test_user" в домене --> DYHAP\test_user
3. IP адрес win12.dyhap.net --> 192.168.3.50
4. DHCP-Сервер ввёл win12.dyhap.net в DNS
Установка почтового Сервера закончена.
Теперь можно добавить компьютер Windows по имени "win12" в домен Active Directory.
1. Стартуем компьютер в локальной сети
--> параметры сетевого адаптера получены от DHCP сервера
2. "test_user" в домене --> DYHAP\test_user
3. IP адрес win12.dyhap.net --> 192.168.3.50
4. DHCP-Сервер ввёл win12.dyhap.net в DNS

 Стандартный процесс --> администратор "win12" вводит его в домен.
Стандартный процесс --> администратор "win12" вводит его в домен.



 В окне авторизации test_user указывает свои учетные данные и получает права на
ввод в рабочей станции win12 в домен.
В окне авторизации test_user указывает свои учетные данные и получает права на
ввод в рабочей станции win12 в домен.

 Теперь test_user получил доступ к таким ресурсам в Active Directory,
как электронная почта, приложения и сеть.
При входе стартует скрипт "test_user.bat" и test_user получил доступ
к таким ресурсам "Users" и "public" в сети Active Directory
Теперь test_user получил доступ к таким ресурсам в Active Directory,
как электронная почта, приложения и сеть.
При входе стартует скрипт "test_user.bat" и test_user получил доступ
к таким ресурсам "Users" и "public" в сети Active Directory


 Домашний каталог test_user на сервере.
1. Перемещаемый профиль --> test_user.V6
2. Почтовый каталог --> Maildir
Домашний каталог test_user на сервере.
1. Перемещаемый профиль --> test_user.V6
2. Почтовый каталог --> Maildir

 Теперь протестируем работу почтового Сервера .
Выполним команду:
# ./adc_install.sh -mail_status
Теперь протестируем работу почтового Сервера .
Выполним команду:
# ./adc_install.sh -mail_status

 [[IMG /soft/adc/mail/[33.jpg]]
[[IMG /soft/adc/mail/[33.jpg]]
 ...всё работает
Стартуем на сервере почтовый клиент Thunderbird.
1. Cоздадим учетную запись почты пользователя --> "mailadmin"
2. "mailadmin" отправил письмо пользователю --> "gennadi@dyhap.net"
3. Сообщение об ошибке можно проигнорировать и повторить
4. Это информация о том, что ssl-сертификаты самодельные.
...всё работает
Стартуем на сервере почтовый клиент Thunderbird.
1. Cоздадим учетную запись почты пользователя --> "mailadmin"
2. "mailadmin" отправил письмо пользователю --> "gennadi@dyhap.net"
3. Сообщение об ошибке можно проигнорировать и повторить
4. Это информация о том, что ssl-сертификаты самодельные.






 Пользователь "gennadi" принимает письмо от "mailadmin" почтовым клиентом KMail openSUSE 15.5 .
Стартуем на сервере почтовый клиент Kmail.
1. Cоздадим учетную запись почты пользователя --> "gennadi"
4. И принимаем информацию о том, что ssl-сертификаты самодельные.
Пользователь "gennadi" принимает письмо от "mailadmin" почтовым клиентом KMail openSUSE 15.5 .
Стартуем на сервере почтовый клиент Kmail.
1. Cоздадим учетную запись почты пользователя --> "gennadi"
4. И принимаем информацию о том, что ssl-сертификаты самодельные.









 Пользователь "gennadi" получил письмо от "mailadmin" и отправляет ответ.
Пользователь "mailadmin" отправляет письмо с тест-вирусом:
X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*
--> на имя "gennadi". НО антивирус "clamd" заблокировал его.
Пользователь "gennadi" получил письмо от "mailadmin" и отправляет ответ.
Пользователь "mailadmin" отправляет письмо с тест-вирусом:
X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*
--> на имя "gennadi". НО антивирус "clamd" заблокировал его.


 Пользователь "gennadi" отправляет письмо с ANTI-SPAM-TEST:
XJS*C4JDBQADN1.NSBN3*2IDNEN*GTUBE-STANDARD-ANTI-UBE-TEST-EMAIL*C.34X
--> на имя "mailadmin". НО антиспам "amavis" отправляет его в карантин.
Пользователь "gennadi" отправляет письмо с ANTI-SPAM-TEST:
XJS*C4JDBQADN1.NSBN3*2IDNEN*GTUBE-STANDARD-ANTI-UBE-TEST-EMAIL*C.34X
--> на имя "mailadmin". НО антиспам "amavis" отправляет его в карантин.



 ANTI-SPAM и ANTIVIRUS работают
Cоздадим учетную запись почты пользователя "test_user" на компьютере "win12"
ANTI-SPAM и ANTIVIRUS работают
Cоздадим учетную запись почты пользователя "test_user" на компьютере "win12"



 Пользователь "test_user" получил письмо от "mailadmin" и отправляет ответ.
Пользователь "test_user" получил письмо от "mailadmin" и отправляет ответ.

 Почтовый Сервер прекрасно работает. НО для работы в интернете нужны настоящие SSL-сертификаты.
Установка Apache2+PHP8+SSL.
Выполним команду:
# ./adc_install.sh -http
Почтовый Сервер прекрасно работает. НО для работы в интернете нужны настоящие SSL-сертификаты.
Установка Apache2+PHP8+SSL.
Выполним команду:
# ./adc_install.sh -http


 Установка phpMyAdmin.
Выполним команду:
# ./adc_install.sh -madmin
login: root
Password: OpenSUSE15
Установка phpMyAdmin.
Выполним команду:
# ./adc_install.sh -madmin
login: root
Password: OpenSUSE15

 Установка PostfixAdmin.
Выполним команду:
# ./adc_install.sh -padmin
Setup password: OpenSUSE15
Установка PostfixAdmin.
Выполним команду:
# ./adc_install.sh -padmin
Setup password: OpenSUSE15





 Установка Roundcubemail.
Выполним команду:
# ./adc_install.sh -rcube
imap_host = ssl://webmail.dyhap.net:993
smtp_host = ssl://webmail.dyhap.net:465
Любой пользователь домена получает права на пользование Roundcubemail.
Установка Roundcubemail.
Выполним команду:
# ./adc_install.sh -rcube
imap_host = ssl://webmail.dyhap.net:993
smtp_host = ssl://webmail.dyhap.net:465
Любой пользователь домена получает права на пользование Roundcubemail.






 Установка VSFTPd Сервера.
Выполним команду:
# ./adc_install.sh -ftp
Установка VSFTPd Сервера.
Выполним команду:
# ./adc_install.sh -ftp

 VSFTPd Сервер прекрасно работает.
Пользователь "test_user" получил права на пользование VSFTPd Сервером.
VSFTPd Сервер прекрасно работает.
Пользователь "test_user" получил права на пользование VSFTPd Сервером.












 Это базовая установка Сервера.
Ну вот...и всё, конфигурационные файлы известны и теперь вы можете точнее
настроить сервер под свои нужды.
Уточнение: в статье используются самоподписанные сертификаты, при необходимости
их следует заменить на настоящие SSL-сертификаты.
Это базовая установка Сервера.
Ну вот...и всё, конфигурационные файлы известны и теперь вы можете точнее
настроить сервер под свои нужды.
Уточнение: в статье используются самоподписанные сертификаты, при необходимости
их следует заменить на настоящие SSL-сертификаты.
 Попав в командную строку, начинаем подготовку зеркала. Бегло проглядев вывод
команды dmesg, обнаруживаем, что в связи с новым именованием устройств во
FreeBSD-9.0, в нашем случае диски определились как ada0 и ada1. Ну, раз так,
значит так, создадим из них зеркало gm0 и сразу же загрузим его:
# gmirror label gm0 ada0 ada1
# gmirror load
Теперь в системе появился новый диск - gm0. Убедиться в этом можно посмотрев вывод команды:
# ls -la /dev/mirror/gm0
Однако этот диск пока сырой. Поэтому определим для него схему разбиения на
разделы, в нашем случае - GPT и сделаем этот диск загрузочным:
# gpart create -s gpt mirror/gm0
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 mirror/gm0
На этом первая часть вмешательства в обычный ход инсталляции FreeBSD может быть
закончена. В самом деле, зачем людям работать руками, если инсталлятор со всем
остальным может справиться самостоятельно? Поэтому смело набираем exit и
выходим из shell'а, чтобы вернуться в инсталлятор, где нам будет предложено
установить имя хоста и выбрать компоненты дистрибутива.
Далее, когда инсталлятор загрузит редактор разделов, наше программное зеркало
будет ему доступно также, как и два физических диска ada0 и ada1. Теперь после
нашего краткого вмешательства, инсталлятор беспрепятственно позволит создать на
зеркале необходимые разделы. Более того все изменения будут даже динамически
отражаться на обеих половинах зеркала:
Попав в командную строку, начинаем подготовку зеркала. Бегло проглядев вывод
команды dmesg, обнаруживаем, что в связи с новым именованием устройств во
FreeBSD-9.0, в нашем случае диски определились как ada0 и ada1. Ну, раз так,
значит так, создадим из них зеркало gm0 и сразу же загрузим его:
# gmirror label gm0 ada0 ada1
# gmirror load
Теперь в системе появился новый диск - gm0. Убедиться в этом можно посмотрев вывод команды:
# ls -la /dev/mirror/gm0
Однако этот диск пока сырой. Поэтому определим для него схему разбиения на
разделы, в нашем случае - GPT и сделаем этот диск загрузочным:
# gpart create -s gpt mirror/gm0
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 mirror/gm0
На этом первая часть вмешательства в обычный ход инсталляции FreeBSD может быть
закончена. В самом деле, зачем людям работать руками, если инсталлятор со всем
остальным может справиться самостоятельно? Поэтому смело набираем exit и
выходим из shell'а, чтобы вернуться в инсталлятор, где нам будет предложено
установить имя хоста и выбрать компоненты дистрибутива.
Далее, когда инсталлятор загрузит редактор разделов, наше программное зеркало
будет ему доступно также, как и два физических диска ada0 и ada1. Теперь после
нашего краткого вмешательства, инсталлятор беспрепятственно позволит создать на
зеркале необходимые разделы. Более того все изменения будут даже динамически
отражаться на обеих половинах зеркала:
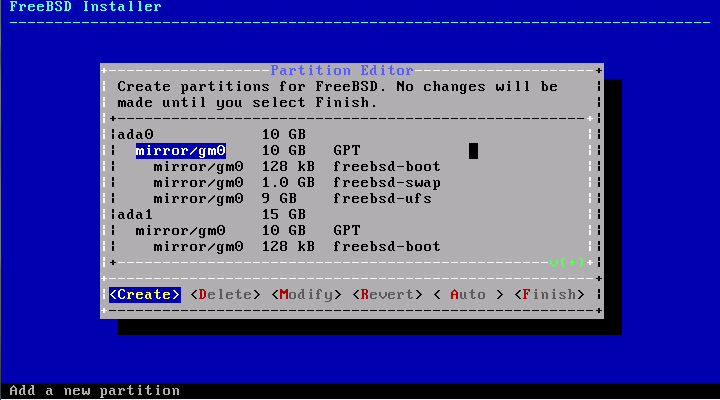 Далее инсталляция пойдет как по маслу в обычном порядке и до своего логического завершения.
Когда все закончится, перезагружаемся проверить все-ли мы сделали правильно, но
здесь нас поджидает небольшой fail. С прискорбием мы обнаруживаем, что система
загрузиться не может: ядро попросту не понимает, что такое gmirror и не видит зеркала.
Выругавшись нехорошими словами, снова вставляем инсталляционный диск и
загружаемся в так полюбившийся нам shell.
Далее загружаем модуль gmirror и, вспомнив, что корневая файловая система
находится на gm0p3, монтируем корень в /mnt.
# gmirror load
# mount /dev/mirror/gm0p3 /mnt
Теперь остается добавить модуль gmirror в loader.conf для загрузки его вместе с
ядром при старте системы:
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
На этом действительно все. Перезагружаемся и получаем работоспособную систему.
Чтобы убедиться в этом, можно безбоязненно проводить тесты по поочередному
отключению дисков.
Единственный нюанс, внимательный администратор заметит во время загрузки
системы настораживающее предупреждение:
gptboot: invalid backup GPT header
Andrey V. Elsukov - один из разработчиков FreeBSD объясняет это предупреждение так:
"Причина понятна - GPT была создана поверх зеркала. Размер провайдера
mirror/gm0 на 1 сектор меньше, чем размер диска, так как gmirror забирает
последний сектор для хранения своих метаданных. Загрузчик gptboot ничего не
знает о программном зеркале и ищет резервный заголовок GPT в конце диска, а там
находятся метаданные gmirror.
Тут есть небольшое разногласие между gptboot и GEOM_PART_GPT. Некоторое время
назад я изменил алгоритм проверки корректности GPT в GEOM_PART_GPT. А именно,
после прочтения основного заголовка GPT и проверки его контрольной суммы,
резервный заголовок считывается по хранящемуся в основном заголовке адресу. В
случае, когда основной заголовок повреждён, резервный заголовок ищется в конце диска."
Как видим из объяснения разработчика, ничего вроде бы страшного не происходит.
И хотя у нас отсутствует запасной заголовок GPT в конце диска, это не критично,
правда до тех пор, пока все работает.
GPT+gmirror
Этот вариант отличает от предыдущего тем, что зеркалируетяс не диск целиком, а
отдельные его разделы. Как и для первого случая, нам потребуется дистрибутив
FreeBSD-9.0R и два жестких диска, установленных в машину. Как и прежде
рекомендуется, чтобы диски были полностью одинаковыми. Тем не менее, если
случилось так, что один диск больше другого, то инсталляцию FreeBSD лучше
проводить на диск меньшего объема. Это поможет избежать лишних расчетов
размеров разделов при зеркалировании их с большего диска на меньший.
В остальном первоначальная установка FreeBSD-9.0R ничем не отличается от
обычной инсталляции по-умолчанию. Вся настройка зеркалирования начинается, в
тот момент, когда мы загружаем свежепроинсталлированную систему и попадаем в консоль.
Как и в предыдущем случае, диски определились как ada0 и ada1. FreeBSD
установлена на меньший по размеру диск - ada0. Первым делом сохраним
разметку диска и восстановим её на другом диске:
# gpart backup ada0 > ada0.gpt
# gpart restore -F /dev/ada1 < ada0.gpt
# gpart show
Далее инсталляция пойдет как по маслу в обычном порядке и до своего логического завершения.
Когда все закончится, перезагружаемся проверить все-ли мы сделали правильно, но
здесь нас поджидает небольшой fail. С прискорбием мы обнаруживаем, что система
загрузиться не может: ядро попросту не понимает, что такое gmirror и не видит зеркала.
Выругавшись нехорошими словами, снова вставляем инсталляционный диск и
загружаемся в так полюбившийся нам shell.
Далее загружаем модуль gmirror и, вспомнив, что корневая файловая система
находится на gm0p3, монтируем корень в /mnt.
# gmirror load
# mount /dev/mirror/gm0p3 /mnt
Теперь остается добавить модуль gmirror в loader.conf для загрузки его вместе с
ядром при старте системы:
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
На этом действительно все. Перезагружаемся и получаем работоспособную систему.
Чтобы убедиться в этом, можно безбоязненно проводить тесты по поочередному
отключению дисков.
Единственный нюанс, внимательный администратор заметит во время загрузки
системы настораживающее предупреждение:
gptboot: invalid backup GPT header
Andrey V. Elsukov - один из разработчиков FreeBSD объясняет это предупреждение так:
"Причина понятна - GPT была создана поверх зеркала. Размер провайдера
mirror/gm0 на 1 сектор меньше, чем размер диска, так как gmirror забирает
последний сектор для хранения своих метаданных. Загрузчик gptboot ничего не
знает о программном зеркале и ищет резервный заголовок GPT в конце диска, а там
находятся метаданные gmirror.
Тут есть небольшое разногласие между gptboot и GEOM_PART_GPT. Некоторое время
назад я изменил алгоритм проверки корректности GPT в GEOM_PART_GPT. А именно,
после прочтения основного заголовка GPT и проверки его контрольной суммы,
резервный заголовок считывается по хранящемуся в основном заголовке адресу. В
случае, когда основной заголовок повреждён, резервный заголовок ищется в конце диска."
Как видим из объяснения разработчика, ничего вроде бы страшного не происходит.
И хотя у нас отсутствует запасной заголовок GPT в конце диска, это не критично,
правда до тех пор, пока все работает.
GPT+gmirror
Этот вариант отличает от предыдущего тем, что зеркалируетяс не диск целиком, а
отдельные его разделы. Как и для первого случая, нам потребуется дистрибутив
FreeBSD-9.0R и два жестких диска, установленных в машину. Как и прежде
рекомендуется, чтобы диски были полностью одинаковыми. Тем не менее, если
случилось так, что один диск больше другого, то инсталляцию FreeBSD лучше
проводить на диск меньшего объема. Это поможет избежать лишних расчетов
размеров разделов при зеркалировании их с большего диска на меньший.
В остальном первоначальная установка FreeBSD-9.0R ничем не отличается от
обычной инсталляции по-умолчанию. Вся настройка зеркалирования начинается, в
тот момент, когда мы загружаем свежепроинсталлированную систему и попадаем в консоль.
Как и в предыдущем случае, диски определились как ada0 и ada1. FreeBSD
установлена на меньший по размеру диск - ada0. Первым делом сохраним
разметку диска и восстановим её на другом диске:
# gpart backup ada0 > ada0.gpt
# gpart restore -F /dev/ada1 < ada0.gpt
# gpart show
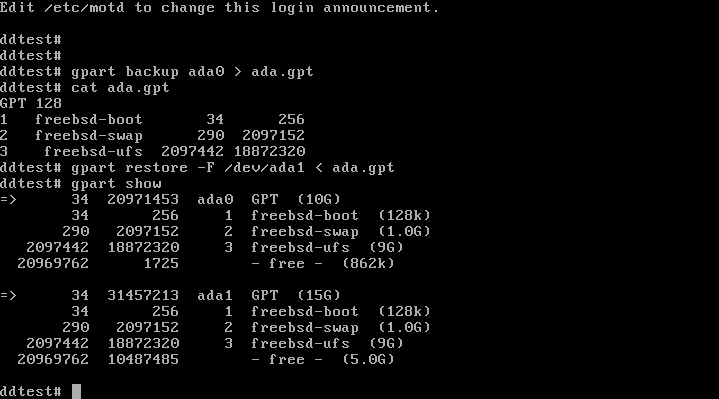 Как видно на скриншоте, разделы удачно скопировались и на бОльшем диске
осталось 5GB свободного неразмеченного места. Теперь по логике вещей, можно
начать зеркалирование разделов.
Однако нужно забыть сделать диск ada1 загрузочным, ведь мы зеркалируем не весь
диск целиком, а только его разделы. Иначе с выходом из строя ada0, система не
сможет загрузится с ada1. Поэтому:
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 ada1
Кроме того, раздел /dev/da0p3 - содержит корневую файловую систему, он
смонтирован, и размонтировать его не получится, поэтому в текущем положении
изменить его не возможно.
Поэтому перезагружаем систему и загружаемся с инсталляционного диска, где
привычно уже заходим в shell и на каждом разделе диска ada0 создаем зеркало и
загружаем его:
# gmirror label -vb round-robin boot /dev/ada0p1
# gmirror label -vb round-robin swap /dev/ada0p2
# gmirror label -vb round-robin root /dev/ada0p3
# gmirror load
Итого у нас получаютcя 3 зеркала. Сразу же добавляем к зеркалам по их второй половине:
# gmirror insert boot /dev/ada1p1
# gmirror insert swap /dev/ada1p2
# gmirror insert root /dev/ada1p3
Начнется процедура зеркалирования, длительность которой зависит от объема
данных и характеристик жестких дисков. Наблюдать за этим увлекательным
процессом можно при помощи команды:
# gmirror status
А пока дожидаемся окончания этого процесса, чтобы зря не терять времени, можно
не спеша сделать еще 2 полезные вещи. Первая, добавить модуль gmirror в
загрузку ядра:
# mount /dev/mirror/root /mnt
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
И вторая, отредактировать fstab в соответствии с измененными под зеркала именами разделов:
# cat /mnt/etc/fstab
#Device Mountpoint FStype Options Dump Pass#
/dev/mirror/swap none swap sw 0 0
/dev/mirror/root / ufs rw 1 1
На этом все. После окончания синхронизации зеркал, можно перезагрузиться и
устроить системе тест, отключая то один диск, то другой. Только главное не
увлечься и не забыть, что каждый раз, при возвращении диска в RAID, нужно
обязательно дожидаться окончания процесса синхронизации, иначе вы потеряете данные.
Как видно на скриншоте, разделы удачно скопировались и на бОльшем диске
осталось 5GB свободного неразмеченного места. Теперь по логике вещей, можно
начать зеркалирование разделов.
Однако нужно забыть сделать диск ada1 загрузочным, ведь мы зеркалируем не весь
диск целиком, а только его разделы. Иначе с выходом из строя ada0, система не
сможет загрузится с ada1. Поэтому:
# gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 ada1
Кроме того, раздел /dev/da0p3 - содержит корневую файловую систему, он
смонтирован, и размонтировать его не получится, поэтому в текущем положении
изменить его не возможно.
Поэтому перезагружаем систему и загружаемся с инсталляционного диска, где
привычно уже заходим в shell и на каждом разделе диска ada0 создаем зеркало и
загружаем его:
# gmirror label -vb round-robin boot /dev/ada0p1
# gmirror label -vb round-robin swap /dev/ada0p2
# gmirror label -vb round-robin root /dev/ada0p3
# gmirror load
Итого у нас получаютcя 3 зеркала. Сразу же добавляем к зеркалам по их второй половине:
# gmirror insert boot /dev/ada1p1
# gmirror insert swap /dev/ada1p2
# gmirror insert root /dev/ada1p3
Начнется процедура зеркалирования, длительность которой зависит от объема
данных и характеристик жестких дисков. Наблюдать за этим увлекательным
процессом можно при помощи команды:
# gmirror status
А пока дожидаемся окончания этого процесса, чтобы зря не терять времени, можно
не спеша сделать еще 2 полезные вещи. Первая, добавить модуль gmirror в
загрузку ядра:
# mount /dev/mirror/root /mnt
# echo ‘geom_mirror_load="YES"’ > /mnt/boot/loader.conf
И вторая, отредактировать fstab в соответствии с измененными под зеркала именами разделов:
# cat /mnt/etc/fstab
#Device Mountpoint FStype Options Dump Pass#
/dev/mirror/swap none swap sw 0 0
/dev/mirror/root / ufs rw 1 1
На этом все. После окончания синхронизации зеркал, можно перезагрузиться и
устроить системе тест, отключая то один диск, то другой. Только главное не
увлечься и не забыть, что каждый раз, при возвращении диска в RAID, нужно
обязательно дожидаться окончания процесса синхронизации, иначе вы потеряете данные.
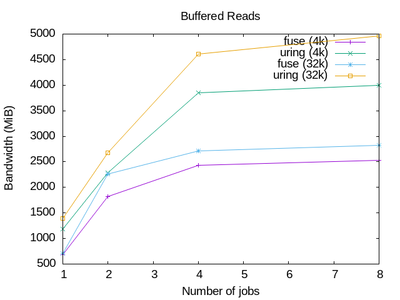
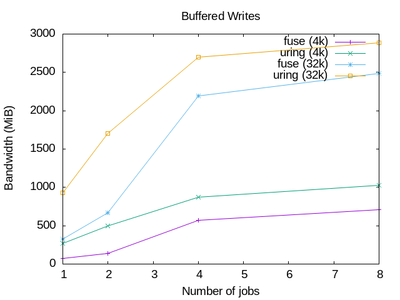
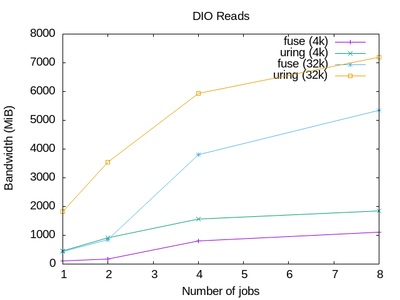
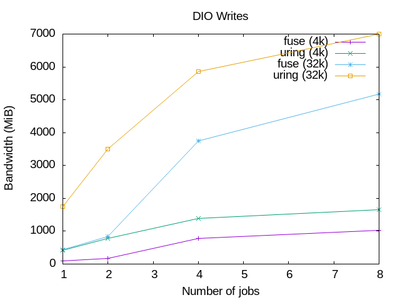
 Такие звуковушки лежат почти в каждом магазине по 200 рублей. О думаю, а что
если китайцы + кнопки и это клавиатура? Дай-те ко мне одну?
Реализация: Купил, подключил к headless q190 и стал смотреть вывод
$ lsusb
Bus 001 Device 005: ID 0d8c:013c C-Media Electronics, Inc. CM108 Audio Controller
Печально, думаю, но решил посмотреть, что ещё и в dmesg нашлось?
hid-generic 0003:0D8C:013C.0002: input,hidraw0: USB HID v1.00 Device [C-Media Electronics Inc. USB PnP Sound Device] on usb-0000:00:1a.0-1.4/input3
О, то что нужно. Отлично!
Кнопки звуковой карты - это по сути маленькая USB клавиатура. То что мне нужно.
Для обработки нажатий воспользуемся THD (Triggerhappy
- lightweight hotkey daemon)
Такие звуковушки лежат почти в каждом магазине по 200 рублей. О думаю, а что
если китайцы + кнопки и это клавиатура? Дай-те ко мне одну?
Реализация: Купил, подключил к headless q190 и стал смотреть вывод
$ lsusb
Bus 001 Device 005: ID 0d8c:013c C-Media Electronics, Inc. CM108 Audio Controller
Печально, думаю, но решил посмотреть, что ещё и в dmesg нашлось?
hid-generic 0003:0D8C:013C.0002: input,hidraw0: USB HID v1.00 Device [C-Media Electronics Inc. USB PnP Sound Device] on usb-0000:00:1a.0-1.4/input3
О, то что нужно. Отлично!
Кнопки звуковой карты - это по сути маленькая USB клавиатура. То что мне нужно.
Для обработки нажатий воспользуемся THD (Triggerhappy
- lightweight hotkey daemon)  (
( (
( (
( (
( Создаем "Graph", который нам нарисует "Item"
Создаем "Graph", который нам нарисует "Item"
 Результат:
Результат:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
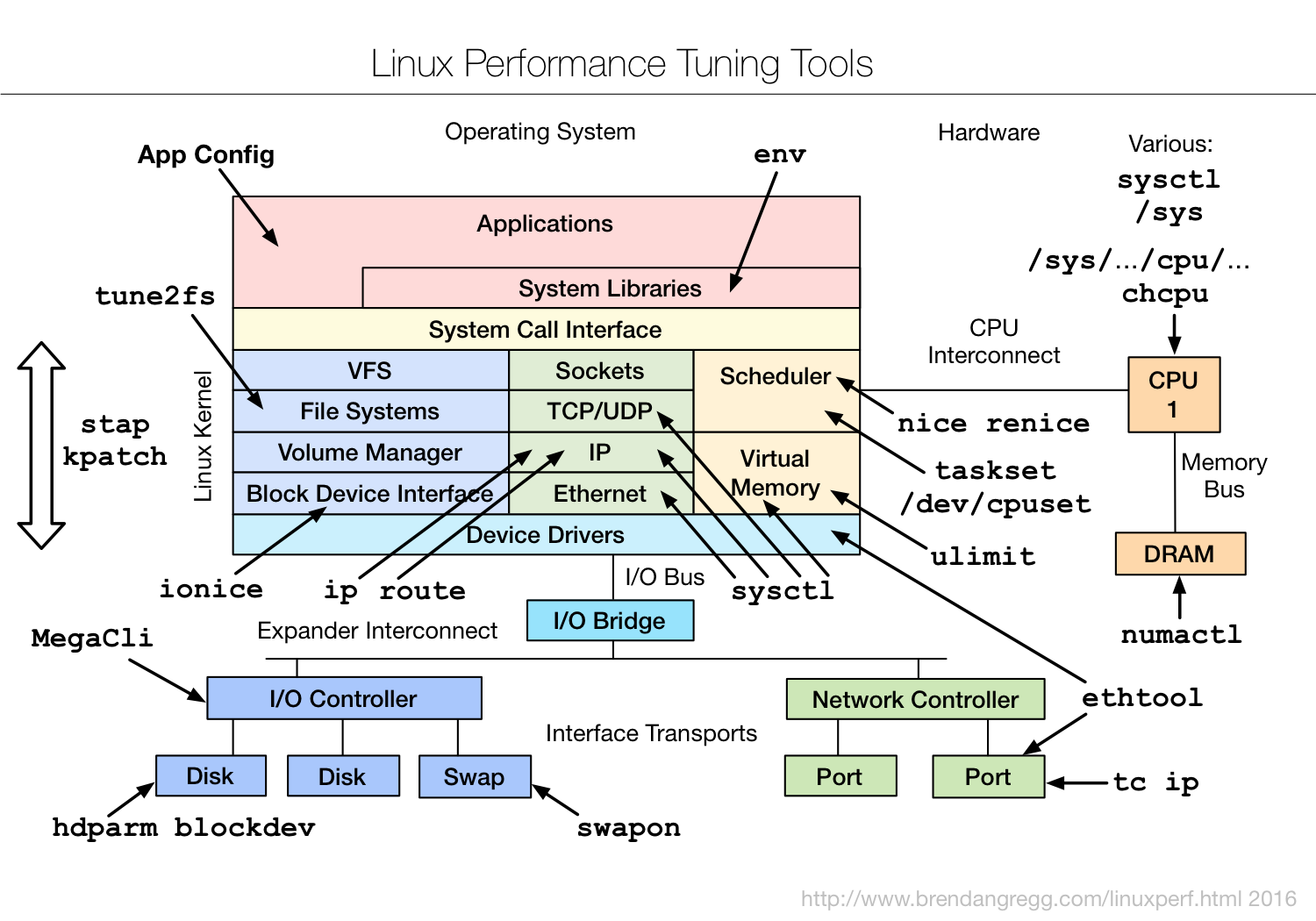{kind=link}
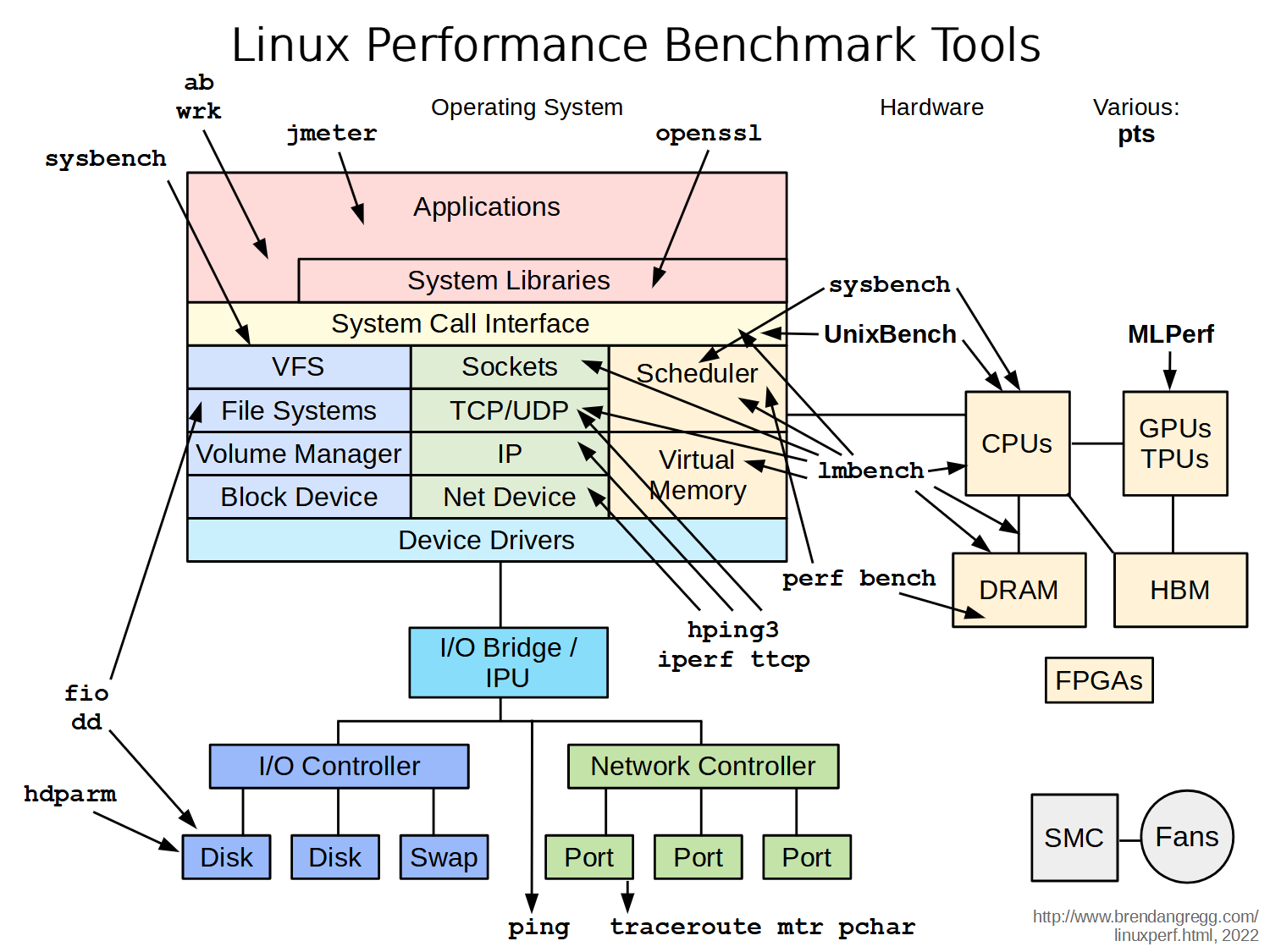{kind=link}
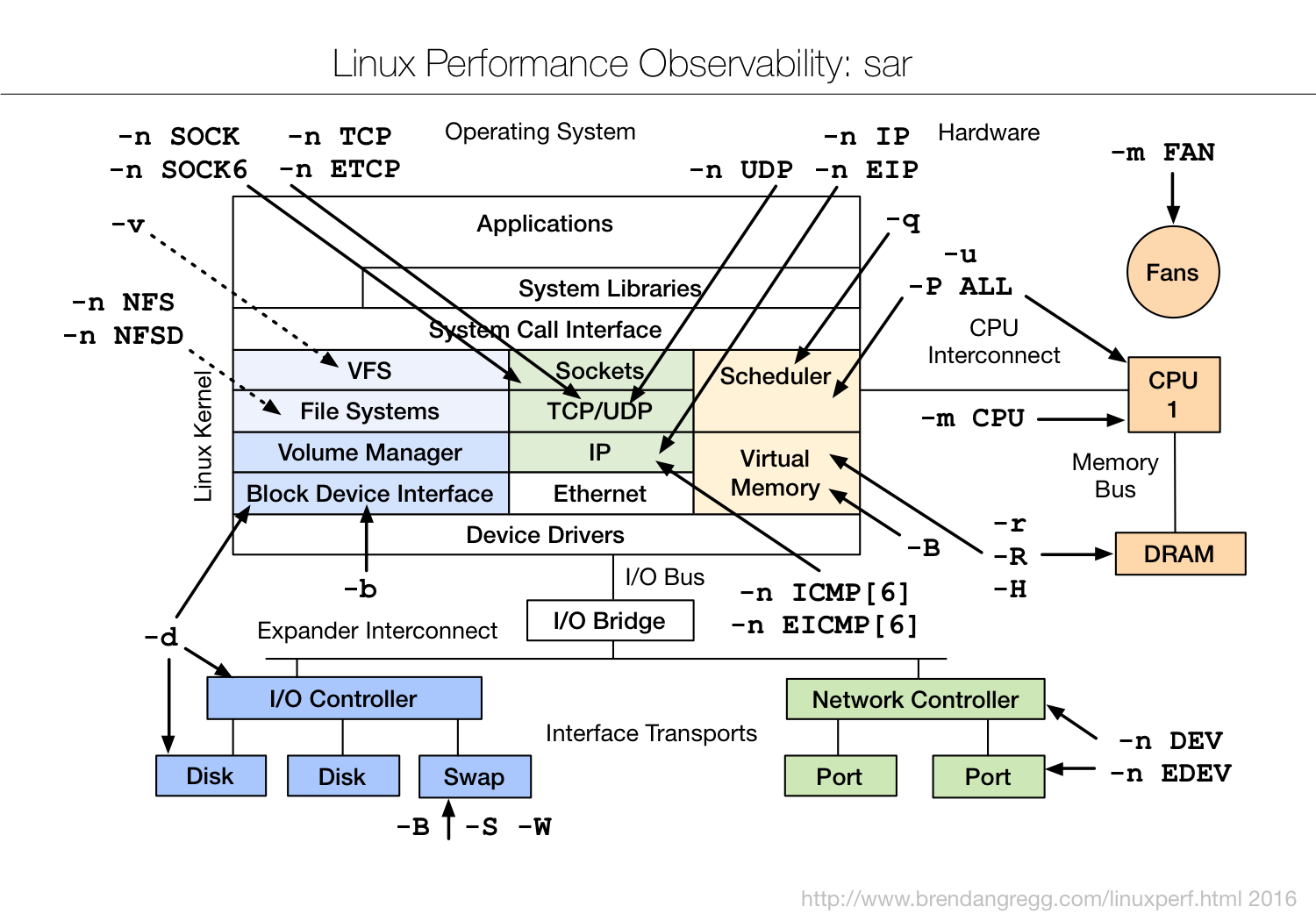{kind=link}